Реляционная БД представляет собой совокупность схем отношений связанных друг с другом.
В РМД предполагается, что все отношения нормализованы, т.е. каждый кортеж должен содержать только атомарные элементы. Операции над отношениями выполняются с помощью средств реляционного исчисления и средств реляционной алгебры.
Реляционная модель данных – позволяет представлять информацию о предметной области с помощью взаимосвязанных таблиц.
В реляционных базах данных вся информация сведена в таблицы, строки и столбцы которых называются записями и полями соответственно. Эти таблицы получили название реляций. Записи в таблицах не повторяются. Их уникальность обеспечивается первичным ключом, содержащим набор полей, однозначно определяющих запись. Для быстрого поиска информации в базе данных создаются индексы по одному или нескольким полям таблицы. Значения индексов хранятся в упорядоченном виде и содержат ссылки на записи таблицы. Для автоматической поддержки целостности связанных данных, находящихся в разных таблицах, используются первичные и внешние ключи. Для выборки данных из нескольких связанных таблиц используются значения одного или нескольких совпадающих полей. Например, таблица регистрации междугородних телефонных разговоров может содержать следующие сведения:
· Номер заказа
· Код услуги
· Номер телефона
· Дата разговора
· Код города
· Продолжительность разговора
· Стоимость
Примечание
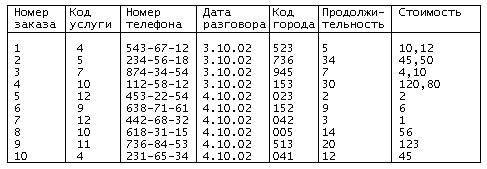
Каждая строка имеет одинаковую структуру и состоит из восьми полей. В рассматриваемом примере это поля: Номер заказа, Код услуги, Номер телефона, Дата разговора, Код города, Продолжительность, Стоимость.
Достоинства:
· Эта модель данных отображает информацию в наиболее простой для пользователя форме
· Основана на развитом математическом аппарате, который позволяет достаточно лаконично описать основные операции над данными.
· Позволяет создавать языки манипулирования данными не процедурного типа.
· Манипулирование данными на уровне выходной БД и возможность изменения.
Недостатки:
Самый медленный доступ к данным.
· Трудоемкость разработки
8. Основные компоненты СУБД и их вз/д-е. Типы и структуры данных.
Система управления базами данных (СУБД) - совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Функции СУБД:
· управление данными во внешней памяти (на дисках, ЗУ);
· управление данными в оперативной памяти;
· журнализация изменений и восстановление базы данных после сбоев;
· поддержание некоторых специализированных языков взаимодействия БД (язык определения (описания) данных, язык манипулирования данными).
Состав СУБД:
· ядро, отвечает за управление данными во внешней и ОП и журнализацию (осуществляется в терминах ОС);
· процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода СУБД;
· подсистему поддержки времени исполнения, которая интерпретирует прикладные программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
· а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Схема взаимодействия компонентов СУБД:

Типы и структуры данных:
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ (символы, числа), или сложному (структуры), конструируемому пользователем для решения конкретных задач. Структуры делятся на:
· Статические- структуры занимающие в памяти ЭВМ постоянный объём;
· Динамические- ряд структур, изменяющих свою длину.
К статическим структурам относятся:
- Массив (функция с конечной областью определения) - простая совокупность элементов данных одного типа. Отдельный элемент массива задается индексом. Массив может быть одномерным, двумерным и т.д. Разновидностями одномерных массивов переменной длины являются структуры типа кольцо, стек, очередь и двухсторонняя очередь.
· Запись (декартово произведение) - совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называют полями. Совокупность записей одинаковой структуры называется файлом. Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом.
К динамическим структурам относятся:
· Дерево- называется конечное множество, состоящее из одного или более элементов, называемых узлами;
· Список- конечное, возможно пустое множество данных (элементов) различной природы, имеющее определённый смысл для решаемой задачи. В качестве элементов множества (списка) могут выступать любые другие элементы данных, в том числе и сами списки;

9. Обработка данных в СУБД, основные методы доступа к данным, использование структуры данных типа «дерево».
Вопросы представления данных тесно связаны с операциями, при помощи которых эти данные обрабатываются. К числу таких операций относятся: выборка, изменение,включение и исключение данных. В основе всех перечисленных операций лежит операция доступа, которую нельзя рассматривать независимо от способа представления.
В задачах поиска предполагается, что все данные хранятся в памяти с определенной идентификацией и, говоря о доступе, имеют в виду прежде всего доступ к данным (называемым ключами), однозначно идентифицирующим связанные с ними совокупности данных.
Существуют два класса методов, реализующих доступ к данным по ключу:
- методы поиска по дереву,
- методы хеширования.
Методы поиска по дереву
Определение: Деревом называется конечное множество, состоящее из одного или более элементов, называемых узлами, таких, что:
- между узлами имеет место отношение типа "исходный-порожденный";
- есть только один узел, не имеющий исходного. Он называется корнем;
- все узлы за исключением корня имеют только один исходный; каждый узел может иметь несколько порожденных;
- отношение "исходный-порожденный" действует только в одном направлении, т.е. ни один потомок некоторого узла не может стать для него предком.
Число порожденных отдельного узла (число поддеревьев данного корня) называется его степенью. Узел с нулевой степенью называют листом или концевым узлом. Максимальное значение степени всех узлов данного дерева называется степенью дерева.
Если в дереве между порожденными узлами, имеющими общий исходный, считается существенным их порядок, то дерево называется упорядоченным. В задачах поиска почти всегда рассматриваются упорядоченные деревья.
Упорядоченное дерево, степень которого не больше 2 называется бинарным деревом. Бинарное дерево особенно часто используется при поиске в оперативной памяти. Алгоритм поиска: вначале аргумент поиска сравнивается с ключом, находящимся в корне. Если аргумент совпадает с ключом, поиск закончен, если же не совпадает, то в случае, когда аргумент оказвается меньше ключа, поиск продолжается в левом поддереве, а в случае когда больше ключа - в правом поддереве. Увеличив уровень на 1 повторяют сравнение, считая текущий узел корнем.
Бинарные деревья особенно эффективны в случае когда множество ключей заранее неизвестно, либо когда это множество интенсивно изменяется. Очевидно, что при переменном множестве ключей лучше иметь сбалансированное дерево.
Определение: Бинарное дерево называют сбалансированным (balanced), если высота левого поддерева каждого узла отличается от высоты правого поддерева не более чем на 1.
При поиске данных во внешней памяти очень важной является проблема сокращения числа перемещений данных из внешней памяти в оперативную. Поэтому, в данном случае по сравнению с бинарными деревьями более выгодными окажутся сильно ветвящиеся деревья - т.к. их высота меньше, то при поиске потребуется меньше обращений к внешней памяти. Наибольшее применение в этом случае получили В-деревья (В - balanced)
Определение: В-деревом порядка n называется сильно ветвящееся дерево степени 2n+1, обладающее следующими свойствами:
- Каждый узел, за исключением корня, содержит не менее n и не более 2n ключей.
- Корень содержит не менее одного и не более 2n ключей.
- Все листья расположены на одном уровне.
- Каждый нелистовой узел содержит два списка: упорядоченный по возрастанию значений список ключей и соответсвующий ему список указателей (для листовых узлов список указателей отсутствует).
Для такого дерева:
- сравнительно просто может быть организован последовательный доступ, т.к. все листья расположены на одном уровне;
- при добавлении и изменении ключей все изменения ограничиваются, как правило, одним узлом.

Сбалансированное дерево
В -дерево, в котором истинные значения содержатся только в листьях (концевых узлах), называется В+ -деревом. Во внутренних узлах такого дерева содержатся ключи-разделители, задающие диапазон изменения ключей для поддеревьев.
R -дерево (R -Tree) это индексная структура для доступа к пространственным данным, предложенная А.Гуттманом (Калифорнийский университет, Беркли). R-дерево допускает произвольное выполнение операций добавления, удаления и поиска данных без периодической переиндексации
10. Поиск информации в БД с использованием структуры типа «бинарное дерево».
В задачах поиска предполагается, что все данные хранятся в памяти с определенной идентификацией и, говоря о доступе, имеют в виду, доступ к ключам, однозначно идентифицирующим связанные с ними совокупности данных. Существуют 2 класса методов, реализующих доступ к данным по ключу: методы поиска по дереву и методы хеширования.
Деревом называется конечное множество, состоящее из одного или более элементов, называемых узлами, таких, что:
1. Между узлами имеет место отношение типа "исходный-порожденный";
2. Есть только один узел, не имеющий исходного. Он называется корнем;
3. Все узлы за исключением корня имеют только один исходный; каждый узел может иметь несколько порожденных;
4. Отношение "исходный-порожденный" действует только в одном направлении, т.е. ни один потомок некоторого узла не может стать для него предком.
Число порожденных отдельного узла (число поддеревьев данного корня) называется его степенью. Узел с нулевой степенью называют листом или концевым узлом. Максимальное значение степени всех узлов данного дерева называется степенью дерева.
Если в дереве между порожденными узлами, имеющими общий исходный, считается существенным их порядок, то дерево называется упорядоченным. В задачах поиска почти всегда рассматриваются упорядоченные деревья.
Упорядоченное дерево, степень которого не больше 2 называется бинарным деревом. Бинарное дерево особенно часто используется при поиске в оперативной памяти. Алгоритм поиска: вначале аргумент поиска сравнивается с ключом, находящимся в корне. Если аргумент совпадает с ключом, поиск закончен, если же не совпадает, то в случае, когда аргумент оказывается меньше ключа, поиск продолжается в левом поддереве, а в случае когда больше ключа - в правом поддереве. Увеличив уровень на 1 повторяют сравнение, считая текущий узел корнем.
Пример
Дан список студентов, содержащий их фамилии и средний бал успеваемости. В качестве ключа используется фамилия. Предположим, что все записи имеют фиксированную длину, тогда в качестве указателя можно использовать номер записи. Смещение записи в файле в этом случае будет вычислятся как ([номер_записи] -1) * [длина_записи].
Пусть аргумент поиска = "Петров". На рисунке показан один из возможных для этого набора данных бинарных деревьев поиска и путь поиска.
Поиск по бинарному дереву:

Здесь используется следующее правило сравнения строк: значение символа соответствует его порядковому номеру в алфавите. Поэтому "И" меньше "К", а "К" меньше "С". Если текущие символы в сравниваемых строках совпадают, то сравниваются символы в следующих позициях.
Бинарные деревья особенно эффективны в случае когда множество ключей заранее неизвестно, либо когда это множество интенсивно изменяется.
11. Поиск информации в БД с использованием структуры типа «сильноветвящееся дерево».
При поиске данных во внешней памяти очень важной является проблема сокращения числа перемещений данных из внешней памяти в оперативную. Поэтому, в данном случае по сравнению с бинарными деревьями более выгодными окажутся сильно ветвящиеся деревья - т.к. их высота меньше, то при поиске потребуется меньше обращений к внешней памяти. Наибольшее применение в этом случае получили В-деревья (В - balanced)
Определение: В-деревом порядка n называется сильно ветвящееся дерево степени 2n+1, обладающее следующими свойствами:
5. Каждый узел, за исключением корня, содержит не менее n и не более 2n ключей.
6. Корень содержит не менее одного и не более 2n ключей.
7. Все листья расположены на одном уровне.
8. Каждый нелистовой узел содержит два списка: упорядоченный по возрастанию значений список ключей и соответсвующий ему список указателей (для листовых узлов список указателей отсутствует).
Для такого дерева:
· сравнительно просто может быть организован последовательный доступ, т.к. все листья расположены на одном уровне;
· при добавлении и изменении ключей все изменения ограничиваются, как правило, одним узлом.

В -дерево, в котором истинные значения содержатся только в листьях (концевых узлах), называется В+ -деревом. Во внутренних узлах такого дерева содержатся ключи-разделители, задающие диапазон изменения ключей для поддеревьев. Следует отметить, что B -деревья наилучшим образом подходят только для организации доступа к достаточно простым (одномерным) структурам данных.
12. Методы хеширования для реализации доступа к данным по ключу.
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского "to hash" - резать, измельчать). Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи организуются в виде таблицы, называемой хеш-таблицей.
Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов.
13. Представление данных с помощью модели «сущность-связь», основные элементы модели.
Разработчик должен сформировать понятия о предметах, фактах и событиях, которыми будет оперировать система. Для того, чтобы привести эти понятия к той или иной модели данных, необходимо заменить их информационными представлениями. Одним из наиболее удобных инструментов унифицированного представления данных, независимого от реализующего его программного обеспечения, является модель "сущность-связь" (entity - relationship model, ER - model).
Модель "сущность-связь" основывается на некой важной семантической информации о реальном мире и предназначена для логического представления данных. Она определяет значения данных в контексте их взаимосвязи с другими данными. Из модели "сущность-связь" могут быть порождены все существующие модели данных (иерархическая, сетевая, реляционная, объектная), поэтому она является наиболее общей. Представляет собой графическую нотацию, основанную на блоках и соединяющих их линиях, с помощью которых можно описывать объекты и отношения между ними какой-либо другой модели данных.
Элементы модели.
Любой фрагмент предметной области может быть представлен как множество сущностей, между которыми существует некоторое множество связей.
1. Сущность (entity) - это объект, который может быть идентифицирован неким способом, отличающим его от других объектов. Примеры: конкретный человек, предприятие, событие и т.д.
2. Набор сущностей (entity set) - множество сущностей одного типа (обладающих одинаковыми свойствами). Примеры: все люди, предприятия, праздники и т.д. Наборы сущностей не обязательно должны быть непересекающимися. Например, сущность, принадлежащая к набору МУЖЧИНЫ, также принадлежит набору ЛЮДИ.
3.Сущность фактически представляет из себя множество атрибутов, которые описывают свойства всех членов данного набора сущностей.
Атрибут - функция, отображающая набор сущностей в набор значений или в декартово произведение наборов значений.
Домен -множество значений атрибута.
4. Ключ сущности - группа атрибутов, такая, что отображение набора сущностей в соответствующую группу наборов значений является взаимнооднозначным отображением. Другими словами: ключ сущности - это один или более атрибутов, уникально определяющих данную сущность.
5. Связь – в общем случае это некоторая ассоциация, которая устанавливается между несколькими сущностями.
Набор связей – это отношение между N сущностями каждое из которых относится к отдельному набору сущностей (N>=2).
N=2 – Бинарная связь.
N>2 – N-арная связь.
При построении модели С-С N-арной связи:
лучше отражают семантику П.О.
позволяют создать более компактную модель С-С.
Такие связи трудно реализуемы, и не обеспечивают целостность информации.
Бинарные связи – позволяют в полной мере обеспечить целостность связи.
14. Типы и характеристики связей сущностей.
Связь (relationship) -это ассоциация, установленная между несколькими сущностями.
Пример:
- поскольку каждый сотрудник работает в каком-либо отделе, между сущностями СОТРУДНИК и ОТДЕЛ существует связь "работает в" или ОТДЕЛ-РАБОТНИК;
- так как один из работников отдела является его руководителем, то между сущностями СОТРУДНИК и ОТДЕЛ имеется связь "руководит" или ОТДЕЛ-РУКОВОДИТЕЛЬ;
- могут существовать и связи между сущностями одного типа, например связь РОДИТЕЛЬ - ПОТОМОК между двумя сущностями ЧЕЛОВЕК;
Набор связей (relationship set) - это отношение между n (причем n не меньше 2) сущностями, каждая из которых относится к некоторому набору сущностей.
Пример:
сущности наборы сущностей ---------- ---------------- e1 принадлежит E1 e2 принадлежит E2... en принадлежит En тогда [e1,e2,...,en] - набор связей R В случае n=2, т.е. когда связь объединяет две сущности, она называется бинарной.
Степень связи - то число сущностей, которое может быть ассоциировано через набор связей с другой сущностью.
Виды степеней связи: 1. один к одному (1: 1). Это означает, что в такой связи сущности с одной ролью всегда соответствует не более одной сущности с другой ролью.
 2. один ко многим (1: n).
2. один ко многим (1: n). Это означает что сущности с одной ролью может соответствовать любое число сущностей с другой ролью.
 3. много к одному (n:1).
3. много к одному (n:1). Этот тип связи аналогичен связям один ко многим.
4.  много ко многим (n:n).
много ко многим (n:n). В этом случае каждая из ассоциированных сущностей может быть представлена любым количеством экземпляров
Класс принадлежности сущности, входящей в состав связи (кординальность связи): Так как в каждом отделе обязательно должен быть руководитель, то каждой сущности "ОТДЕЛ" непременно должна соответствовать сущность "СОТРУДНИК". Однако, не каждый сотрудник является руководителем отдела, следовательно в данной связи не каждая сущность "СОТРУДНИК" имеет ассоциированную с ней сущность "ОТДЕЛ".
Таким образом, говорят, что сущность "СОТРУДНИК" имеет обязательный класс принадлежности (этот факт обозначается также указанием интервала числа возможных вхождений сущности в связь, в данном случае это 1,1), а сущность "ОТДЕЛ" имеет необязательный класс принадлежности (0,1)
·
Обязательный класс принадлежности; 

·
Необязательный класс принадлежности. 

Если существование сущности X зависит от существования сущности Y, то X называется зависимой сущностью (иногда сущность X называют "слабой", а "сущность" Y - сильной).
Пример:

Рабочая группа создается только после того, как будет подписан контракт с заказчиком, и прекращает свое существование по выполнению контракта. Таким образом, сущность РАБОЧАЯ_ГРУППА является зависимой от сущности КОНТРАКТ. Зависимая сущность обозначается двойным прямоугольником, а ее связь с сильной сущностью линией со стрелкой.







