Схема распределения весов, описанная в предыдущем разделе, является полным разделением весов (FWS). Это стандарт для CNNs, используемый при обработке изображений, поскольку одни и те же паттерны могут появляться в любом месте изображения. Однако свойства речевого сигнала обычно различаются в разных частотных диапазонах. Использование отдельных наборов весов для различных частотных диапазонов может быть более подходящим, поскольку это позволяет обнаруживать различные характерные паттерны в различных полосах фильтров вдоль оси частот.
| Справа показан пример схемы LWS для CNNs, где только ячейки свертки, присоединенные к одной и той же ячейке объединения, имеют одинаковые весов свертки.
| 
|
Каждый частотный диапазон можно рассматривать как отдельную подсеть со своими собственными весами свертки. Для удобства называем эти подсети секциями. Секции содержат ряд карт объектов в слое свертки.
Каждая из этих карт объектов создается с помощью одного весового вектора для сканирования всех входных измерений в этой секции, чтобы определить наличие или отсутствие этого признака. Размер пула определяет количество применений этого весового вектора к соседним локациям во входном пространстве, т. е. размер каждой карты объектов в слое свертки равен размеру пула. Каждая ячейка объединяет всю карту объектов свертки в одно число с помощью функции объединения, такой как максимизация или усреднение.
Активация слоя свертки может быть вычислена как:

где  — n-й вес свертки (F — размер карты), отображающий из i-й входной карты объектов в j-ю сверточную карту в k-ой секции, а
— n-й вес свертки (F — размер карты), отображающий из i-й входной карты объектов в j-ю сверточную карту в k-ой секции, а 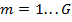 (G — размер пула).
(G — размер пула).
В этом случае активация объединяющего слоя: 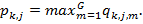
Аналогично, слои свертки LWS также можно представить в матричном виде с использованием большой разреженной матрицы. Однако теперь 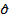 и
и 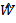 должны быть построены несколько иным образом.
должны быть построены несколько иным образом.
Прежде всего, разреженная матрица построена как показано справа
где каждый  формируется на основе локальных Весов, формируется на основе локальных Весов,
 
| 
|
Матрицы различаются по секциям и одна и та же весовая матрица реплицируется G раз в каждой секции.
Вычисленный слой свертки представляется, в виде большого вектора путем объединения всех значений в каждой секции следующим образом:
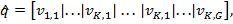
где K — общее количество секций, G — размер пула, а 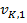 — вектор, содержащий значения ячеек в m-й полосе k-ой секции по всем картам объектов слоя свертки:
— вектор, содержащий значения ячеек в m-й полосе k-ой секции по всем картам объектов слоя свертки: 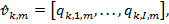 где I — общее количество входных карт объектов в каждой секции.
где I — общее количество входных карт объектов в каждой секции.
Обучение весов сети, в случае LWS, проводится как раньше, но с использованием новых и 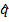 . Вектора ошибок распространяются следующим образом:
. Вектора ошибок распространяются следующим образом: 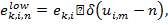 где
где  — дельта-функция.
— дельта-функция.
LWS также помогает уменьшить общее число ячеек в слое объединения, поскольку каждая полоса частот использует специальные веса, учитывающие только паттерны, появляющиеся в соответствующем диапазоне частот. В результате можно использовать меньшее количества карт объектов на одну полосу. С другой стороны, схема LWS не допускает добавления дополнительных слоев свертки поверх объединяющего слоя, поскольку объекты в различных секциях объединяющего слоя в LWS не связаны между собой.
B. Предобучение LWS-CNN
Модифицируем модель CRBM для предварительной настройки CNN с LWS, Для обучения CRBM нам необходимо определить условные вероятности состояний скрытых элементов с учетом видимых и наоборот. Условная вероятность активации для скрытого элемента, 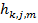 , представляющего состояние m-й полосы частот, j-й карты признаков из k-ой секции, заданного через v— входной сигнал CRBM, определяется как следующая функция softmax:
, представляющего состояние m-й полосы частот, j-й карты признаков из k-ой секции, заданного через v— входной сигнал CRBM, определяется как следующая функция softmax:
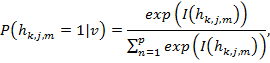
где 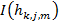 — взвешенная сумма входного сигнала, достигающего элемента . Она определяется как:
— взвешенная сумма входного сигнала, достигающего элемента . Она определяется как: 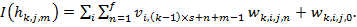
Условное распределение вероятностей видимого элемента, 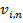 , n-ой полосы частот, i-ой карты объектов, учитывая скрытые состояния, может быть вычислено следующим гауссовским распределением:
, n-ой полосы частот, i-ой карты объектов, учитывая скрытые состояния, может быть вычислено следующим гауссовским распределением:
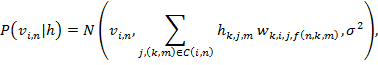
где выражение посередине — взвешенная сумма сигнала, поступающего от скрытых блоков, соединённых с видимыми элементами модели, 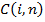 представляет эти связи как множество индексов полос свертки и секций, которые получают на вход от видимого блока .
представляет эти связи как множество индексов полос свертки и секций, которые получают на вход от видимого блока . 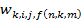 — вес соединяющий n-ую полосу, i-ую входную карту объектов с m-ой полосой j-ой карт объектов k-ой секции свертки,
— вес соединяющий n-ую полосу, i-ую входную карту объектов с m-ой полосой j-ой карт объектов k-ой секции свертки, 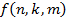 — функция отображения от индексов подключенных узлов до соответствующего индекса фильтрующего элемента, а
— функция отображения от индексов подключенных узлов до соответствующего индекса фильтрующего элемента, а 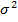 — дисперсия Гауссова распределения (фиксированный параметр модели).
— дисперсия Гауссова распределения (фиксированный параметр модели).
Основываясь на двух вышеприведенных условных вероятностях, все веса связи вышеупомянутого CRBM могут быть итеративно оценены с помощью регулярного алгоритма контрастивной дивергенции (CD). Веса обученных CRBMs могут быть использованы в качестве хороших начальных значений для слоя свертки в схеме LWS. После того, как первые веса слоев свертки изучены, они используются для вычисления выходных данных слоев свертки и объединения в пул. Выходы объединяющего слоя используются в качестве входных данных для непрерывного переобучения следующего слоя, как это делается в обучении DNN
V. Эксперименты
Эксперименты этого раздела были проведены на двух задачах распознавания речи для оценки эффективности CNNs в ASR: маломасштабное распознавание фонем в TIMIT и задача голосового поиска с большим словарным запасом (VS). Работа, описанная в этой статье, была расширена на другие более крупные задачи распознавания речи по лексике, что еще больше подтверждает ценность этого подхода.
A. Анализ речевых данных
Метод анализа речи аналогичен в двух наборах данных. Речь анализируется с помощью окна Хэмминга длиной 25 мс с фиксированной частотой кадров 10 мс. Векторы речевых признаков генерируются с помощью анализа банка фильтров на основе преобразования Фурье, который включает в себя 40 логарифмических энергетических коэффициентов, распределенных по шкале Мела, а также их первые и вторые производные по времени. Все речевые данные были нормализованы таким образом, чтобы они имели нулевое среднее и единичную дисперсию.






