

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...
Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...
Топ:
Характеристика АТП и сварочно-жестяницкого участка: Транспорт в настоящее время является одной из важнейших отраслей народного...
Генеалогическое древо Султанов Османской империи: Османские правители, вначале, будучи еще бейлербеями Анатолии, женились на дочерях византийских императоров...
Проблема типологии научных революций: Глобальные научные революции и типы научной рациональности...
Интересное:
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Инженерная защита территорий, зданий и сооружений от опасных геологических процессов: Изучение оползневых явлений, оценка устойчивости склонов и проектирование противооползневых сооружений — актуальнейшие задачи, стоящие перед отечественными...
Дисциплины:
|
из
5.00
|
Заказать работу |
Лекция 1: Архитектура
Введение
Premature optimization is the root of all evil.
Donald Knuth
Эта книга ориентирована на программистов, которые уже знают Си на достаточном уровне. Почему так? Вряд ли, зная только несколько интерпретируемых языков вроде Perl или Python, кто-то захочет сразу изучать ассемблер. Используя Си и ассемблер вместе, применяя каждый язык для определённых целей, можно добиться очень хороших результатов. К тому же программисты Си уже имеют некоторые знания об архитектуре процессора, особенностях машинных вычислений, способе организации памяти и других вещах, которые новичку в программировании понять не так просто. Поэтому изучать ассемблер после Си несомненно легче, чем после других языков высокого уровня. В Си есть понятие "указатель", программист должен сам управлять выделением памяти в куче, и так далее - все эти знания пригодятся при изучении ассемблера, они помогут получить более целостную картину об архитектуре, а также иметь более полное представление о том, как выполняются их программы на Си. Но эти знания требуют углубления и структурирования.
Хочу подчеркнуть, что для чтения этой книги никаких знаний о Linux не требуется (кроме, разумеется, знаний о том, "как создать текстовый файл" и "как запустить программу в консоли"). Да и вообще, единственное, в чём выражается ориентированность на Linux, - это используемые синтаксис ассемблера и ABI. Программисты на ассемблере в DOS и Windows используют синтаксис Intel, но в системах *nix принято использовать синтаксис AT&T. Именно синтаксисом AT&T написаны ассемблерные части ядра Linux, в синтаксисе AT&T компилятор GCC выводит ассемблерные листинги и так далее.
Большую часть информации из этой книги можно использовать для программирования не только в *nix, но и в Windows, нужно только уточнить некоторые системно-зависимые особенности (например, ABI).
А стоит ли?
При написании кода на ассемблере всегда следует отдавать себе отчёт в том, действительно ли данный кусок кода должен быть написан на ассемблере. Нужно взвесить все "за" и "против", современные компиляторы умеют оптимизировать код, и могут добиться сравнимой производительности (в том числе большей, если ассемблерная версия написанная программистом изначально неоптимальна).
Самый главный недостаток языка ассемблера - будущая непереносимость полученной программы на другие платформы.
X86 или IA-32?
Вы, вероятно, уже слышали такое понятие, как " архитектура x86 ". Вообще оно довольно размыто, и вот почему. Само название x86 или 80x86 происходит от принципа, по которому Intel давала названия своим процессорам:
· Intel 8086 - 16 бит;
· Intel 80186 - 16 бит;
· Intel 80286 - 16 бит;
· Intel 80386 - 32 бита;
· Intel 80486 - 32 бита.
Этот список можно продолжить. Принцип наименования, где каждому поколению процессоров давалось имя, заканчивающееся на 86, создал термин " x86 ". Но, если посмотреть внимательнее, можно увидеть, что "процессором x86 " можно назвать и древний 16-битный 8086, и новый i7. Поэтому 32-битные расширения были названы архитектурой IA-32 (сокращение от Intel Architecture, 32-bit). Конечно же, возможность запуска 16-битных программ осталась, и она успешно (и не очень) используется в 32-битных версиях Windows. Мы будем рассматривать только 32-битный режим.
.data /* поместить следующее в сегмент данных
*/
hello_str: /* наша строка */
.string "Hello, world!\n"
/* длина строки */
.set hello_str_length,. - hello_str - 1
.text /* поместить следующее в сегмент кода */
.globl main /* main - глобальный символ, видимый
за пределами текущего файла */
.type main, @function /* main - функция (а не данные) */
main:
movl $4, %eax /* поместить номер системного вызова
write = 4 в регистр %eax */
movl $1, %ebx /* первый параметр - в регистр %ebx;
номер файлового дескриптора
stdout - 1 */
movl $hello_str, %ecx /* второй параметр - в регистр %ecx;
указатель на строку */
movl $hello_str_length, %edx /* третий параметр - в регистр
%edx; длина строки */
int $0x80 /* вызвать прерывание 0x80 */
movl $1, %eax /* номер системного вызова exit - 1 */
movl $0, %ebx /* передать 0 как значение параметра */
int $0x80 /* вызвать exit(0) */
.size main,. - main /* размер функции main */
Регистры
Регистр - это небольшой объем очень быстрой памяти, размещённой на процессоре. Он предназначен для хранения результатов промежуточных вычислений, а также некоторой информации для управления работой процессора. Так как регистры размещены непосредственно на процессоре, доступ к данным, хранящимся в них, намного быстрее доступа к данным в оперативной памяти.
Все регистры можно разделить на две группы: пользовательские и системные. Пользовательские регистры используются при написании "обычных" программ. В их число входят основные программные регистры (англ. basic program execution registers; все они перечислены ниже), а также регистры математического сопроцессора, регистры MMX, XMM (SSE, SSE2, SSE3). Системные регистры (регистры управления, регистры управления памятью, регистры отладки, машинно-специфичные регистры MSR и другие) здесь не рассматриваются. Более подробно см.(Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 1: Basic Architecture, 3.2 Overview of the basic execution environment.
Регистры общего назначения (РОН, англ. General Purpose Registers, сокращённо GPR). Размер - 32 бита.
· %eax: Accumulator register - аккумулятор, применяется для хранения результатов промежуточных вычислений.
· %ebx: Base register - базовый регистр, применяется для хранения адреса (указателя) на некоторый объект в памяти.
· %ecx: Counter register - счетчик, его неявно используют некоторые команды для организации циклов (см. loop).
· %edx: Data register - регистр данных, используется для хранения результатов промежуточных вычислений и ввода-вывода.
· %esp: Stack pointer register - указатель стека. Содержит адрес вершины стека.
· %ebp: Base pointer register - указатель базы кадра стека (англ. stack frame). Предназначен для организации произвольного доступа к данным внутри стека.
· %esi: Source index register - индекс источника, в цепочечных операциях содержит указатель на текущий элемент-источник.
· %edi: Destination index register - индекс приёмника, в цепочечных операциях содержит указатель на текущий элемент-приёмник.
Эти регистры можно использовать "по частям". Например, к младшим 16 битам регистра %eax можно обратиться как %ax. А %ax, в свою очередь, содержит две однобайтовых половинки, которые могут использоваться как самостоятельные регистры: старший %ah и младший %al. Аналогично можно обращаться к %ebx/%bx/%bh/%bl, %ecx/%cx/%ch/%cl,%edx/%dx/%dh/%dl, %esi/%si, %edi/%di.
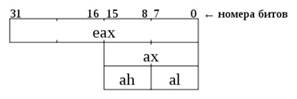
Не следует бояться такого жёсткого закрепления назначения использования регистров. Большая их часть может использоваться для хранения совершенно произвольных данных. Единственный случай, когда нужно учитывать, в какой регистр помещать данные - использование неявно обращающихся к регистрам команд. Такое поведение всегда чётко документировано.
Сегментные регистры:
· %cs: Code segment - описывает текущий сегмент кода.
· %ds: Data segment - описывает текущий сегмент данных.
· %ss: Stack segment - описывает текущий сегмент стека.
· %es: Extra segment - дополнительный сегмент, используется неявно в строковых командах как сегмент-получатель.
· %fs: F segment - дополнительный сегментный регистр без специального назначения.
· %gs: G segment - дополнительный сегментный регистр без специального назначения.
В ОС Linux используется плоская модель памяти (flat memory model), в которой все сегменты описаны как использующие всё адресное пространство процессора и, как правило, явно не используются, а все адреса представлены в виде 32-битных смещений. В большинстве случаев программисту можно даже и не задумываться об их существовании, однако операционная система предоставляет специальные средства (системный вызов modify_ldt()), позволяющие описывать нестандартные сегменты и работать с ними. Однако такая потребность возникает редко, поэтому тут подробно не рассматривается.
Регистр флагов eflags и его младшие 16 бит, регистр flags. Содержит информацию о состоянии выполнения программы, о самом микропроцессоре, а также информацию, управляющую работой некоторых команд. Регистр флагов нужно рассматривать как массив битов, за каждым из которых закреплено определённое значение. Регистр флагов напрямую не доступен пользовательским программам; изменение некоторых битов eflags требует привилегий. Ниже перечислены наиболее важные флаги.
· cf: carry flag, флаг переноса:
o 1 - во время арифметической операции был произведён перенос из старшего бита результата;
o 0 - переноса не было;
· zf: zero flag, флаг нуля:
o 1 - результат последней операции нулевой;
o 0 - результат последней операции ненулевой;
· of: overflow flag, флаг переполнения:
o 1 - во время арифметической операции произошёл перенос в/из старшего (знакового) бита результата;
o 0 - переноса не было;
· df: direction flag, флаг направления. Указывает направление просмотра в строковых операциях:
o 1 - направление "назад", от старших адресов к младшим;
o 0 - направление "вперёд", от младших адресов к старшим.
Есть команды, которые устанавливают флаги согласно результатам своей работы: в основном это команды, которые что-то вычисляют или сравнивают. Есть команды, которые читают флаги и на основании флагов принимают решения. Есть команды, логика выполнения которых зависит от состояния флагов. В общем, через флаги между командами неявно передаётся дополнительная информация, которая не записывается непосредственно в результат вычислений.
Указатель команды eip (instruction pointer). Размер - 32 бита. Содержит указатель на следующую команду. Регистр напрямую недоступен, изменяется неявно командами условных и безусловных переходов, вызова и возврата из подпрограмм.
Стек
Мы полагаем, что читатель имеет опыт программирования на Си и знаком со структурами данных типа стек. В микропроцессоре стек работает похожим образом: это область памяти, у которой определена вершина (на неё указывает %esp). Поместить новый элемент можно только на вершину стека, при этом новый элемент становится вершиной. Достать из стека можно только верхний элемент, при этом вершиной становится следующий элемент. У вас наверняка была в детстве игрушка-пирамидка, где нужно было разноцветные кольца надевать на общий стержень. Так вот, эта пирамидка - отличный пример стека. Также можно провести аналогию с составленными стопкой тарелками. На разных архитектурах стек может "расти" как в сторону младших адресов (принцип описан ниже, подходит для x86), так и старших.

Стек растёт в сторону младших адресов. Это значит, что последний записанный в стек элемент будет расположен по адресу младше остальных элементов стека.
При помещении нового элемента в стек происходит следующее (принцип работы команды push):
· значение %esp уменьшается на размер элемента в байтах (4 или 2);
· новый элемент записывается по адресу, на который указывает %esp.

При выталкивании элемента из стека эти действия совершаются в обратном порядке(принцип работы команды pop):
· содержимое памяти по адресу, который записан в %esp, записывается в регистр;
· а значение адреса в %esp увеличивается на размер элемента в байтах (4 или 2).

Память
В Си после вызова malloc(3) программе выделяется блок памяти, и к нему можно получить доступ при помощи указателя, содержащего адрес этого блока. В ассемблере то же самое: после того, как программе выделили блок памяти, появляется возможность использовать указывающий на неё адрес для всевозможных манипуляций. Наименьший по размеру элемент памяти, на который может указать адрес, - байт. Говорят, что память адресуется побайтово, или гранулярность адресации памяти - один байт. Отдельный бит можно указать как адрес байта, содержащего этот бит, и номер этого бита в байте.
Правда, нужно отметить ещё одну деталь. Программный код расположен в памяти, поэтому получить его адрес также возможно. Стек - это тоже блок памяти, и разработчик может получить указатель на любой элемент стека, находящийся под вершиной. Таким образом организовывают доступ к произвольным элементам стека.
См. также
· Статья "Endianness" в en.wikipedia.org
· Статья "Порядок байтов" в ru.wikipedia.org
Лекция 2: Hello, world!
При изучении нового языка принято писать самой первой программу, выводящую на экран строку Hello, world!. Сейчас мы не ставим перед собой задачу понять всё написанное. Главное - посмотреть, как оформляются программы на ассемблере, и научиться их компилировать.
Вспомним, как вы писали Hello, world! на Си. Скорее всего, приблизительно так:

Вот только printf(3) - функция стандартной библиотеки Си, а не операционной системы. "Чем это плохо?" - спросите вы. Да, в общем, всё нормально, но, читая этот учебник, вы, вероятно, хотите узнать, что происходит "за кулисами" функций стандартной библиотеки на уровне взаимодействия с операционной системой. Это, конечно же, не значит, что из ассемблера нельзя вызывать функции библиотеки Си. Просто мы пойдём более низкоуровневым путём.
Как вы уже, наверное, знаете, стандартный вывод (stdout), в который выводит данные printf(3), является обычным файловым дескриптором, заранее открываемый операционной системой. Номер этого дескриптора - 1. Теперь нам на помощь придёт системный вызов write(2).
WRITE(2) Руководство программиста Linux WRITE(2)
ИМЯ
write - писать в файловый дескриптор
ОБЗОР
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
ОПИСАНИЕ
write пишет count байт в файл, на который ссылается файловый
дескриптор fd, из буфера, на который указывает buf.
А вот и сама программа:

Почему sizeof(str) - 1? Потому, что строка в Си заканчивается нулевым байтом, а его нам печатать не нужно.
Теперь скопируйте следующий текст в файл hello.s. Файлы исходного кода на ассемблере имеют расширение.s.
.data /* поместить следующее в сегмент данных
*/
hello_str: /* наша строка */
.string "Hello, world!\n"
/* длина строки */
.set hello_str_length,. - hello_str - 1
.text /* поместить следующее в сегмент кода */
.globl main /* main - глобальный символ, видимый
за пределами текущего файла */
.type main, @function /* main - функция (а не данные) */
main:
movl $4, %eax /* поместить номер системного вызова
write = 4 в регистр %eax */
movl $1, %ebx /* первый параметр - в регистр %ebx;
номер файлового дескриптора
stdout - 1 */
movl $hello_str, %ecx /* второй параметр - в регистр %ecx;
указатель на строку */
movl $hello_str_length, %edx /* третий параметр - в регистр
%edx; длина строки */
int $0x80 /* вызвать прерывание 0x80 */
movl $1, %eax /* номер системного вызова exit - 1 */
movl $0, %ebx /* передать 0 как значение параметра */
int $0x80 /* вызвать exit(0) */
.size main,. - main /* размер функции main */
Напомним, сейчас наша задача - скомпилировать первую программу. Подробное объяснение этого кода будет потом.
[user@host:~]$ gcc hello.s -o hello
[user@host:~]$
Если компиляция проходит успешно, GCC ничего не выводит на экран. Кроме компиляции, GCC автоматически выполняет и компоновку, как и при компиляции программ на C. Теперь запускаем нашу программу и убеждаемся, что она корректно завершилась с кодом возврата 0.
[user@host:~]$./hello
Hello, world!
[user@host:~]$ echo $?
Теперь было бы хорошо прочитать последнюю лекцию про отладчик. Он вам понадобится для исследования работы ваших программ. Возможно, сейчас вы не всё поймёте, но эта лекция специально расположена в конце, так как задумана больше как справочная, нежели обучающая. Для того, чтобы научиться работать с отладчиком, с ним нужно просто работать.
Команды
Команды ассемблера - это те инструкции, которые будет исполнять процессор. По сути, это самый низкий уровень программирования процессора. Каждая команда состоит из операции (что делать?) и операндов (аргументов). Операции мы будем рассматривать отдельно. А операнды у всех операций задаются в одном и том же формате. Операндов может быть от 0 (то есть нет вообще) до 3. В роли операнда могут выступать:
· Конкретное значение, известное на этапе компиляции, - например, числовая константа или символ. Записываются при помощи знака $, например: $0xf1, $10, $hello_str. Эти операнды называются непосредственными.
· Регистр. Перед именем регистра ставится знак %, например: %eax, %bx, %cl.
· Указатель на ячейку в памяти (как он формируется и какой имеет синтаксис записи - далее в этом разделе).
· Неявный операнд. Эти операнды не записываются непосредственно в исходном коде, а подразумеваются. Нет, конечно, компьютер не читает ваши мысли. Просто некоторые команды всегда обращаются к определённым регистрам без явного указания, так как это входит в логику их работы. Такое поведение всегда описывается в документации.

| Внимание! Если вы забудете знак $, когда записываете непосредственное числовое значение, компилятор будет интерпретировать число как абсолютный адрес. Это не вызовет ошибок компиляции, но, скорее всего, приведёт к ошибке сегментации (segmentation fault) при выполнении. |
Почти у каждой команды можно определить операнд -источник (из него команда читает данные) и операнд -назначение (в него команда записывает результат). Общий синтаксис команды ассемблера такой:
Операция Источник, Назначение
Для того, чтобы привести пример команды, я, немного забегая наперед, расскажу об одной операции. Команда mov источник, назначение производит копирование источника в назначение. Возьмем строку из hello.s:
movl $4, %eax /* поместить номер системного вызова
write = 4 в регистр %eax */
Как видим, источник - это непосредственное значение 4, а назначение - регистр %eax. Суффикс l в имени команды указывает на то, что ей следует работать с операндами длиной в 4 байта. Все суффиксы:
· b (от англ. byte) - 1 байт,
· w (от англ. word) - 2 байта,
· l (от англ. long) - 4 байта,
· q (от англ. quad) - 8 байт.
Таким образом, чтобы записать $42 в регистр %al (а он имеет размер 1 байт):
movb $42, %al
Важной особенностью всех команд является то, что они не могут работать с двумя операндами, находящимися в памяти. Хотя бы один из них следует сначала загрузить в регистр, а затем выполнять необходимую операцию.
Как формируется указатель на ячейку памяти? Синтаксис:
смещение(база, индекс, множитель)
Вычисленный адрес будет равен база + индекс? множитель + смещение. Множитель может принимать значения 1, 2, 4 или 8. Например:
· (%ecx) адрес операнда находится в регистре %ecx. Этим способом удобно адресовать отдельные элементы в памяти, например, указатель на строку или указатель на int;
· 4(%ecx) адрес операнда равен %ecx + 4. Удобно адресовать отдельные поля структур. Например, в %ecx адрес некоторой структуры, второй элемент которой находится "на расстоянии" 4 байта от её начала (говорят "по смещению 4 байта");
· -4(%ecx) адрес операнда равен %ecx? 4;
· foo(,%ecx,4) адрес операнда равен foo + %ecx? 4, где foo - некоторый адрес. Удобно обращаться к элементам массива. Если foo - указатель на массив, элементы которого имеют размер 4 байта, то мы можем заносить в %ecx номер элемента и таким образом обращаться к самому элементу.
Ещё один важный нюанс: команды нужно помещать в секцию кода. Для этого перед командами нужно указать директиву.text. Вот так:
.text
movl $42, %eax
...
Данные
Существуют директивы ассемблера, которые размещают в памяти данные, определенные программистом. Аргументы этих директив - список выражений, разделенных запятыми.
·.byte - размещает каждое выражение как 1 байт;
·.short - 2 байта;
·.long - 4 байта;
·.quad - 8 байт.
Например:
.byte 0x10, 0xf5, 0x42, 0x55
.long 0xaabbaabb
.short -123, 456
Также существуют директивы для размещения в памяти строковых литералов:
·.ascii "STR" размещает строку STR. Нулевых байтов не добавляет.
·.string "STR" размещает строку STR, после которой следует нулевой байт (как в языке Си).
· У директивы.string есть синоним.asciz (z от англ. zero - ноль, указывает на добавление нулевого байта).
Строка- аргумент этих директив может содержать стандартные escape-последовательности, которые вы использовали в Си, например, \n, \r, \t, \\, \" и так далее.
Данные нужно помещать в секцию данных. Для этого перед данными нужно поместить директиву.data. Вот так:
.data
.string "Hello, world\n"
...
Если некоторые данные не предполагается изменять в ходе выполнения программы, их можно поместить в специальную секцию данных только для чтения при помощи директивы.section.rodata:
.section.rodata
.string "program version 0.314"
Приведём небольшую таблицу, в которой сопоставляются типы данных в Си на IA-32 и в ассемблере. Нужно заметить, что размер этих типов в языке Си на других архитектурах (или даже компиляторах) может отличаться.
| Тип данных в Си | Размер (sizeof), байт | Выравнивание, байт | Название |
| Char signed char | signed byte (байт со знаком) | ||
| Unsigned char | unsigned byte (байт без знака) | ||
| Short signed short | signed halfword (полуслово со знаком) | ||
| Unsigned short | unsigned halfword (полуслово без знака) | ||
| Int signed int long signed long enum | signed word (слово со знаком) | ||
| unsigned int unsigned long | unsigned word (слово без знака) |
Отдельных объяснений требует колонка "Выравнивание". Выравнивание задано у каждого фундаментального типа данных (типа данных, которым процессор может оперировать непосредственно). Например, выравнивание word - 4 байта. Это значит, что данные типа word должны располагаться по адресу, кратному 4 (например, 0x00000100, 0x03284478). Архитектура рекомендует, но не требует выравнивания: доступ к невыровненным данным может быть медленнее, но принципиальной разницы нет и ошибки это не вызовет.
Для соблюдения выравнивания в распоряжении программиста есть директива. p2align.
.p2align степень_двойки, заполнитель, максимум
Директива. p2align выравнивает текущий адрес до заданной границы. Граница выравнивания задаётся как степень числа 2: например, если вы указали.p2align 3 - следующее значение будет выровнено по 8-байтной границе. Для выравнивания размещается необходимое количество байт -заполнителей со значением заполнитель. Если для выравнивания требуется разместить более чем максимум байт -заполнителей, то выравнивание не выполняется.
Второй и третий аргумент являются необязательными.
Примеры:
.data
.string "Hello, world\n" /* мы вряд ли захотим считать,
сколько символов занимает эта
строка, и является ли следующий
адрес выровненным */
.p2align 2 /* выравниваем по границе 4 байта
для следующего.long */
.long 123456
Метки и прочие символы
Вы, наверно, заметили, что мы не присвоили имён нашим данным. Как же к ним обращаться? Очень просто: нужно поставить метку. Метка - это просто константа, значение которой - адрес.
hello_str:
.string "Hello, world!\n"
Сама метка, в отличие от данных, места в памяти программы не занимает. Когда компилятор встречает в исходном коде метку, он запоминает текущий адрес и читает код дальше. В результате компилятор помнит все метки и адреса, на которые они указывают. Программист может ссылаться на метки в своём коде. Существует специальная псевдометка, указывающая на текущий адрес. Это метка. (точка).
Значение метки как константы - это всегда адрес. А если вам нужна константа с каким-то другим значением? Тогда мы приходим к более общему понятию "символ". Символ - это просто некоторая константа. Причём он может быть определён в одном файле, а использован в других.
Возьмём hello.s и скомпилируем его так:
[user@host:~]$ gcc -c hello.s
[user@host:~]$
Обратите внимание на параметр -c. Мы компилируем исходный код не в исполняемый файл, а лишь только в отдельный объектный файл hello.o. Теперь воспользуемся программой nm(1):
[user@host:~]$ nm hello.o
00000000 d hello_str
0000000e a hello_str_length
00000000 T main
nm(1) выводит список символов в объектном файле. В первой колонке выводится значение символа, во второй - его тип, в третьей - имя. Посмотрим на символ hello_str_length. Это длина строки Hello, world!\n. Значение символа чётко определено и равно 0xe, об этом говорит тип a - absolute value. А вот символ hello_str имеет тип d - значит, он находится в секции данных (data). Символ main находится в секции кода (text section, тип T). А почему a представлено строчной буквой, а T - прописной? Если тип символа обозначен строчной буквой, значит это локальный символ, который видно только в пределах данного файла. Заглавная буква говорит о том, что символ глобальный и доступен другим модулям. Символ main мы сделали глобальным при помощи директивы.global main.
Для создания нового символа используется директива. set. Синтаксис:
.set символ, выражение
Например, определим символ foo = 42:
.set foo, 42
Ещё пример из hello.s:
hello_str:
.string "Hello, world!\n" /* наша строка */
.set hello_str_length,. - hello_str - 1 /* длина строки */
Сначала определяется символ hello_str, который содержит адрес строки. После этого мы определяем символ hello_str_length, который, судя по названию, содержит длину строки. Директива. set позволяет в качестве значения символа использовать арифметические выражения. Мы из значения текущего адреса (метка "точка") вычитаем адрес начала строки - получаем длину строки в байтах. Потом мы вычитаем ещё единицу, потому что директива. string добавляет в конце строки нулевой байт (а на экран мы его выводить не хотим).
Неинициализированные данные
Часто требуется просто зарезервировать место в памяти для данных, без инициализации какими-то значениями. Например, у вас есть переменная, значение которой определяется параметрами командной строки. Действительно, вы вряд ли сможете дать ей какое-то осмысленное начальное значение, разве что 0. Такие данные называются неинциализированными, и для них выделена специальная секция под названием.bss. В скомпилированной программе эта секция места не занимает. При загрузке программы в память секция неинициализированых данных будет заполнена нулевыми байтами.
Хорошо, но известные нам директивы размещения данных требуют указания инициализирующего значения. Поэтому для неинициализированных данных используются специальные директивы:
.space количество_байт
.space количество_байт, заполнитель
Директива. space резервирует количество_байт байт.
Также эту директиву можно использовать для размещения инициализированных данных, для этого существует параметр заполнитель - этим значением будет инициализирована память.
Например:
.bss
long_var_1: /* по размеру как.long */
.space 4
buffer: /* какой-то буфер в 1024 байта */
.space 1024
struct: /* какая-то структура размером 20 байт */
.space 20
Лекция 4: Методы адресации
Пространство памяти предназначено для хранения кодов команд и данных, для доступа к которым имеется богатый выбор методов адресации (около 24). Операнды могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение местоположения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
Непосредственная адресация
В команде содержится не адрес операнда, а непосредственно сам операнд.

Непосредственная адресация позволяет повысить скорость выполнения операции, так как в этом случае вся команда, включая операнд, считывается из памяти одновременно и на время выполнения команды хранится в процессоре в специальном регистре команд (РК). Однако при использовании непосредственной адресации появляется зависимость кодов команд от данных, что требует изменения программы при каждом изменении непосредственного операнда.
Пример:
.text
main:
movl $0x12345, %eax /* загрузить константу 0x12345 в
регистр %eax. */
Регистровая адресация
Предполагается, что операнд находится во внутреннем регистре процессора.
Пример:
.text
main:
movl $0x12345, %eax /* записать в регистр константу 0x12345
*/
movl %eax, %ecx /* записать в регистр %ecx операнд,
который находится в регистре %eax */
Относительная адресация
Этот способ используется тогда, когда память логически разбивается на блоки, называемые сегментами. В этом случае адрес ячейки памяти содержит две составляющих: адрес начала сегмента (базовый адрес) и смещение адреса операнда в сегменте. Адрес операнда определяется как сумма базового адреса и смещения относительно этой базы:

Для задания базового адреса и смещения могут применяться ранее рассмотренные способы адресации. Как правило, базовый адрес находится в одном из регистров регистровой памяти, а смещение может быть задано в самой команде или регистре.
Рассмотрим два примера:
1. Адресное поле команды состоит из двух частей, в одной указывается номер регистра, хранящего базовое значение адреса (начальный адрес сегмента), а в другом адресном поле задается смещение, определяющее положение ячейки относительно начала сегмента. Именно такой способ представления адреса обычно и называют относительной адресацией.
2. Первая часть адресного поля команды также определяет номер базового регистра, а вторая содержит номер регистра, в котором находится смещение. Такой способ адресации чаще всего называют базово-индексным.
Главный недостаток относительной адресации - большое время вычисления физического адреса операнда. Но существенное преимущество этого способа адресации заключается в возможности создания "перемещаемых" программ - программ, которые можно размещать в различных частях памяти без изменения команд программы. То же относится к программам, обрабатывающим по единому алгоритму информацию, расположенную в различных областях ЗУ. В этих случаях достаточно изменить содержимое базового адреса начала команд программы или массива данных, а не модифицировать сами команды. По этой причине относительная адресация облегчает распределение памяти при составлении сложных программ и широко используется при автоматическом распределении памяти в мультипрограммных вычислительных системах.
Команда mov
Синтаксис:
mov источник, назначение
Команда mov производит копирование источника в назначение. Рассмотрим примеры:
/*
* Это просто примеры использования команды mov,
* ничего толкового этот код не делает
*/
.data
some_var:
.long 0x00000072
other_var:
.long 0x00000001, 0x00000002, 0x00000003
.text
.globl main
main:
movl $0x48, %eax /* поместить число 0x00000048 в %eax */
movl $some_var, %eax /* поместить в %eax значение метки
some_var, то есть адрес числа в
памяти; например, у автора
содержимое %eax равно 0x08049589 */
movl some_var, %eax /* обратиться к содержимому переменной;
в %eax теперь 0x00000072 */
movl other_var + 4, %eax /* other_var указывает на 0x00000001
размер одного значения типа long - 4
байта; значит, other_var + 4
указывает на 0x00000002;
в %eax теперь 0x00000002 */
movl $1, %ecx /* поместить число 1 в %ecx */
movl other_var(,%ecx,4), %eax /* поместить в %eax первый
(нумерация с нуля) элемент массива
other_var, пользуясь %ecx как
индексным регистром */
movl $other_var, %ebx /* поместить в %ebx адрес массива
other_var */
movl 4(%ebx), %eax /* обратиться по адресу %ebx + 4;
в %eax снова 0x00000002 */
movl $other_var + 4, %eax /* поместить в %eax адрес, по
которому расположен 0x00000002
(адрес массива плюс 4 байта --
пропустить нулевой элемент) */
movl $0x15, (%eax) /* записать по адресу "то, что записано
в %eax " число 0x00000015 */
Внимательно следите, когда вы загружаете адрес переменной, а когда обращаетесь к значению переменной по её адресу. Например:
movl other_var + 4, %eax /* забыли знак $, в результате в %eax
находится число 0x00000002 */
movl $0x15, (%eax) /* пытаемся записать по адресу
0x00000002 - > получаем segmentation
fault */
movl 0x48, %eax /* забыли $, и пытаемся обратиться по
адресу 0x00000048 - > segmentation
fault */
Команда lea
lea - мнемоническое от англ. Load Effective Address. Синтаксис:
lea источник, назначение
Команда lea помещает адрес источника в назначение. Источник должен находиться в памяти (не может быть непосредственным значением - константой или регистром). Например:
.data
some_var:
.long 0x00000072
.text
leal 0x32, %eax /* аналогично movl $0x32, %eax */
leal some_var, %eax /* аналогично movl $some_var, %eax */
leal $0x32, %eax /* вызовет ошибку при компиляции,
так как $0x32 - непосредственное
значение */
leal $some_var, %eax /* аналогично, ошибка компиляции:
$some_var - это непосредственное
значение, адрес */
leal 4(%esp), %eax /* поместить в %eax адрес предыдущего
элемента в стеке;
фактически, %eax = %esp + 4 */
Арифметика
Арифметических команд в нашем распоряжении довольно много. Синтаксис:
inc операнд
dec операнд
add источник, приёмник
sub источник, приёмник
mul множитель_1
Принцип работы:
· inc: увеличивает операнд на 1.
· dec: уменьшает операнд на 1.
· add: приёмник = приёмник + источник (то есть, увеличивает приёмник на источник).
· sub: приёмник = приёмник - источник (то есть, уменьшает приёмник на источник).
Команда mul имеет только один операнд. Второй сомножитель задаётся неявно. Он находится в регистре %eax, и его размер выбирается в зависимости от суффикса команды (b, w или l). Место размещения результата также зависит от суффикса команды. Нужно отметить, что результат умножения двух 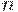 -разрядных чисел может уместиться только в
-разрядных чисел может уместиться только в 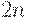 -разрядном регистре результата. В следующей таблице описано, в какие регистры попадает результат при той или иной разрядности операндов.
-разрядном регистре результата. В следующей таблице описано, в какие регистры попадает результат при той или иной разрядности операндов.
| Команда | Второй сомножитель | Результат |
| mulb | %al | 16 бит: %ax |
| mulw | %ax | 32 бита: младшая часть в %ax, старшая в %dx |
| mull | %eax | 64 бита: младшая часть в %eax, старшая в %edx |
Примеры:
.text
movl $72, %eax
incl %eax /* в %eax число 73 */
decl %eax /* в %eax число 72 */
movl $48, %eax
addl $16, %eax /* в %eax число 64 */
movb $5, %al
movb $5, %bl
mulb %bl /* в регистре %ax произведение
%al? %bl = 25 */
Давайте подумаем, каким будет результат выполнения следующего кода на Си:
char x, y;
x = 250;
y = 14;
x = x + y;
printf("%d ", (int) x);
Большинство сразу скажет, что результат (250 + 14 = 264) больше, чем может поместиться в одном байте. И что же напечатает программа? 8. Давайте рассмотрим, что происходит при сложении в дв

Эмиссия газов от очистных сооружений канализации: В последние годы внимание мирового сообщества сосредоточено на экологических проблемах...

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...
Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

Типы оградительных сооружений в морском порту: По расположению оградительных сооружений в плане различают волноломы, обе оконечности...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!