

Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого...

Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
Общие условия выбора системы дренажа: Система дренажа выбирается в зависимости от характера защищаемого...
Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
Топ:
Генеалогическое древо Султанов Османской империи: Османские правители, вначале, будучи еще бейлербеями Анатолии, женились на дочерях византийских императоров...
Основы обеспечения единства измерений: Обеспечение единства измерений - деятельность метрологических служб, направленная на достижение...
Интересное:
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Искусственное повышение поверхности территории: Варианты искусственного повышения поверхности территории необходимо выбирать на основе анализа следующих характеристик защищаемой территории...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Не любые два набора точек в RN разделяются гиперплоскостью, а значит, могут быть корректно классифицированы с помощью линейной решающей функции. Это является платой за простоту и вычислительную эффективность линейных методов. Нелинейные методы сложны и вычислительно трудоемки. К счастью, существует стандартный прием, позволяющий расширять процедуры построения линейных решающих функций на нелинейные функции. Этот прием заключается в том, что вводятся обобщенные решающие функции вида
κ (x, w)= w 1 f 1(x)+ w 2 f 2(x)+…+ w n f n(x), fi (x): RN → R (3)
В частности, несложно получить линейные решающие функции, используя N = n +1 и  .
.
Функции fi (x) предполагаются известными заранее, то есть имеется возможность однозначно получить их значения для любого вектора x. Тогда решающие функции вида (3) оказываются линейными по неизвестным параметрам wi, и несложно убедиться, что любой метод, предназначенный для нахождения параметров линейных решающих функций, также будет работать и для обобщенных решающих функций. Один из стандартных способов задания обобщенных решающих функций – это представление их в виде многочленов (обычно используются ортонормированные системы функций, например, многочлены Лежандра или Эрмита). По сути, это означает, что для любой непрерывной (в некотором замкнутом интервале) решающей функции существует последовательность обобщенных решающих функций, равномерно сходящихся (на этом интервале) к ней. Это справедливо согласно теореме Вейерштрасса о приближении функций. Итак, если не ограничивать количество n слагаемых в разложении (3), то можно описать любую (непрерывную) решающую функцию. Также несложно убедиться, что, если в состав различных классов не входят идентичные векторы образов, то всегда можно найти разделяющие границы.
|
|
Интересно также отметить, что использование функций вида (3) равносильно использованию нового пространства описаний Rn с признаками χi = fi (x), i =1,..., n. Во-первых, это говорит нам, что выбор подходящих признаков может сделать классы линейно разделимыми, а задачу распознавания достаточно простой. Во-вторых, привлечение обобщенных решающих функций задачу выбора признаков не решает, так как функции fi (x) задаются априорно, а не строятся автоматически.
В то же время, использование в качестве новых признаков некоторой полной системы функций позволяет разделять любые классы образов, но при этом может быть порождено потенциально бесконечное число новых признаков. С точки зрения машинного обучения, этот результат вызывает определенные сомнения. Действительно, человек стремится использовать минимально необходимое число признаков, с помощью которых он описывает те или иные классы объектов. Казалось бы, аппроксимация истинной решающей функции многочленами (или другой полной системой функций) математически корректна. В чем же тут проблема? Почему возникает впечатление, что такой подход может дать плохой результат? Чтобы ответить на этот вопрос, обратимся к рис. 2.

Рис. 2. Использование обобщенных решающих функций для разделения двух классов:
а) на основе признаков: 1, x 1, x 2, x 1 x 2;
б) на основе 25 новых признаков;
в) на основе 36 новых признаков;
г) на основе 36 новых признаков, но один из векторов обучающей выборки при построении решающего правила не использован.
Как видно из рис. 2а, использование лишь одного дополнительного признака f 4(x) = x 1 x 2 приводит к неверной классификации двух признаков обучающей выборки. При использовании расширенного вектора из двадцати пяти признаков (рис. 2б) также неверно, но с меньшей ошибкой, классифицируются два образа обучающей выборки. При этом видно, что решающее правило таково, что образы имеют тенденцию располагаться вблизи границ областей.
|
|
Использование тридцати шести новых признаков дает верную классификацию всех образов обучающей выборки (рис. 2в), однако построенные области интуитивно воспринимаются плохими. Чтобы понять, в чем здесь дело, достаточно построить решающее правило по обучающей выборке, из которой исключен один из векторов. Результат такой операции представлен на рис. 2г. Исключенный образ (правый нижний треугольник на рисунке) полученным решающим правилом классифицируется неверно.
Итак, построение обобщенного вектора признаков большой размерности действительно позволяет классифицировать правильно все образы обучающей выборки, однако полученное в результате решающее правило очень плохо предсказывает классы тех образов, которые в обучающую выборку не вошли. Это типичный пример эффекта, получившего название переобучение, чрезмерно близкая подгонка или потеря обобщающей способности. Наша обучающая система очень хорошо «вызубрила» обучающие примеры, но не осуществила их обобщения, которое и составляет суть обучения.
Таким образом, хотя обобщенные решающие функции существенно расширяют возможности линейных решающих функций, они вовсе не дают окончательного решения проблемы распознавания. Поскольку в качестве примера критерия выбора разделяющей гиперплоскости был приведен метод опорных векторов, нельзя не сказать про другую возможность расширения линейных методов. Если в методе опорных векторов использовать тот же прием, что и в методе обобщенных решающих функций, и поменять все векторы xi на обобщенные векторы признаков χi =(χi, 1, χi ,2,…, χi , n), где χi , k = fk (xi), то решающая функция будет задаваться через скалярные произведения  вместо
вместо 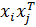 . Пусть F (x)=(f 1(x),…, fn (x)), тогда
. Пусть F (x)=(f 1(x),…, fn (x)), тогда  , где через
, где через  обозначено скалярное произведение функций с векторными значениями.
обозначено скалярное произведение функций с векторными значениями.
Далее введем функцию  , называемую ядром. Таким образом, в методе опорных векторов при использовании обобщенных признаков решающая функция зависит не от самих признаков fi(x), а только от их попарных скалярных произведений – ядер
, называемую ядром. Таким образом, в методе опорных векторов при использовании обобщенных признаков решающая функция зависит не от самих признаков fi(x), а только от их попарных скалярных произведений – ядер  . Интересны они тем, что позволяют вместо признаков F: RN → Rn с числовыми значениями использовать признаки F: RN → L 2(Rn)с, значениями которых являются функции (пространство L 2, лебегово пространство измеримых функций, используется для того, чтобы можно было вычислить скалярное произведение двух функций
. Интересны они тем, что позволяют вместо признаков F: RN → Rn с числовыми значениями использовать признаки F: RN → L 2(Rn)с, значениями которых являются функции (пространство L 2, лебегово пространство измеримых функций, используется для того, чтобы можно было вычислить скалярное произведение двух функций  ). Это позволяет легко добиваться линейной разделимости любых обучающих совокупностей при достаточно простых ядрах.
). Это позволяет легко добиваться линейной разделимости любых обучающих совокупностей при достаточно простых ядрах.
|
|
К сожалению, хотя использование ядер имеет ряд преимуществ перед явным заданием признаков fi (x), здесь остается как необходимость задавать эти ядра априори, так и проблема переобучения. Причем последняя проблема становится даже более острой, так как использование ядер не позволяют применять стандартные методы уменьшения размерности. Именно поэтому здесь применяются системы штрафов за ошибки классификации на обучающих примерах и за количество опорных векторов. Однако из идеи опорных векторов корректная и обоснованная система штрафов никак не следует.
Библиотека LIBSVM
Скачать библиотеку LIBSVM можно со страницы http://www.csie.ntu. edu.tw/~cjlin/libsvm.
Она написана на языке C++, но имеется также версия на Java. В дистрибутив входит обертка svm.py для вызова из программ на Python. Чтобы ею воспользоваться, необходима версия LIBSVM, откомпилированная под вашу платформу. Для Windows в дистрибутиве имеется готовая DLL – svmc.dll. (Для версии Python 2.5 этот файл нужно переименовать в svmc.pyd, так как она не умеет импортировать библиотеки с расширением DLL.) В документации, поставляемой вместе с LIBSVM, описывается, как откомпилировать ее на других платформах.
Пример сеанса для Python
Поместите откомпилированную версию LIBSVM и пакет svm.py в свою рабочую папку или в папку, где интерпретатор Python ищет библиотеки. Теперь можно импортировать ее и использовать.
>>> from svm import *
Первым делом создадим простой набор данных. LIBSVM читает данные из кортежа, содержащего два списка. Первый список содержит классы, второй – исходные данные. Попробуем создать набор данных всего с двумя классами:
>>> prob = svm_problem([1,-1],[[1,0,1],[-1,0,-1]])
Еще нужно с помощью функции svm_parameter задать ядро, которым вы собираетесь пользоваться:
>>> param = svm_parameter(kernel_type = LINEAR, C = 10) Далее следует обучить модель: >>> m = svm_model(prob, param)
optimization finished, #iter = 1 nu = 0.025000
ob] = -0.250000, rho = 0.000000 nSV = 2, nBSV = 0 Total nSV = 2
И наконец воспользуемся ею для прогнозирования принадлежности классам:
|
|
>>> m.predict([1, 1, 1])
1.0
Это вся функциональность LIBSVM, которая вам нужна для создания модели по обучающим данным и последующей классификации.
У библиотеки LIBSVM есть еще одна полезная особенность – возможность сохранять и загружать обученные модели:
>>> m.save(test.model) >>> m=svm_model(test.model)
Содержание отчета
Отчет должен содержать:
1. Постановку задачи.
2. Графическое отображение выборки.
3. Таблицу с результатами классификации с использованием различных ядер. Результаты классификации отобразить графически.
4. Оценки обобщающей способности классификатора.
5. Выводы. В выводах необходимо проанализировать, при использовании какого из ядер результаты классификации точнее и почему (как это связано с пространством информативных признаков), оценить компактность расположения точек на графике, возможность их линейной разделимости, оценить влияние этой возможности на работу классификатора с различными ядрами.
6. Приложение к отчету.
В приложении к Отчету необходимо дать описание требований к комплектации ЭВМ и шагов, необходимых для установки и запуска программы, а также листинг программы.
Отчет должен быть подготовлен в печатном виде и содержать иллюстрации работы программы.
В электронном виде нужно представить:
1. Электронную версию отчета по лабораторной работе.
2. Результирующую программу (exe-файл), необходимые для ее работы рабочие материалы (базу данных наблюдений).
3. Файл READ ME (описание шагов, необходимых для установки и запуска программы на компьютере).
Работающая программа (exe-файл) должна запускаться на компьютере со стандартным программным обеспечением и не требовать специальных усилий для своей работы (установки на компьютере специального языка программирования, размещения компонентов программы на сервере, прописывания пути к БЗ в командных строках и т.д.).
Лабораторная робота №3
Тема: построение наивного байесовкого классификатора.
Цель: научиться строить модель наивного байесовского классификатора и осуществлять оценку ее параметров методом максимального правдоподобия. Построение классификатора по вероятностной модели, приобрести практические навыки использования наивного байесовского классификатора для задач классификации.
Порядок выполнения работы
1. Разработать программу, реализующую байесовскую классификацию.
2. Протестировать и отладить работу программы на различных обучающих данных. Для чего необходимо выполнить следующее:
a. зайти на страницу с массивами баз данных для отладки алгоритмов машинного обучения https://archive.ics.uci.edu/ml/machine-learning-databases/?C=N;O=D;
b. выбрать любую базу и ознакомиться с ее описательной частью для формирования классов и вектора признаков;
|
|
c. используя выбранную базу, сформировать обучающую и контрольную выборки.
3. Оформить отчет по лабораторной работе.
|
|
|

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...

Поперечные профили набережных и береговой полосы: На городских территориях берегоукрепление проектируют с учетом технических и экономических требований, но особое значение придают эстетическим...

История развития пистолетов-пулеметов: Предпосылкой для возникновения пистолетов-пулеметов послужила давняя тенденция тяготения винтовок...

Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!