

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Топ:
Определение места расположения распределительного центра: Фирма реализует продукцию на рынках сбыта и имеет постоянных поставщиков в разных регионах. Увеличение объема продаж...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Интересное:
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Подходы к решению темы фильма: Существует три основных типа исторического фильма, имеющих между собой много общего...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
От планирования к расширению возможностей применения
Глава 8. Данные как объект управления
Источники данных и виды информационных активов
Организации, которые не знают, какими данными они располагают, не могут использовать их в качестве актива. В книге Дагласа Лейни «Инфономика: информация как актив: монетизация, оценка, управление» приводится справедливое высказывание директора по информационным технологиям крупной страховой компании: «Глупо, что у кого-то в компании есть опись нашей офисной мебели, но ни у кого нет описи того, какими данными мы располагаем»[322].
При инвентаризации информационных активов целесообразно в первую очередь разделить их на группы в зависимости от источников поступления данных. Лейни выделяет пять основных групп (рис. 8.1).
Операционные данные
Это данные о клиентах, поставщиках, партнерах и сотрудниках, доступные в процессе онлайн-обработки транзакций и (или) полученные из онлайн базы данных аналитической обработки. Часто такие сведения успешно собираются с помощью датчиков в ходе мониторинга процессов предприятий. Например, кассовые аппараты, подключенные к банковской системе, интеллектуальные счетчики, голосовая связь, радиочастотная идентификация и т. д.
«Темные (dark) данные»
Информация, которая не хранится или не собирается организациями специально, а формируется случайно в процессе ведения бизнеса или взаимодействия с сетевыми сервисами и остается в интернет-архивах. Такие данные являются общедоступными и частично структурированными для анализа, включают электронные письма, электронные договоры, документы, мультимедиа, системные журналы и т. д.
|
|

* Laney D. B. Infonomics: How to Monetize, Manage, and Measure Information as an Asset for Competitive Advantage; Routledge; 1st edition, 2017. (Русский перевод: Даглас Лейни. Инфономика: информация как актив: монетизация, оценка, управление. – М.: Точка, 2020. – [Библиотека «Айтеко»].)
Публичные данные
Информация, распространяемая государственными органами (заявления, пресс-релизы, прогноз погоды, сведения о планах муниципального развития; открытые публичные реестры, опубликованные нормативные акты, включая их проекты), одна из наиболее достоверных и чаще всего структурированная. Ценность таких данных раскрывается в совокупности с другими источниками сведений, поскольку позволяет определить направления развития бизнеса или целой индустрии в рамках отдельного города, страны или на международном уровне.
Коммерческие данные
Уже давно в разных отраслях промышленности существуют агрегаторы коммерчески ценной информации. Указанные агрегаторы предоставляют полный доступ к собственным каталогам информации по подписке. Но с учетом перенаправления современных рыночных отношений в сторону открытия информации для потенциальных инвесторов и клиентов многие сведения, представляющие коммерческий интерес, открыто размещаются в цифровой среде. Распространенной стала практика размещения информации об активах на открытых площадках, в особенности если речь идет о принадлежащих компаниям объектах интеллектуальной собственности.
Данные социальных медиа
Вовлеченность бизнеса и частных лиц в функционал крупных социальных сетей создала еще один источник данных о спросе, тенденциях в определенных сегментах рыночных отношений, новых и перспективных продуктах, услугах и компаниях. Сообщения, комментарии, репосты активно используют для выявления и прогнозирования целевых клиентов, коммерческих возможностей, конкурентных отношений, бизнес-рисков и потенциальных партнеров.
Открытые данные
Эта категория данных на рисунке 8.1 не отражена, поскольку она тесно связана с категорией публичных данных. Термин «открытые данные» появился в 1995 году в американском научном сообществе в виде призыва свободно обмениваться данными. Несмотря на общую открытость публичных и открытых данных, между ними существует принципиальная разница. Она заключается в том, что использование публичных данных определяется законом – доступ к ним можно получить, например, по специальному запросу. Суть открытых данных в обратном – данные должны быть опубликованы еще до того, как кому-то понадобятся[323],[324].
|
|
Классификация данных
На практике при организации управления данными их обычно классифицируют по следующим признакам.
По назначению и области применения обычно выделяют:
● метаданные – данные, описывающие структуру и характеристики данных;
● справочные данные – данные из справочников, международных, общероссийских и отраслевых классификаторов и т. п.;
● основные данные – структурированные данные об объектах учета;
● транзакционные данные – сведения, отражающие результат изменения данных, относящиеся к фиксированному моменту времени, не изменяющиеся в будущем;
● данные контроля и аудита – сведения, фиксируемые в различных журналах регистрации[325],[326],[327].
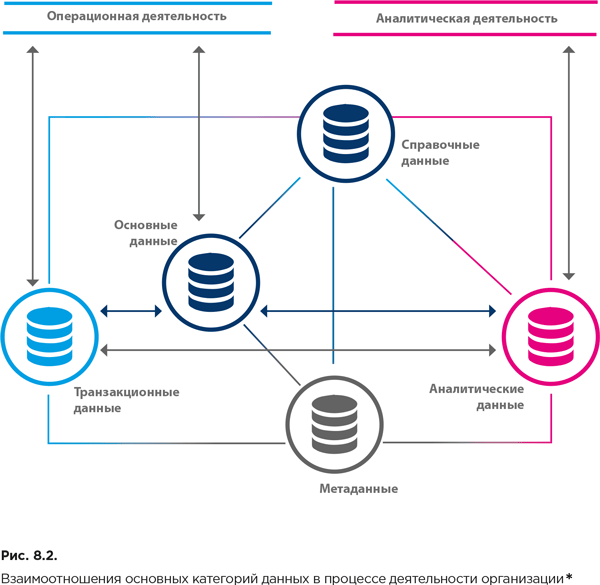
Часто в отдельную категорию относят аналитические данные – эти данные фактически образуются из основных, справочных и транзакционных данных. Они используются в аналитической деятельности организации (рис. 8.2).
На рисунке 8.2 отражены взаимоотношения перечисленных категорий данных в процессе деятельности организации.
* Van Gils B. Data Management: a Gentle Introduction: Balancing Theory and Practice. Van Haren Publishing, 2020.
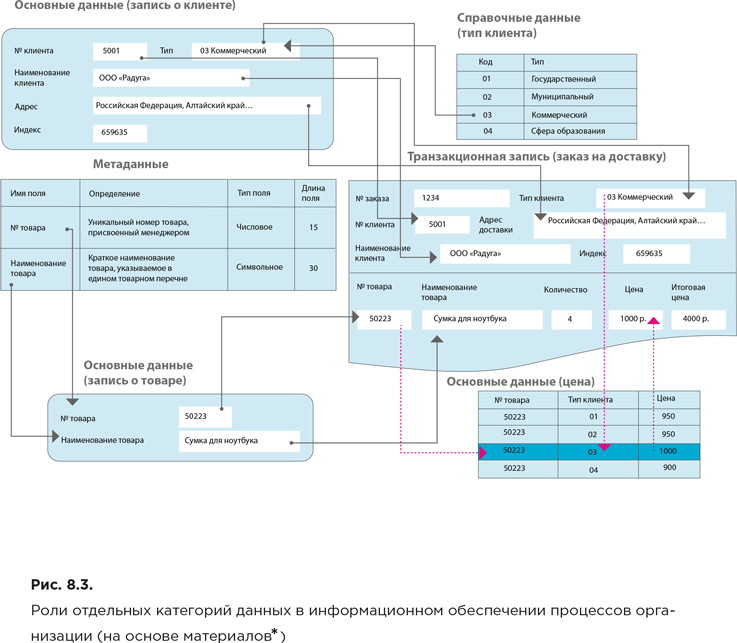
На рисунке 8.3 отражены роли, которые играет каждая из категорий данных в информационном обеспечении процессов организации. Следует обратить внимание на фундаментальную роль справочных и основных данных и на важность поддержания высокого уровня их качества. Например, при наличии ошибок в данных о номере товара или типе клиента цена заказа на доставку может быть определена некорректно (см. связи, отраженные пунктирными стрелками), что может привести к серьезным финансовым последствиям.
* McGilvray D. Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information (TM). Morgan Kaufmann, 2008.
|
|
* Deng Z. MIS2502: Data Analytics: Semi-structured Data Analytics. Fox School of Business. Temple University, 2019. – URL: https://slidetodoc.com/mis-2502-data-analytics-semistructured-data-analytics-zhe/.
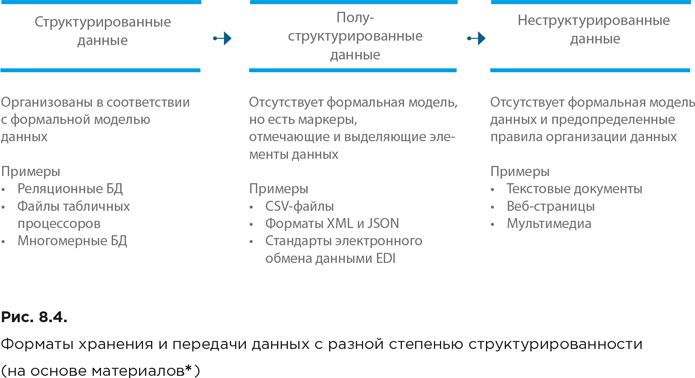
По степени структурированности можно выделить:
● структурированные данные – данные, имеющие строго фиксированную структуру, определяемую формальной моделью данных (например, реляционной схемой[328]);
● полуструктурированные данные – данные, не имеющие строго определенной структуры, но предполагающие наличие установленных правил, позволяющих выделять семантические элементы при их интерпретации (прежде всего, правил расстановки тегов и других маркеров, отмечающих и выделяющих элементы данных);
● неструктурированные данные – данные, произвольные по форме, не имеющие строго определенной структуры и не организованные по определенным правилам.
Схемы, представленные на рисунках 8.2 и 8.3, в основном отражают взаимосвязи между структурированными данными. Однако в деятельности предприятий и учреждений не менее важны данные полуструктурированные и неструктурированные (в частности, к ним относятся отмеченные выше данные контроля и аудита). Они могут быть самыми разнообразными по назначению и области применения. C каждым годом роль этих данных становится все более заметной и существенной.
На рисунке 8.4 приведены примеры форматов хранения и передачи данных по каждой из перечисленных категорий.

* Smith P., Edge J., Parry S., Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
С точки зрения управления данными полезно представить их в виде диаграммы (рис. 8.5), укрупненно отражающей соотношения между основными категориями[329].
Данные, относящиеся к категориям, расположенным сверху, как правило, являются базовыми для формирования данных, относящихся к категориям, расположенным ниже (данные верхних категорий участвуют в формировании данных нижних категорий). Поэтому по мере продвижения вверх по списку категорий требования к качеству соответствующих данных возрастают.
Также по мере продвижения вверх по списку категорий увеличивается продолжительность жизненного цикла данных. При этом при продвижении вниз по списку категорий увеличивается объем самих данных, а также частота их изменений.
|
|
Говоря о данных контроля и аудита, следует отдельно определить такие категории данных, как машинные данные и потоковые данные.
К машинным данным относится информация, автоматически генерируемая компьютером, процессом, приложением или устройством без вмешательства человека. Они становятся одним из основных источников информации, а это в первую очередь относится к данным контроля и аудита.
Потоковые данные могут относиться почти к любой из перечисленных выше категорий, однако у них имеется одно дополнительное свойство. Данные поступают в систему непрерывно по мере возникновения тех или иных событий, а не загружаются в хранилище данных дискретно большими массивами.
К особой категории можно отнести большие данные (big data). Термин «большие данные» связан преимущественно с техническими аспектами формирования и обработки. Он не предполагает конкретные виды данных (эта категория может включать и структурированные, и неструктурированные, и полуструктурированные данные). Традиционно принято определять большие данные по трем признакам (3V): Volume, Velocity, Variety[330],[331]. Коротко о них скажем.
● Volume – объем. К 2020 году общий объем информации, созданный в цифровой среде, достиг 44 ЗБ. По прогнозам Всемирного экономического форума, к 2025 году объем ежедневного интернет-трафика данных по всему миру достигнет 463 ЭБ. С точки зрения наглядной оценки такого огромного объема информации следует отметить, что для его записи потребуется больше 212 млн DVD-дисков. Информация, которая образует объем больших данных, поступает от миллионов используемых электронных сетевых устройств и приложений. Важно иметь в виду, что на этапе накопления big data отбора ненужных данных не производится. Обычные инструменты хранения и анализа не способны справляться с таким объемом.
● Velocity – скорость. Указанные выше объемы данных поступают в обработку в режиме реального времени, в отличие от традиционной обработки пакетов данных. Это означает, что они накапливаются моментально, при этом не имеет значения продолжительность потока самих данных. Таким образом, при работе с большими данными не только фиксируются их потоки, но и производится их запись и обработка в таком виде, чтобы не было потерь.
● Variety – разнообразие. Большие данные формируются из поступающих от различных источников сведений в разнообразных форматах (видеоданные, фотографии, звуковые записи, текстовые сообщения, файлы транзакций, комментарии, использование ссылок и фиксация просмотров страниц и т. д.). Наибольший объем составляют полуструктурированные и неструктурированные данные социальных сетей и социальных медиасервисов. Таким образом, термин big data не относится исключительно к большим данным в понимании объема. Он значительно шире, поскольку подразумевает также большие скорости поступления данных и большое разнообразие источников и форматов получаемой информации.
|
|
Со временем правило 3V в отношении больших данных стали расширять за счет дополнительных признаков[332][333],[334], в частности:
● Veracity – достоверность. Из-за большого объема и вариативности источников поступающих данных сложно проконтролировать их достоверность. Соответствие, точность и правдивость получаемой информации могут быть подтверждены только в результате тщательного анализа и сопоставления.
● Variability – вариативность. При обработке и сопоставлении исходные значения полученных данных могут меняться. В первую очередь данный признак проявляется при работе с речевыми и текстовыми данными. Для понимания точного значения отдельных слов необходима разработка сложных программных продуктов, позволяющих определять смысловую нагрузку исходя не только из прямого значения, но и из контекста.
● Visualization – визуализация. Полученные в результате сбора данные непригодны для восприятия человеком. Поэтому требуется их обработка для представления в доступной форме – визуализация. Характерный пример визуализации данных – построение графиков и диаграмм, отображающих результаты анализа данных. Важна возможность самостоятельной настройки. Необходимые параметры представления пользователи определяют сами, в зависимости от поставленных целей и задач.
● Value – ценность. Потенциальная ценность больших данных крайне высока. На ценность влияют тщательный и точный анализ данных, актуальность информации и полученные в результате визуализации выводы. Наибольший коммерческий и научный интерес представляют те сведения, которые можно использовать для решения текущих задач конкретного пользователя, а также результаты анализа, которые способствуют генерации новых идей.
Наконец, в зависимости от носителя данных, могут быть выделены:
● данные на бумажных носителях;
● данные в электронном виде.
|
|
|

Своеобразие русской архитектуры: Основной материал – дерево – быстрота постройки, но недолговечность и необходимость деления...

Автоматическое растормаживание колес: Тормозные устройства колес предназначены для уменьшения длины пробега и улучшения маневрирования ВС при...

Архитектура электронного правительства: Единая архитектура – это методологический подход при создании системы управления государства, который строится...

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!