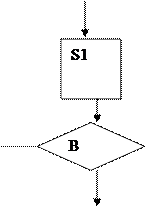
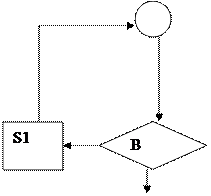
Определение алгоритма.
Термин происходит от имени средневекового математика(787-850) Абу Джафара ибн Мусы аль-Хорезми. Редакция последней части имени ученого в европейских языках привела к образованию термина «алгорифм» или «алгоритм». Европейцы, начавшие осваивать современную десятичную систему счисления в XII в.(был выполнен латинский перевод его математического трактата), знакомились с трудами арабских ученых, и труд упомянутого выше жителя Хорезма, посвященный правилам счета в десятичной системе счисления и правила арифметики многозначных чисел, был широко известен. Поэтому и наполнение термина «алгоритм» было следующим: операции над числами. Сложение, вычитание, умножение столбиком, деление уголком многозначных чисел – вот первые алгоритмы в математике.
Современное содержание понятия алгоритма можно определить следующим образом.
Алгоритм – четкая система правил, которая задает последовательность действий над некоторыми объектами и после конечного числа шагов приводят к достижению поставленной цели.
Когда вы даете кому‑то инструкции о том, как отремонтировать газонокосилку, испечь торт, вы тем самым задаете алгоритм действий. Конечно, подобные бытовые алгоритмы описываются неформально, например, так:
Проверьте, находится ли машина на стоянке.
Убедитесь, что машина поставлена на ручной тормоз.
Поверните ключ.
И т.д.
При этом по умолчанию предполагается, что человек, который будет следовать этим инструкциям, сможет самостоятельно выполнить множество мелких операций, например, отпереть и открыть дверь, сесть за руль, пристегнуть ремень, найти ручной тормоз и так далее.
Если же составляется алгоритм для исполнения компьютером, вы не можете полагаться на то, что компьютер поймет что‑либо, если это не описано заранее. Словарь компьютера (язык программирования) очень ограничен и все инструкции для компьютера должны быть сформулированы на этом языке. Поэтому для написания компьютерных алгоритмов используется формализованный стиль.
Интересно попробовать написать формализованный алгоритм для обычных ежедневных задач. Например, алгоритм вождения машины мог бы выглядеть примерно так:
Если дверь закрыта:
Вставить ключ в замок
Повернуть ключ
Если дверь остается закрытой, то:
Повернуть ключ в другую сторону
Повернуть ручку двери
И т.д.
Этот фрагмент «кода» отвечает только за открывание двери; при этом даже не проверяется, какая дверь открывается. Если дверь заело или в машине установлена противоугонная система, то алгоритм открывания двери может быть достаточно сложным.
Формализацией алгоритмов занимаются уже тысячи лет. За 300 лет до н.э. Евклид написал алгоритмы деления углов пополам, проверки равенства треугольников и решения других геометрических задач. Он начал с небольшого словаря аксиом, таких как «параллельные линии не пересекаются» и построил на их основе алгоритмы для решения сложных задач.
Формализованные алгоритмы такого типа хорошо подходят для задач математики, где должна быть доказана истинность какого‑либо положения или возможность выполнения каких‑то действий, скорость же исполнения алгоритма не важна. Для выполнения реальных задач, связанных с выполнением инструкций, например задачи сортировки на компьютере записей о миллионе покупателей, эффективность выполнения становится важной частью постановки задачи.
Алгоритм Евклида был предназначен для нахождения наибольшего делителя пары натуральных чисел (m,n).
Алгоритм Евклида.
1. {Нахождение остатка } r:=m mod n.
2. {Замена} m:=n; n:=r.
3. {Остановка?} Если 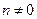 , то переход к п.1
, то переход к п.1 
4. {Остановка процесса} m - искомое число.
Представленное описание алгоритма – это последовательность шагов, направленных на достижение некоторого результата (наибольшего общего делителя).
Алгоритмический процесс – процесс последовательного преобразования конструктивных объектов (слов, чисел, пар слов, пар чисел, предложений и т.п.), происходящий дискретными «шагами». Каждый шаг состоит в смене одного конструктивного объекта другим.
Поскольку алгоритмы могут применяться к весьма произвольным объектам (числам, буквам, словам, графам, логическим выражениям и т.д.) в определении алгоритма используется специальный термин – «конструктивный объект», объединяющий в себе все эти возможные случаи.
Так, в алгоритме Евклида под конструктивными объектами можно понимать пары чисел.
Смена конструктивных объектов в алгоритме Евклида может быть представлена следующим образом (для пары m=10, n=4):
(10,4)→(4,2)→(2,0).
Как правило, для заданного алгоритма можно выделить семь характеризующих его независимых параметров:
-совокупность возможных исходных данных
- совокупность возможных промежуточных результатов
- совокупность результатов
- правило начала
- правило непосредственной переработки
- правило окончания
- правило извлечения результата
Для алгоритма Евклида эти семь параметров могут быть определены следующим образом:
1.  .
.
2.  .
.
3.  .
.
4. Ввести пару чисел (m,n) таких, что 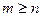 .
.
5. 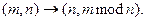
6. Если в паре (m,n) n=0, то останов.
7. Результатом является первое число пары (m,0).
Вывод m на устройство вывода.
В теории алгоритмов изучаются алгоритмы, заданные в строгом, формализованном виде. Для алгоритма Евклида эта форма может быть такой:
|
| | Определяется решающее правило (функция) – 
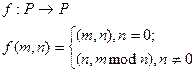
| |
Поскольку далее будут интересовать практические аспекты (а не теоретические) задания (описания) алгоритмов, на приведенной формализации и остановимся. На практике в программировании очень часто используется задание алгоритмов в виде блок-схем.

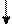 Блок-схема – это ориентированный граф, вершины которого могут быть одного из трех типов:
Блок-схема – это ориентированный граф, вершины которого могут быть одного из трех типов:
Композиция.
Выбор (альтернатива)


 Итерация (повторение)
Итерация (повторение)
T T
F F
Функциональная вершина используется для представления функции 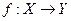
Предикатная вершина используется для представления функции (или предиката) 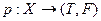 т.е. логического выражения, передающего управление по одной из двух возможных ветвей.
т.е. логического выражения, передающего управление по одной из двух возможных ветвей.
Объединяющая вершина представляет передачу управления от одной из двух входящих ветвей к одной выходящей ветви.
Структурная блок-схема - это блок-схема, которая может быть выражена как композиция из четырех элементарных блок-схем.
Любая программа для машины может быть представлена структурной блок-схемой.
Важной особенностью приведенных структур является то, что они имеют один вход и один выход.
Структурное программирование – процесс разработки алгоритмов с помощью блок-схем.
В более широком плане структурное программирование допускает большое разнообразие элементарных структур управления, чем предложенные четыре. Причиной для расширения множества структур является требование удобства и естественности.
Привести примеры блок схемы – с использованием оператора CАSE, использование нескольких условий, go to.
Программирование сверху вниз - это процесс пошагового разбиения алгоритма на все более мелкие части с целью получения таких элементов, для которых можно написать конкретные команды.
Структурное программирование сверху вниз – это процесс программирования сверху вниз, ограниченный использованием структурных блок-схем.
Метод частных целей.
Этот метод имеет весьма общую формулировку: «Необходимо свести трудную задачу к последовательности более простых задач».
Приведенная рекомендация выглядит столь естественной и разумной, что вряд ли вызовет у кого-нибудь возражения. Более того, любой человек очень часто использует этот метод решения стоящих перед ним задач, при этом даже не догадываясь или не отдавая себе отчета об имеющемся для него (метода) названии. С другой стороны, в конкретной сложной задаче часто очень трудно указать способ ее разбиения на набор более простых задач. Здесь большое значение имеет опыт и руководство специалиста. Тем не менее несмотря на общность метода и отсутствие точного «рецепта» его применения очень важно освоить этот метод, так как он лежит в основе решения многих задач и по своей сути составляет основу алгоритмизации и программирования. Именно с вопроса «Можно ли данную задачу разбить на последовательность (набор) более простых?» и нужно начинать разработку простого алгоритма.
Метод подъема.
Этот метод как и предыдущий, можно отнести к одному из общих «рецептов» разработки алгоритмов. Его суть заключается в следующей процедуре. Алгоритм начинается с принятия начального предположения или построения начального решения задачи. Затем начинается (насколько возможно) быстрое движение «вверх» от начального уровня по направлению к лучшим решениям. Когда алгоритм достигает точки, из которой болше невозможно двигаться «наверх» он останавливается.
Алгоритмы ветвей и границ.
Алгоритмы ветвей и границ. Как и большая часть алгоритмов. Описанных ранее. Применяются для решения переборных задач. Как и алгоритм с отходами, они исследуют древовидную модель пространства решений и ориентированны на поиск в некотором смысле оптимального решения (из конечного множества возможных решений).
Определение спецификаций.
В определенной степени этот этап можно рассматривать как формулировку выводов, следующих из результатов предыдущего этапа. Требования к программе должны быть представлены в виде ряда спецификаций, явно определяющих рабочие характеристики будущей программы. В число таких характеристик могут входить скорость выполнения, объем потребляемой памяти, гибкость применения. И др.
Проектирование.
На этом этапе создается общая структура программы, которая должна удовлетворять спецификациям; определяются общие принципы управления и взаимодействия между различными компонентами программы.
Кодирование.
Заключается в переводе на язык программирования конструкций, записанных на языке проектирования.
Тестирование.
На этом этапе производится всесторонняя проверка программ. Существуют три аспекта проверки программы:
- правильность
- эффективность реализации
- вычислительная сложность
Проверка правильности удостоверяет, что программа делает в точности то, для чего она была предназначена. Математическая безупречность алгоритма не гарантирует правильности его перевода в программу. Аналогично, ни отсутствие диагностических сообщений компилятора, ни разумный вид получаемых результатов не дают достаточной гарантии правильности программы. Как правило, проверка правильности заключается в разработке и проведении набора тестов. Кроме этого, для расчета программ иногда можно сверить получаемые решения с уже известным решением. В общем случае, нельзя дать общего решения для проверки на правильность программы.
Проверка вычислительной сложности, как правило, заключается в экспериментальном анализе сложности алгоритма или экспериментальном сравнении двух алгоритмов и более, решающих одну и ту же задачу.
Проверка эффективности реализации направлена на отыскание способа заставить правильную программу работать быстрее или расходовать меньше памяти. Чтобы улучшить программу, пересматриваются результаты реализации в процессе построения алгоритма. Не рассматривая все возможные варианты и направления оптимизации программ приведем некоторые полезные способы направленные на увеличение скорости выполнения программ.
1. сложение и вычитание выполняются быстрее чем умножение и деление. Целочисленная арифметика быстрее арифметики вещественных чисел.
2. удаление избыточных вычислений.
3. основан на способности некоторых компиляторов строить коды для вычисления так, что вычисления прекращаются если результат становиться очевидным.
4. исключение циклов.
Это далеко не полный перечень способов оптимизации. Стоит заметить, что не всегда стоит увлекаться погоней за быстродействием. Если результат незначителен то лучше предпочесть ясность и читабельность программы.
Сопровождение.
Это этап эксплуатации системы. Каким бы изощренным не было тестирование программ. К сожалению, в больших программных комплексах чрезвычайно тяжело устранить абсолютно все ошибки. Устранение обнаруженных при эксплуатации ошибок – первейшая задача этого этапа. Однако это далеко не все, что выполняется при сопровождении. Выполняемый в ходе сопровождения анализ опыта эксплуатации программы позволяет обнаруживать «узкие места» или неудачные проектные решения в тех или иных частях программного комплекса. В результате такого анализа может быть принято решение о проведении работ по совершенствованию разработанной системы. Сопровождение может включать в себя проведение консультаций, обучение пользователей системы, оперативное снабжение пользователей информацией о новых версиях системы и т.п. качественное проведение этапа сопровождения в большей степени определяет коммерческий успех программного продукта.
Пространство — время
Многие алгоритмы предоставляют выбор между скоростью выполнения и используемыми программой ресурсами. Задача может выполняться
быстрее, используя больше памяти, или наоборот, медленнее, заняв меньший объем памяти.
Хорошим примером в данном случае может служить алгоритм нахождения кратчайшего пути. Задав карту улиц города в виде сети, можно написать алгоритм, вычисляющий кратчайшее расстояние между любыми двумя точками в этой сети. Вместо того чтобы каждый раз заново пересчитывать кратчайшее расстояние между двумя заданными точками, можно заранее просчитать его для всех пар точек и сохранить результаты в таблице. Тогда, чтобы найти кратчайшее расстояние для двух заданных точек, достаточно будет просто взять готовое значение из таблицы.
При этом мы получим результат практически мгновенно, но это потребует большого объема памяти. Карта улиц для большого города, такого как Бостон или Денвер, может содержать сотни тысяч точек. Для такой сети таблица кратчайших расстояний содержала бы более 10 миллиардов записей. В этом случае выбор между временем исполнения и объемом требуемой памяти очевиден: поставив дополнительные 10 гигабайт оперативной памяти, можно заставить программу выполняться гораздо быстрее.
Из этой связи вытекает идея пространственно‑временной сложности алгоритмов. При этом подходе сложность алгоритма оценивается в терминах времени и пространства, и находится компромисс между ними.
В этой книге основное внимание уделяется временной сложности, но мы также постарались обратить внимание и на особые требования к объему памяти для некоторых алгоритмов. Например, сортировка слиянием (mergesort), обсуждаемая в 9 главе, требует больше временной памяти. Другие алгоритмы, например пирамидальная сортировка (heapsort), которая также обсуждается в 9 главе, требует обычного объема памяти.
Многократная рекурсия
Рекурсивный алгоритм, вызывающий себя несколько раз, является примером многократной рекурсии (multiple recursion). Процедуры с множественной рекурсией сложнее анализировать, чем просто рекурсивные алгоритмы, и они могут давать больший вклад в общую сложность алгоритма.
Нижеприведенная подпрограмма похожа на предыдущую подпрограмму CountDown, только она вызывает саму себя дважды:
Sub DoubleCountDown(N As Integer)
If N <= 0 Then Exit Sub
DoubleCountDown N - 1
DoubleCountDown N - 1
End Sub
Можно было бы предположить, что время выполнения этой процедуры будет в два раза больше, чем для подпрограммы CountDown, и оценить ее сложность порядка 2*O(N)=O(N). На самом деле ситуация немного сложнее.
Если T(N) — число раз, которое выполняется процедура DoubleCountDown с параметром N, то легко заметить, что T(0)=1. Если вызвать процедуру с параметром N равным 0, то она просто закончит свою работу после первого шага.
Для больших значений N процедура вызывает себя дважды с параметром, равным N-1, выполняясь 1+2*T(N-1) раз. В табл. 1.1 приведены некоторые значения функции T(0)=1 и T(N)=1+2*T(N-1). Если обратить внимание на эти значения, можно увидеть, что T(N)=2(N+1)-1, что дает оценку сложности процедуры порядка O(2N). Хотя процедуры CountDown и DoubleCountDown и похожи, вторая процедура требует выполнения гораздо большего числа шагов.
@Таблица 1.1. Значения функции времени выполнения для подпрограммы DoubleCountDown
Косвенная рекурсия
Процедура также может вызывать другую процедуру, которая в свою очередь вызывает первую. Такие процедуры иногда даже сложнее анализировать, чем процедуры с множественной рекурсией. Алгоритм вычисления кривой Серпинского, который обсуждается в 5 главе, включает в себя четыре процедуры, которые используют как множественную, так и непрямую рекурсию. Каждая из этих процедур вызывает себя и другие три процедуры до четырех раз. После довольно сложных подсчетов можно показать, что этот алгоритм имеет сложность порядка O(4N).
Требования рекурсивных алгоритмов к объему памяти
Для некоторых рекурсивных алгоритмов важен объем доступной памяти. Можно легко написать рекурсивный алгоритм, который будет запрашивать
небольшой объем памяти при каждом своем вызове. Объем занятой памяти может увеличиваться в процессе последовательных рекурсивных вызовов.
Поэтому для рекурсивных алгоритмов необходимо хотя бы приблизительно оценивать требования к объему памяти, чтобы убедиться, что программа не исчерпает при выполнении всю доступную память.
Приведенная ниже подпрограмма запрашивает память при каждом вызове. После 100 или 200 рекурсивных вызовов, процедура займет всю свободную память, и программа аварийно остановится с ошибкой «Out of Memory».
Sub GobbleMemory(N As Integer)
Dim Array() As Integer
ReDim Array (1 To 32000)
GobbleMemory N + 1
End Sub
Даже если внутри процедуры память не запрашивается, система выделяет память из системного стека (system stack) для сохранения параметров при каждом вызове процедуры. После возврата из процедуры память из стека освобождается для дальнейшего использования.
Если в подпрограмме встречается длинная последовательность рекурсивных вызовов, программа может исчерпать стек, даже если выделенная программе память еще не вся использована. Если запустить на исполнение следующую подпрограмму, она быстро исчерпает всю свободную стековую память и программа аварийно прекратит работу с сообщением об ошибке «Out of stack Space». После этого вы сможете узнать значение переменной Count, чтобы узнать, сколько раз подпрограмма вызывала себя перед тем, как исчерпать стек.
Sub UseStack()
Static Count As Integer
Count = Count + 1
UseStack
End Sub
Определение локальных переменных внутри подпрограммы также может занимать память из стека. Если изменить подпрограмму UseStack из предыдущего примера так, чтобы она определяла три переменных при каждом вызове, программа исчерпает стековое пространство еще быстрее:
Sub UseStack()
Static Count As Integer
Dim I As Variant
Dim J As Variant
Dim K As Variant
Count = Count + 1
UseStack
End Sub
Логарифмы
Перед тем, как продолжить дальше, следует остановиться на логарифмах, так как они играют важную роль в различных алгоритмах. Логарифм числа N по основанию B это степень P, в которую надо возвести основание, чтобы получить N, то есть BP=N. Например, если 23=8, то соответственно log2(8)=3.
@Таблица 1.3. Время выполнения сложных алгоритмов
Можно привести логарифм к другому основанию при помощи соотношения logB(N)=logC(N)/logC(B). Например, чтобы вычислить логарифм числа по основанию 10, зная его логарифм по основанию 2, можно воспользоваться формулой log10(N)=log2(N)/log2(10). При этом log2(10) — это табличная константа, примерно равная 3,32. Так как постоянные множители при оценке сложности алгоритма можно опустить, то O(log2(N)) — это же самое, что и O(log10(N)) или O(logB(N)) для любого B. Поскольку основание логарифма не имеет значения, часто просто пишут, что сложность алгоритма порядка O(log(N)).
В программировании часто встречаются логарифмы по основанию 2, что обусловлено применяемой в компьютерах двоичной системой исчисления. Поэтому мы для упрощения выражений будем везде писать log(N), подразумевая под этим log2(N). Если используется другое основание алгоритма, это будет обозначено особо.
Обращение к файлу подкачки
Важным фактором при работе в реальных условиях является частота обращения к файлу подкачки (page file). Операционная система Windows отводит часть дискового пространства под виртуальную память (virtual memory). Когда исчерпывается оперативная память, Windows сбрасывает часть ее содержимого на диск. Освободившаяся память предоставляется программе. Этот процесс называется подкачкой, поскольку страницы, сброшенные на диск, могут быть подгружены системой обратно в память при обращении к ним.
Поскольку операции с диском намного медленнее операций с памятью, слишком частое обращение к файлу подкачки может значительно снизить производительность приложения. Если программа часто обращается к большим объемам памяти, система будет часто использовать файл подкачки, что приведет к замедлению работы.
Приведенная в числе примеров программа Pager запрашивает все больше и больше памяти под создаваемые массивы до тех пор, пока программа не начнет обращаться к файлу подкачки. Введите количество памяти в мегабайтах, которое программа должна запросить, и нажмите кнопку Page (Подкачка). Если ввести небольшое значение, например 1 или 2 Мбайт, программа создаст массив в оперативной памяти, и будет выполняться быстро.
Если же вы введете значение, близкое к объему оперативной памяти вашего компьютера, то программа начнет использовать файл подкачки. Вполне вероятно, что она будет при этом обращаться к диску постоянно. Вы также заметите, что программа выполняется намного медленнее. Увеличение размера массива на 10 процентов может привести к 100‑процентному увеличению времени исполнения.
Программа Pager может использовать память одним из двух способов. Если вы нажмете кнопку Page, программа начнет последовательно обращаться к элементам массива. По мере перехода от одной части массива к другой, системе может потребоваться подгружать их с диска. После того, как часть массива оказалась в памяти, программа может продолжить работу с ней.
Если же вы нажмете на кнопку Thrash (Пробуксовка), программа будет случайно обращаться к разным участкам памяти. При этом вероятность того, что нужная страница находится в этот момент на диске, намного возрастает. Это избыточное обращение к файлу подкачки называется пробуксовкойпамяти (thrashing). В табл. 1.4 приведено время исполнения программы Pager на компьютере с процессором Pentium с тактовой частотой 90 МГц и 24 Мбайт оперативной памяти. В зависимости от конфигурации вашего компьютера, скорости работы с диском, количества установленной оперативной памяти, а также наличия других запущенных параллельно приложений время выполнения программы может сильно различаться.
Вначале время выполнения теста растет почти пропорционально размеру занятой памяти. Когда начинается обращение к файлу подкачки, скорость работы программы резко падает. Заметьте, что до этого тесты с обращением к файлу подкачки и пробуксовкой ведут себя практически одинаково, то есть когда весь массив находится в оперативной памяти, последовательное и случайное обращение к элементам массива занимает одинаковое время. При подкачке элементов массива с диска случайный доступ к памяти намного менее эффективен.
Для уменьшения числа обращений к файлу подкачки есть несколько способов. Основной прием — экономное расходование памяти. При этом надо помнить, что программа обычно не может занять всю физическую память, потому что часть ее занимает система и другие программы. Компьютер, на котором были получены результаты, приведенные в табл. 1.4, начинал интенсивно обращаться к диску, когда программа занимала 20 Мбайт из 24 Мбайт физической памяти.
Иногда можно написать код так, что программа будет обращаться к блокам памяти последовательно. Алгоритм сортировки слиянием, описанный в 9 главе, манипулирует большими блоками данных. Эти блоки сортируются, а затем сливаются вместе. Упорядоченная работа с памятью уменьшает число обращений к диску.
@Таблица 1.4. Время выполнения программы Pager в секундах
Память (Мбайт)
Подкачка
|
Пробуксовка
| | 2
| 3,79
| 3,73
|
| 4
| 7,58
| 7,47
|
| 6
| 11,37
| 11,2
|
| 8
| 15,49
| 14,94
|
| 10
| 18,9
| 18,62
|
| 12
| 22,85
| 22,36
|
| 14
| 26,47
| 26,15
|
| 16
| 30,26
| 29,88
|
| 18
| 34,51
| 37,46
|
| 20
| 132,37
| 12,155 (оценка)
|
Алгоритм пирамидальной сортировки, также описанный в 9 главе, произвольно переходит от одной части списка к другой. Для очень больших списков это может приводить к перегрузке памяти. С другой стороны, сортировка слиянием требует большего объема памяти, чем пирамидальная сортировка. Если список достаточно большой, это также может приводить к обращению к файлу подкачки.
Ссылки
В 4-й версии Visual Basic были впервые введены классы. Переменная, указывающая на экземпляр класса, является ссылкой на объект. Например, в следующем фрагменте кода переменная obj — это ссылка на объект класса MyClass. Эта переменная не указывает ни на какой объект, пока она не определяется при помощи зарезервированного слова New. Во второй строке оператор New создает новый объект и записывает ссылку на него в переменную obj.
Dim obj As MyClass
Set obj = New MyClass
Ссылки в Visual Basic — это разновидность указателей.
Объекты в Visual Basic используют счетчик ссылок (reference counter) для упрощения работы с объектами. Когда создается новая ссылка на объект, счетчик ссылок увеличивается на единицу. После того, как ссылка перестает указывать на объект, счетчик ссылок соответственно уменьшается. Когда счетчик ссылок становится равным нулю, объект становится недоступным программе. В этот момент Visual Basic уничтожает объект и возвращает занятую им память.
В следующих главах более подробно обсуждаются ссылки и счетчики ссылок.
Коллекции
Кроме объектов и ссылок, в 4-й версии Visual Basic также появились коллекции. Коллекцию можно представить как разновидность массива. Они
предоставляют в распоряжение программиста удобные возможности, например можно менять размер коллекции, а также осуществлять поиск объекта по ключу.
Вопросы производительности
Псевдоуказатели, ссылки и коллекции упоминаются в этой главе потому, что они могут сильно влиять на производительность программы. Ссылки и коллекции могут упрощать программирование определенных операций, но они могут потребовать дополнительных расходов памяти.
Программа Faker на диске с примерами демонстрирует взаимосвязь между псевдоуказателями, ссылками и коллекциями. Когда вы вводите число и нажимаете кнопку Create List (Создать список), программа создает список элементов одним из трех способов. Вначале она создает объекты, соответствующие отдельным элементам, и добавляет ссылки на объекты к коллекции. Затем она использует ссылки внутри самих объектов для создания связанного списка объектов. И, наконец, она создает связный список при помощи псевдоуказателей. Пока не будем останавливаться на том, как работают связные списки. Они будут подробно разбираться во 2 главе.
После нажатия на кнопку Search List (Поиск в списке), программа Faker выполняет поиск по всем элементам списка, а после нажатия на кнопку Destroy List (Уничтожить список) уничтожает все списки и освобождает память.
В табл. 1.5 приведены значения времени, которое требуется программе для выполнения этих задач на компьютере с процессором Pentium с тактовой частотой 90 МГц. Из таблицы видно, что за удобство работы с коллекциями приходится платить ценой большего времени, затрачиваемого на создание и уничтожение коллекций.
Коллекции также содержат индекс списка. Часть времени, затрачиваемого при создании коллекции, и уходит на создание индекса. При уничтожении коллекции сохраняемые в ней ссылки освобождаются. При этом система проверяет и обновляет счетчики ссылок для всех объектов. Если они равны нулю, то сам объект также уничтожается. Все это занимает дополнительное время.
При использовании псевдоуказателей создание и уничтожение списка происходит так быстро, что этим временем можно практически пренебречь. Системе при этом не надо заботиться о ссылках, счетчиках ссылок и об освобождении объектов.
С другой стороны, поиск в коллекции осуществляется гораздо быстрее, чем в двух остальных случаях, поскольку коллекция использует быстрое хеширование (hashing) построенного индекса, в то время как список ссылок и список псевдоуказателей используют медленный последовательный поиск. В 11 главе объясняется, как можно добавить хеширование к своей программе без использования коллекций.
@Таблица 1.5. Время Создания/Поиска/Уничтожения списков в секундах
| Размер списка
| 1000
| 2000
| 3000
|
| Коллекция ссылок
| 0,77/0,33/0,60
| 1,53/0,60/2,25
| 2,42/1,05/0,22
|
| Список связанных ссылок
| 0,11/1,49/0,06
| 0,33/6,32/0,17
| 0,60/14,66/0,22
|
| Псевдоуказатели
| 0,00/1,48/0,00
| 0,00/5,77/0,00
| 0,00/13,07/0,00
|
Хотя применение псевдоуказателей обычно обеспечивает лучшую производительность, оно менее удобно, чем использование ссылок. Если в программе нужен лишь небольшой список, ссылки и коллекции могут работать достаточно быстро. При работе с большими списками можно получить более высокую производительность, используя псевдоуказатели.
Резюме
Анализ производительности алгоритмов позволяет сравнить разные алгоритмы. Он также помогает оценить поведение алгоритмов при различных условиях. Выделяя только части алгоритма, которые вносят наибольший вклад во время исполнения программы, анализ помогает определить, доработка каких участков кода позволяет внести максимальный вклад в улучшение производительности.
В программировании часто приходится идти на различные компромиссы, которые могут сказываться на производительности. Один алгоритм может быть быстрее, но за счет использования большого объема памяти. Другой алгоритм, использующий коллекции, может быть более медленным, но зато его проще разрабатывать и поддерживать.
После анализа доступных алгоритмов, понимания того, как они ведут себя в различных условиях и их требований к ресурсам, вы можете выбрать оптимальный алгоритм для вашей задачи.
Кажется, Хоар сказал, что эстетическая прелесть программы - это
не архитектурное излишество, а то, что отличает в программирова-
нии успех от неудачи.
Определение алгоритма.
Термин происходит от имени средневекового математика(787-850) Абу Джафара ибн Мусы аль-Хорезми. Редакция последней части имени ученого в европейских языках привела к образованию термина «алгорифм» или «алгоритм». Европейцы, начавшие осваивать современную десятичную систему счисления в XII в.(был выполнен латинский перевод его математического трактата), знакомились с трудами арабских ученых, и труд упомянутого выше жителя Хорезма, посвященный правилам счета в десятичной системе счисления и правила арифметики многозначных чисел, был широко известен. Поэтому и наполнение термина «алгоритм» было следующим: операции над числами. Сложение, вычитание, умножение столбиком, деление уголком многозначных чисел – вот первые алгоритмы в математике.
Современное содержание понятия алгоритма можно определить следующим образом.
Алгоритм – четкая система правил, которая задает последовательность действий над некоторыми объектами и после конечного числа шагов приводят к достижению поставленной цели.
Когда вы даете кому‑то инструкции о том, как отремонтировать газонокосилку, испечь торт, вы тем самым задаете алгоритм действий. Конечно, подобные бытовые алгоритмы описываются неформально, например, так:
Проверьте, находится ли машина на стоянке.
Убедитесь, что машина поставлена на ручной тормоз.
Поверните ключ.
И т.д.
При этом по умолчанию предполагается, что человек, который будет следовать этим инструкциям, сможет самостоятельно выполнить множество мелких операций, например, отпереть и открыть дверь, сесть за руль, пристегнуть ремень, найти ручной тормоз и так далее.
Если же составляется алгоритм для исполнения компьютером, вы не можете полагаться на то, что компьютер поймет что‑либо, если это не описано заранее. Словарь компьютера (язык программирования) очень ограничен и все инструкции для компьютера должны быть сформулированы на этом языке. Поэтому для написа