Ответы на государственный экзамен для магистров направления 11.04.03
«Конструирование и технология электронных средств»
Вопрос №2 Принципы построения параллельных вычислительных систем.
2.1. Пути достижения параллелизма
В общем плане под параллельными вычислениями понимаются процессы обработки данных, в которых одновременно могут выполняться нескольких машинных операций. Достижение параллелизма возможно только при выполнимости следующих требований к архитектурным принципам построения вычислительной системы:
· независимость функционирования отдельных устройств ЭВМ - данное требование относится в равной степени ко всем основным компонентам вычислительной системы - к устройствам ввода-вывода, к обрабатывающим процессорам и к устройствам памяти;
· избыточность элементов вычислительной системы - организация избыточности может осуществляться в следующих основных формах:
o использование специализированных устройств таких, например, как отдельных процессоров для целочисленной и вещественной арифметики, устройств многоуровневой памяти (регистры, кэш);
o дублирование устройств ЭВМ путем использования, например, нескольких однотипных обрабатывающих процессоров или нескольких устройств оперативной памяти.
Дополнительной формой обеспечения параллелизма может служить конвейерная реализация обрабатывающих устройств, при которой выполнение операций в устройствах представляется в виде исполнения последовательности составляющих операцию подкоманд; как результат, при вычислениях на таких устройствах могут находиться на разных стадиях обработки одновременно несколько различных элементов данных.
При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы выполнения независимых частей программы:
· многозадачный режим (режим разделения времени), при котором для выполнения процессов используется единственный процессор; данный режим является псевдопараллельным, когда активным (исполняемым) может быть один единственный процесс, а все остальные процессы находятся в состоянии ожидания своей очереди на использование процессора; использование режима разделения времени может повысить эффективность организации вычислений (например, если один из процессов не может выполняться из-за ожидании вводимых данных, процессор может быть задействован для готового к исполнению процесса - см. [6, 13]), кроме того, в данном режиме проявляются многие эффекты параллельных вычислений (необходимость взаимоисключения и синхронизации процессов и др.) и, как результат, этот режим может быть использован при начальной подготовке параллельных программ;
· параллельное выполнение, когда в один и тот же момент времени может выполняться несколько команд обработки данных; данный режим вычислений может быть обеспечен не только при наличии нескольких процессоров, но реализуем и при помощи конвейерных и векторных обрабатывающих устройств;
· распределенные вычисления; данный термин обычно используют для указания параллельной обработки данных, при которой используется несколько обрабатывающих устройств, достаточно удаленных друг от друга и в которых передача данных по линиям связи приводит к существенным временным задержкам; как результат, эффективная обработка данных при таком способе организации вычислений возможна только для параллельных алгоритмов с низкой интенсивностью потоков межпроцессорных передач данных; перечисленные условия является характерными, например, при организации вычислений в многомашинных вычислительных комплексах, образуемых объединением нескольких отдельных ЭВМ с помощью каналов связи локальных или глобальных информационных сетей.
В рамках данного пособия основное внимание будет уделяться второму типу организации параллелизма, реализуемому на многопроцессорных вычислительных системах.
Вопрос №3 Эволюция развития компьютерных вычислений. Центры обработки данных (ЦОД), Грид – системы, Cloud computing и их сравнение.
Центры обработки данных (ЦОД), Грид – системы, Cloud computing и их сравнение.
Дата-центр (от англ. data center), или центр (хранения и) обработки данных (ЦОД/ЦХОД) — это специализированное здание для размещения (хостинга) серверного и сетевого оборудования и подключения абонентов к каналам сети Интернет.
Дата-центр исполняет функции обработки, хранения и распространения информации, как правило, в интересах корпоративных клиентов — он ориентирован на решение бизнес-задач путём предоставления информационных услуг. Консолидация вычислительных ресурсов и средств хранения данных в ЦОД позволяет сократить совокупную стоимость владения IT-инфраструктурой за счёт возможности эффективного использования технических средств, например, перераспределения нагрузок, а также за счёт сокращения расходов на администрирование.
Типичный дата-центр состоит из:
— информационной инфраструктуры, включающей в себя серверное оборудование и обеспечивающей основные функции дата-центра — обработку и хранение информации;
— телекоммуникационной инфраструктуры, обеспечивающей взаимосвязь элементов дата-центра, а также передачу данных между дата-центром и пользователями;
— инженерной инфраструктуры, обеспечивающей нормальное функционирование основных систем дата-центра.
— Первый дата-центр (ЦОД) Microsoft был построен в 1989 году. Это был ЦОД первого поколения, сейчас это уже ЦОДы четвертого поколения.
— Для каких задач Microsoft используется ЦОДы?
Во-первых, для обеспечения работоспособности сервисов, которые используют миллионы пользователей по всему миру (XBOX Live, Hotmail, MSN, Zune, SkyDrive и т.п.). Во-вторых, для предоставления глобальной масштабируемой платформы, на основе которой разработчики могут создавать собственные SaaS. Эта платформа Windows Azure.В цифрах и фактах это выглядит примерно следующим образом:

Первое поколение – это сервера, второе поколение – стойки серверов, третье поколение – контейнеры, а четвертое поколение – специальные модули (IT Preassembled Components, ITPAC).
Облачные вычисления
Cloud computing - технология распределённой обработки данных, при которой некие масштабируемые информационные ресурсы и мощности предоставляются как сервис для многочисленных внешних клиентов посредством Интернет-технологий.
Облачные вычисления — модель потребления IT -продуктов и услуг, при которой вычислительные, storage-ресурсы и ядра используемых приложений находятся на стороне cloud-провайдера, в абстрактном дата-центре (отсюда и происходит метафора "облачные").
Сервисы облачных вычислений предполагает управление программным обеспечением Cloud Computing через обычные и привычные любому пользователю веб-браузеры. Облачные вычисления - динамично развивающаяся технология использования информационной инфрастуктуры.
Облачные вычисления применяются выгодно тогда, когда необходимо обеспечить бесперебойность работы или дублировать текущую инфраструктуру. Ресурсы для этого легче и дешевле арендовать, нежели организовывать все с нуля. Кроме того, виртуальная часть, относящаяся к системе cloud computing, может управляться тем же персоналом, что и реальная. Для пользователей же гибридного облака изменения будут незаметны.
Следующие условия необходимо соблюдать для обеспечения надежной системы безопасности облачного сервиса:
1. Должны использоваться криптографические средства обеспечения сохранности данных. Все данные, с которыми клиент работает в рамках сервиса, должны надежно шифроваться.
2. Сам процесс передачи информации от клиента к серверу и обратно тоже должен быть безопасным, то есть необходимо использовать защищенные протоколы передачи данных для доступа к серверу.
Грид
§ Распределенная программно-аппаратная компьютерная среда с принципиально новой организацией вычислений и управления потоками заданий и данных.
§ Компьютерная инфраструктура,предназначенная для объединения вычислительных мощностей различных организаций.
На основе технологии Грид
§ Предполагается формирование региональных, национальных и интернациональных вычислительных компьютерных инфраструктур, предназначенных для решения крупных научно-технических задач.
§ В идеальном случае пользователя не будет интересовать, где находятся используемые им ресурсы.
О технологии Грид
ü виртуализация ресурсов — концепция разделения и совместного использования логических и физических устройств в сети.
ü среда, в которой объединены находящиеся в разных местах глобальной телекомунникационной сети вычислительные ресурсы и которая предназначена для выполнения распределенных приложений, использующих эти ресурсы
ü технология распределенных вычислений в Интернете
ü впервые серьезно ставится вопрос о гарантированном качестве обслуживания.
ü новое поколение Интернета.
— Облака и Грид имеют некие общие черты в их архитектуре и технологии, но отличаются в таких аспектах, как: безопасность, модель программирования, бизнес-модель, вычислительная модель, модель данных, приложений и абстракций.

Резервирование.
Сети Profibus, Modbus, CAN
Резервирование промышленных сетей выполняется обычно одновременно с резервированием контроллеров (см. раздел "Процессорные модули"). Для этого в каждом ПЛК используют два (реже - три) сетевых порта, к одному из них подключают основную промышленную сеть, к другому - резервную (Bertocco). Каждый контроллер имеет средства контроля работоспособности сети и в случае ее отказа переключает свой порт на резервную сеть. В системах с голосованием резервирование выполняется проще: исходящий поток сообщений посылается во все сети одновременно, а входящие потоки из всех сетей проходят через схему голосования (см. раздел "Общие принципы резервирования").
Для контроллеров, имеющих один сетевой порт и не предназначенных для работы в резервированных сетях, выпускаются специальные модули резервирования (см. www.abb.com), которые имеют один разъем (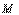 на рис. 8.17) для подключения к порту оконечного устройства, например, ПЛК, и два разъема (
на рис. 8.17) для подключения к порту оконечного устройства, например, ПЛК, и два разъема ( и
и  ) для подключения к основной и резервной сети (рис. 8.17). Модули могут работать в многомастерных сетях как с ведущими, так и с ведомыми устройствами. Ведомых устройств, подключаемых к одному модулю резервирования, может быть несколько (
) для подключения к основной и резервной сети (рис. 8.17). Модули могут работать в многомастерных сетях как с ведущими, так и с ведомыми устройствами. Ведомых устройств, подключаемых к одному модулю резервирования, может быть несколько ( на рис. 8.17). Модуль работает как коммутируемый повторитель интерфейса, одновременно контролируя исправность сети. Отказ обнаруживается по первому символу в передаваемом сообщении и при его появлении модуль переключается на резервный порт.
на рис. 8.17). Модуль работает как коммутируемый повторитель интерфейса, одновременно контролируя исправность сети. Отказ обнаруживается по первому символу в передаваемом сообщении и при его появлении модуль переключается на резервный порт.
Основной проблемой резервирования сетей методом замещения является обнаружение отказа. Поскольку после отказа (например, обрыва) сети на некотором участке доставка сообщений к отсоединенной части сети невозможна, обнаружение отказа должно выполняться каждым участником сети автономно. Но это возможно только в многомастерных сетях или в сетях, имеющих специальные аппаратные средства контроля.
Протоколы резервирования промышленных сетей являются узкоспециализированными закрытыми разработками фирм-производителей контроллеров и в общедоступной литературе не описаны.

|
Рис. 8.17. Резервирование промышленной сети с помощью коммутации портов;  ... ... 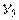 - оконечные устройства, - оконечные устройства, 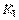 ... ...  - модули резервирования сети - модули резервирования сети
|
Сети Ethernet
Резервированию в промышленных сетях Ethernet с коммутаторами посвящена серия стандартов IEEE [IEEE, IEEE]. Однако первоначально они были предназначены только для исключения замкнутых контуров в сетях, поэтому требования к быстродействию алгоритмов учтены не были. В связи с резким ростом спроса на промышленный Ethernet (рост около 50% в год c 2004 г. [Prytz]) возросли требования ко времени переключения на резерв. Поэтому в 2005 г. началась работа над новым стандартом IEC 62439 “ High Availability Automation Networks” ("Сети промышленной автоматизации с высокой готовностью"), которая была инициирована комитетом IEC по цифровой коммуникации TC65C.
Основной проблемой при резервировании сетей Ethernet с коммутаторами является устранение замкнутых логических контуров (петель, циклов). Логические петли не допускаются потому, что при их наличии коммуникационные пакеты могли бы вечно путешествовать по сети, ограничивая ее пропускную способность. При возрастании трафика был бы возможен также отказ в обслуживании из-за превышения пропускной способности сети. Кроме того, в таблице MAC-адресов коммутаторов появились бы одни и те же адреса для разных портов.
Для исключения логических петель служит стандартизованный алгоритм STP [IEEE], который выполняет блокировку портов коммутатора, через которые петли замыкаются. После появления промышленного Ethernet оказалось, что алгоритм STP позволяет искусственно вводить в сеть резервные ветви, которые, однако, не создают логических петель благодаря STP-алгоритму. При отказе некоторых ветвей протокол STP выбирает новые сетевые маршруты, в которых участвуют зарезервированные ранее связи.
Существует несколько методов резервирования промышленного Ethernet:
o агрегирование линий связи;
o резервирование на основе STP и RSTP протоколов;
o организация в сети физического кольца;
o полное резервирование всей сети.
Первые два метода стандартизованы, вторые два являются нестандартными разработками фирм-производителей и многие из них защищены патентами.
Метод агрегирования
Метод агрегирования линий связи описан в стандарте IEEE 802.3ad "Aggregation of Multiple Link Segments", который является разделом общего стандарта IEEE 802.3 [IEEE]. Этот метод использует два и более параллельных кабелей и портов для каждой линии связи. Объединение нескольких физических линий связи в один логический канал осуществляется с помощью протокола Link Aggregation Control Protocol (LACP). При этом группа (агрегат) линий связи и портов представляется одним логическим сервисным интерфейсом с одним MAC-адресом. В протоколе LACP полные Ethernet фреймы попеременно отсылаются по параллельным линиям связи и объединяются в приемнике. Пропускная способность такого агрегированного канала оказывается прямо пропорциональна количеству физических линий. При отказе одной линии данные пересылаются по другой. Этот стандарт поддерживается многими производителями Ethernet коммутаторов.
Метод резервирования, изложенный в стандарте IEEE 802.3ad, предполагает, что все агрегированные линии связи должны исходить из одного и того же коммутатора, т.е. сеть должна иметь топологию звезды. Для устранения этого ограничения фирмой Nortel были предложены три модификации метода агрегирования: SMLT ("Split Multi-Link Trunking"), DSMLT (Distributed Split Multi-Link Trunking) и R-SMLT ("Routed-SMLT) (см. www.nortel.com). Модификации этого метода предложены также фирмами Cisco и Adaptec, однако они несовместимы между собой и со стандартом.

|
| Рис. 8.18. Резервирование в сети Ethernet методом агрегирования линий связи
|
Метод агрегирования используется для резервирования соединений между коммутаторами, между коммутатором и сервером, а также между двумя компьютерами. Для дублирования связи между ПЛК и коммутатором ПЛК должен иметь два Ethernet-порта и драйвер, поддерживающий протокол LACP (IEEE 802.3ad), который предоставляет операционной системе один сетевой порт, физически состоящий из двух линий связи (рис. 8.18). При использовании 4-кратного резервирования связи между сервером и коммутатором (рис. 8.18) в сервер вставляется специальная 4-портовая Ethernet-карта с соответствующим драйвером, который заменяет 4 физических Ethernet порта одним логическим.
Достоинством метода является увеличение пропускной способности сети, возможность добавления произвольного количества линий связи для согласования пропускной способности разных каналов, малое время восстановления после отказа. Однако для резервирования сети в целом необходимо удвоенное количество кабелей и коммутаторов, что может быть неоправданно дорого. Кроме того, практически используемые схемы агрегирования часто не соответствуют стандартам IEEE, а оборудование разных производителей может быть несовместимым.
Метод агрегирования в соответствии с IEEE 802.3ad обеспечивает резервирование только линий связи; коммутаторы или сетевые контроллеры подключенного к сети оборудования остаются нерезервированными. Однако некоторые фирмы (см., например, www.syskonnect.com) предлагают дополнительное программное обеспечение, позволяющее объединять в один логический порт несколько каналов, проходящих через разные коммутаторы, которые, таким образом, оказываются резервированными.
Метод физического кольца
 а)
а)
|
 б)
б)
|
Рис. 8.19. Метод физического кольца для резервирования линии передачи (а) и линии передачи с коммутатором (б); ...  - коммутаторы, - коммутаторы,  - оконечные устройства (компьютеры, серверы, ПЛК) - оконечные устройства (компьютеры, серверы, ПЛК)
|
Методы резервирования, основанные даже на усовершенствованном протоколе RSTP, имеют слишком большое время переключения на резерв (до 2 сек. [Prytz]). В то же время ряд приложений требует сокращения этого времени до единиц миллисекунд (как, например, в робототехнике) или до долей секунды (во многих химических технологических процессах). Поэтому некоторые фирмы разработали собственные нестандартные методы резервирования, которых в настоящее время насчитывается более 15 [Prytz].
В основе этих методов лежит использование сети с кольцевой физической топологией. Одна из ветвей сети блокируется коммутатором (мастером на рис. 8.19-а) и поэтому в режиме нормального функционирования сеть приобретает логическую шинную топологию. В случае отказа одной из ветвей мастер включает резервный порт. При этом подключается резервная ветвь и граф сети вновь становится связным, т. е. работоспособность сети оказывается полностью восстановленной.
Существует два метода обнаружения отказа в сети: циклический опрос и отправка уведомления об отказе.
При циклическом опросе мастер периодически посылает в сеть специальный тестирующий пакет через свой основной порт. При нормальном функционировании сети пакет проходит по кольцу и возвращается к мастеру через его резервный порт. Если пакет не приходит за время таймаута, мастер считает, что в сети произошел отказ и немедленно включает резервный порт, затем очищает свою таблицу адресов и рассылает всем коммутаторам инструкцию сделать то же самое. После очистки таблиц адресов все коммутаторы автоматически выполняют "обучение" (обновление таблицы адресов). В результате сеть вновь становится полнофункциональной, но уже с новой ветвью и новыми таблицами адресов в коммутаторах. Разрыв 1 на рис. 8.19-а остается в сети до тех пор, пока не будет выполнен ремонт отказавшей ветви.
В методе уведомления об отказе циклический опрос не выполняется. Вместо этого каждый коммутатор самостоятельно контролирует целостность примыкающих к нему связей и при обнаружении отказа сообщает об этом мастеру с помощью уведомления. Далее мастер поступает точно так, как в методе циклического опроса.
После ремонта или замены отказавшей ветви она обнаруживается тем же методом тестирования кольца. Если связь по кольцу восстановлена, то мастер сразу же блокирует свой резервный порт (который был задействован на время выполнения ремонта), сбрасывает таблицу адресов и инструктирует оставшиеся коммутаторы сделать то же самое. В результате все коммутаторы обновляют таблицы адресов для сети с восстановленной ветвью.
| Табл. 8.43. Параметры некоторых методов резервирования сетей Ethernet [Prytz]
|
| Протокол
| Разработчик, стандарт
| Время переключения на резерв
| Топология
| Наличие стандарта
|
| STP
| IEEE 802.1D
| 30 с
| Любая
| Есть
|
| RSTP
| IEEE 802.1w
| 2 с
| Любая
| Есть
|
| Hyper Ring
| Hirschmann
| 0,3 с
| Кольцевая
| Нет
|
| Turbo Ring
| Moxa
| 0,15...0,3 с
| Кольцевая
| Нет
|
| Rapid Ring
| Contemporary Controls
| 0,3 с
| Кольцевая
| Нет
|
| S-Ring
| GarretCom
| 0,25 с
| Кольцевая
| Нет
|
| Real time Ring
| Sixnet
| 0,08 с
| Кольцевая
| Нет
|
| Ring Healing
| N-Tron
| 0,3 с
| Кольцевая
| Нет
|
| Super Ring
| Korenix
| 0,3 с
| Кольцевая
| Нет
|
| Self healing Ring
| TC Communications
| 0,25 с
| Кольцевая
| Нет
|
| Jet Ring
| Volktek
| 0,3 с
| Кольцевая
| Нет
|
Метод физического кольца имеет два существенных достоинства: во-первых, он предельно экономичен, поскольку способен восстановить работу сети при отказе любой ее ветви практически без затрат оборудования (дополнительно требуется всего один кабель для замыкания кольца и два лишних порта в двух коммутаторах). Во вторых, он позволяет примерно на порядок сократить время восстановления сети после отказа по сравнению со стандартным методом, использующим RSTP протокол (см. табл. 8.43).
К недостаткам метода относится неудобство кольцевой архитектуры, невозможность резервирования коммутаторов и сетевых адаптеров, а также ветвей, идущих от коммутаторов к конечным устройствам. При отказе коммутатора на рис. 8.19-а сеть оказывается разорванной и устройства, подключенные через коммутатор , становятся недоступны. Аналогично, рассмотренный метод резервирования не дает эффекта при отказе связи 3 на рис. 8.19-а.
Два последних недостатка можно преодолеть, если в методе физического кольца использовать оконечные сетевые устройства с двумя Ethernet-портами (устройство на рис. 8.19-б), и каждый из этих портов подключить к двум соседним коммутаторам и  . При отказе коммутатора
. При отказе коммутатора  на рис. 8.19-б мастер включает резервную ветвь и в сети появляется резервный путь к устройству через резервную ветвь и коммутаторы , .
на рис. 8.19-б мастер включает резервную ветвь и в сети появляется резервный путь к устройству через резервную ветвь и коммутаторы , .
К недостаткам методов физического кольца относится также отсутствие стандартов и, как следствие, несоответствие идеологии открытых систем.
Полное резервирование сети
Наименьшее время переключения на резерв предоставляет метод полного дублирование всей сети целиком. Вторым его достоинством является живучесть при отказах не только соединений между коммутаторами, но также и самих коммутаторов, сетевых портов устройств и линий связи устройств с коммутатором. Недостатком является высокая цена, поскольку метод предполагает, что все сетевое оборудование используется в удвоенном количестве.

|
| Рис. 8.20. Полное резервирование сети Ethernet
|
На рис. 8.20 показан пример дублированной сети с шинной топологией. Здесь ... - коммутаторы основной сети,  ...
... 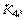 - коммутаторы дублирующей сети. Каждое оконечное устройство имеет по два Ethernet-порта, один из которых подключается к основной сети, второй - к резервной. При любом отказе в основной сети (обрыв 1 в ветви между коммутаторами, отказ 2 коммутатора, обрыв 3 ветви между портом оконечного устройства и коммутатором на рис. 8.20) связь по сети восстанавливается путем переключения портов оконечных устройств на резервную сеть. Переключение выполняется быстро, поскольку метод не требует построения дерева, как в алгоритме STP.
- коммутаторы дублирующей сети. Каждое оконечное устройство имеет по два Ethernet-порта, один из которых подключается к основной сети, второй - к резервной. При любом отказе в основной сети (обрыв 1 в ветви между коммутаторами, отказ 2 коммутатора, обрыв 3 ветви между портом оконечного устройства и коммутатором на рис. 8.20) связь по сети восстанавливается путем переключения портов оконечных устройств на резервную сеть. Переключение выполняется быстро, поскольку метод не требует построения дерева, как в алгоритме STP.
Разновидностью полного резервирования является одновременное резервирование сети и оконечных устройств [Moxa]. В этом случае получаются две полностью независимые системы автоматизации и резервированным оказывается не только сетевое оборудование, но и вся система. Для выбора одной из сетей и обнаружения отказа необходимы средства диагностики, которые могут быть реализованы на основе стандарта IEEE 802.1p/Q [Moxa].
Ответы на государственный экзамен для магистров направления 11.04.03
«Конструирование и технология электронных средств»
Вопрос №1 Основные технологии организации распределенных вычислительных систем.
1.1 Определение распределенной вычислительной системы
«Распределенной вычислительной системой можно назвать такую систему, в которой отказ компьютера, о существовании которого вы даже не подозревали, может сделать ваш собственный компьютер непригодным к использованию».
Это определение он дал в мае 1987 года, в своем письме коллегам по поводу очередного отключения электроэнергии в машинном зале.
Эндрю Таненбаум[1], в своем фундаментальном труде «Распределённые системы. Принципы и парадигмы» [2] предложил следующее (чуть более строгое) определение:
«Распределенная вычислительная система (РВС) – это набор соединенных каналами связи независимых компьютеров, которые с точки зрения пользователя некоторого программного обеспечения выглядят единым целым».
В этом определении фиксируются два существенных момента: автономность узлов РВС и представление системы пользователем, как единой структуры. При этом, основным связующим звеном распределенных вычислительных систем является программное обеспечение.
Промежуточное программное обеспечение
Распределенная вычислительная система представляет собой программноаппаратный комплекс, ориентированный на решение определенных задач. С одной стороны, каждый вычислительный узел является автономным элементом. С другой стороны, программная составляющая РВС должна обеспечивать пользователям видимость работы с единой вычислительной системой. В связи с этим выделяют следующие важные характеристики РВС:
- возможность работы с различными типами устройств:
- с различными поставщиками устройств;
- с различными операционными системами,
- с различными аппаратными платформами.
Вычислительные среды, состоящие из множества вычислительных систем на базе разных программно-аппаратных платформ, называются гетерогенными;
- возможность простого расширения и масштабирования;
- перманентная (постоянная) доступность ресурсов (даже если некоторые элементы РВС некоторое время могут находиться вне доступа);
- сокрытие особенностей коммуникации от пользователей.
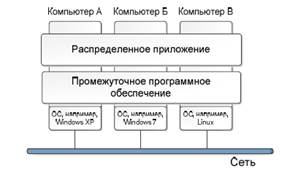
Для обеспечения работы гетерогенного оборудования РВС в виде единого целого, стек программного обеспечения (ПО) обычно разбивают на два слоя. На верхнем слое располагаются распределенные приложения, отвечающие за решение определенных прикладных задач средствами РВС. Их функциональные возможности базируются на нижнем слое - промежуточном программном обеспечении (ППО). ППО взаимодействует с системным ПО и сетевым уровнем, для обеспечения прозрачности работы приложений в РВС (см. рис. 1).
Для того чтобы РВС могла быть представлена пользователю как единая система, применяют следующие типы прозрачности в РВС:
- прозрачный доступ к ресурсам - от пользователей должна быть скрыта разница в представлении данных и в способах доступа к ресурсам РВС;
- прозрачное местоположение ресурсов - место физического расположения требуемого ресурса должно быть несущественно для пользователя;
- репликация - сокрытие от пользователя того, что в реальности существует более одной копии используемых ресурсов;
-
- параллельный доступ - возможность совместного (одновременного) использования одного и того же ресурса различными пользователями независимо друг от друга. При этом факт совместного использования ресурса должен оставаться скрытым от пользователя;
- прозрачность отказов - отказ (отключение) каких-либо ресурсов РВС не должен оказывать влияния на работу пользователя и его приложения.
1.2 Терминология РВС
1. Ресурсом называется любая программная или аппаратная сущность, представленная или используемая в распределенной сети. Например, компьютер, устройство хранения, файл, коммуникационный канал, сервис и т.п.
2. Узел - любое аппаратное устройство в распределенной вычислительной системе.
3. Сервер - это поставщик информации в РВС (например, веб-сервер).
4. Клиент - это потребитель информации в РВС (например, веб-браузер).
5. Пир - это узел, совмещающий в себе как клиентскую, так и серверную часть (т.е. и поставщик, и потребитель информации одновременно).
6. Сервис - это сетевая сущность, предоставляющая определенные функциональные возможности [30] (например, веб-сервер может предоставлять сервис передачи файлов по протоколу HTTP). В рамках одного узла могут предоставляться несколько различных сервисов.
На рисунке 2 приведена схема, устанавливающая взаимоотношения между
данными терминами. Из схемы видно, что каждый компьютер или устройство представляет собой сущность в распределенной вычислительной системе в виде узла. При этом на каждом узле может располагаться несколько клиентов, серверов, сервисов или пиров. Важно заметить, что любой узел, сервер, пир или сервис (но не клиент!) являются ресурсами распределенной вычислительной системы.

Рис. 2. Схема взаимоотношений между терминами РВС
Сервис получает запрос на предоставление определенных данных (почти как аргументы, передаваемые при вызове локальной функции) и возвращает ответ. Таким образом, сервис можно определить как некую замену вызова функции на локальном компьютере. Существует множество технологий, обеспечивающих создание и сопровождение сервисов в распределенных вычислительных системах: технология XML веб-сервисов, сервисы REST и др.
1.3 Классификация РВС
Выделяют следующие признаки классификации РВС по шкале «централизованный - децентрализованный»:
- методы обнаружения ресурсов;
- доступность ресурсов;
- методы взаимодействия ресурсов.
Существует множество различных технологий, обеспечивающих поиск и обнаружение ресурсов в РВС (например, такие службы обнаружения ресурсов как DNS, Jini Lookup, UDDI и др.). Примером централизованного метода обнаружения ресурсов может служить служба DNS (англ. Domain Name System - система доменных имен). Данная служба работает по принципам, чрезвычайно похожим на принцип работы телефонной книги. На основе указанного имени сайта (например, www.susu.ac.ru) DNS возвращает его IP-адрес (например, 85.143.41.59). Таким образом, сервер DNS представляет собой большую базу данных ресурсов, расположенных в РВС. Существует ограниченное количество серверов, которые предоставляют службу DNS. Обычно пользователь указывает ограниченное количество (1 или 2) таких серверов для работы. И если указанные сервера отключаются, то процесс обнаружения ресурсов останавливается, если вручную не указать альтернативные сервера.
При использовании децентрализованного метода обнаружения ресурсов (например, в сети Gnutella [33]) запрос на поиск отправляется всем узлам, известным отправителю. Эти узлы производят поиск ресурса у себя, и транслируют запрос далее. Таким образом, отсутствуют выделенные узлы для обнаружения и централизованное хранилище информации о ресурсах, доступных в сети.
Другим важным фактором является доступность ресурсов РВС. Примером централизованной доступности ресурсов в РВС может являться технология веб-сервисов. Существует только один сервер с выделенным IP-адресом, который предоставляет определенный веб-сервис или сайт. Если данный узел выйдет из строя или будет отключен от сети, данный сервис станет недоступна. Естественно, можно применить методы репликации для расширения доступности определенного сайта или сервиса, но доступность определенного IP-адреса останется прежней.
Существуют системы, предоставляющие децентрализованные подходы к доступности ресурсов посредством множественного дублирования сервисов, которые могут обеспечить функциональность, необходимую пользователю. Наиболее яркими примерами децентрализованной доступности ресурсов могут служить одноранговые вычислительные системы (BitTorrent, Gnutella, Napster), где каждый узел играет роль, как клиента, так и сервера, который может предоставлять ресурсы и сервисы, аналогичные остальным устройствам данной сети (поиск, передача данных и др.)
Еще одним критерием классификации РВС могут служить методы взаимодействия узлов. Централизованный подход к взаимодействию узлов основан на том, что взаимодействие между узлами всегда происходит через специальный центральный сервер. Таким образом, один узел не может обратиться к другому непосредственно.
Децентрализованный подход к взаимодействию реализуется в одноранговых вычислительных системах. Такой подход основывается на прямом взаимодействии между узлами РВС, т.к. каждый узел играет как роль клиента, так и роль сервера.
1.4 Связь в РВС
Понятие «распределенная вычислительная система» подразумевает, что компоненты такой системы распределены, т.е. удалены друг от друга. Очевидно, что функционирование подобных систем невозможно без эффективной связи между ее компонентами.
Задачи организации обмена между распределенными (территориально, административно и т.д.) компонентами давно и в значительной мере успешно решаются в вычислительных сетях, и, естественно, что РВС используют наработанный опыт.
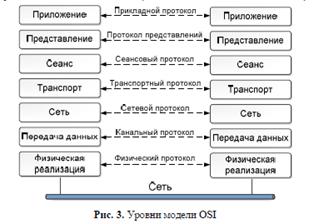
Взаимодействие в вычислительных сетях базируется на протоколах. Протокол - это набор правил и соглашений, описывающих процедуру
взаимодействия между компонентами системы (в том числе и вычислительной).
Если система поддерживает определённый протокол, она, с большой долей вероятности, окажется способна взаимодействовать с другой системой, которая так же поддерживает данный протокол. В области вычислительных коммуникаций уже длительное время существует общепринятая система протоколов - сетевая модель OSI (англ. Open Systems Interconnection basic reference model - базовая эталонная модель взаимодействия открытых систем). Эта модель представляет собой стек протоколов разного уровня, которые позволяют описать практически все аспекты взаимодействия компонентов РВС.







