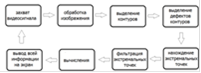
Рис. 15. Принципиальная схема программы
Разработку программы имеет смысл разделить на несколько шагов. Сначала программа должна получить видеосигнал с камеры и выделить из него одно изображение. Все остальные действия ведутся над анализом этого изображения, и, после завершения всех процедур, программа возвращает результат и захватывает новое изображение. Следующий после захвата изображения этап - его редактирование. Программа должна максимально упростить себе задачу анализа: изображение должно быть максимально сжато по разрешению и не должно содержать лишних цветов. В данном случае нужно произвести пороговое преобразование в бинарный вид, так как будут использоваться именно бинарные методы. Далее программа должна выделить необходимые контуры изображения с помощью алгоритмов компьютерного зрения и найти их дефекты. Подробнее об этом пойдет речь в соответствующем подразделе. Далее нужно найти и отфильтровать так называемые экстремальные точки - они содержат большинство информации об объекте. Затем исходя из положения этих точек нужно произвести необходимые вычисления и сделать вывод о том, какой именно жест демонстрируется. Так же вся графическая информация должна быть показана на экране. После всех этих действий цикл следует повторить.
Для программы был создан проект на платформе JavaFX в среде разработки IntelliJ IDEA. JavaFX по своей сути есть платформа для создания приложений на языке Java с графическим интерфейсом. Для создания интерфейсов существует файл на языке разметки FXML, который «общается» с программой на Java с помощью класса controller.java. FXML-файл описывает положение, размеры, графическое оформление всех элементов программы, а controller.java связывает элементы в программный код.
Захват видеосигнала
Первой задачей стал вывод на экран компьютера видеопотока с камеры. Сделать это можно и без использования библиотеки OpenCV, но мы сразу будем использовать её возможности. В классе Main создадим метод start, который будет производить действия для предварительной подготовки программы. В этом методе мы создаем объект класса FXMLLoader, указываем ему путь на FXML-файл с разметкой и назначаем его «родителем» (Parent). Отныне каждый объект, находящийся в программе будет являться классом-«ребенком» (Child) и подчиняться FXML-файлу и его контроллеру. Затем создается объект класса Stage (а так же дочерний объект класса Scene, который является окном программы в системе Microsoft Windows) и задаются его параметры - заголовок, размеры, возможность изменять размеры окна. Затем методом Stage.show окно вызывается для взаимодействия с пользователем.
Выполнив эти действия, метод передает управление классу controller.java, в котором содержится основной код программы. В этом месте нужно создать объекты для всех элементов программы. Это объекты классов Button (графическая кнопка включения и выключения камеры), ImageView (класс, предназначенный для вывода изображений на экран), ScheduledExecutorService (таймер для контроля видеопотока) и VideoCapture (класс OpenCV, захватывающий видео с камеры).
Запрограммируем метод private Mat grabFrame, захватывающий видеопоток. Как мы знаем, слово перед названием метода означает тип данных переменной, которую возвращает этот метод. В данном случае это не стандартная переменная, а объект класса Mat, содержащегося в библиотеке OpenCV. В нашем случае это будет объект frame - одно изображение, взятое из видеопотока. Итак, в методе private Mat grabFrame создаем объект frame класса Mat. С помощью метода this.capture.isOpened программа проверяет, поступает ли с порта камеры изображение, и, если да, то применяет метод this.capture.read (frame), который записывает кадр в объект, а если нет, то выдает ошибку. Далее идет проверка, содержит ли кадр какую-либо информацию, и, если содержит, то над ним будут проводиться необходимые преобразования, которые мы пропишем позже. Пустой же кадр метод возвращает без изменений.
Следующий необходимый метод обрабатывает событие, возникающее при нажатии кнопки Start Camera. Назовем его void startCamera (ActionEvent event). Как мы можем увидеть, этот метод принимает как аргумент событие нажатия кнопки и не возвращает никаких значений.
Как только кнопка оказывается нажатой, метод активируется и сначала применяет метод this.capture.open (cameraId), включающий захват с камеры с номером cameraId. Если захват включён, то функция frameGrabber с помощью упомянутого ранее таймера захватывает изображение с потока раз в 33мс (30 кадров в секунду). Тут же производится и перенос изображения из объекта класса Mat в объект класса Image. Так же в методе предусмотрен вывод сообщений об ошибке, процедура закрытия программы, изменений надписи на кнопке, в зависимости от состояния камеры (включена или выключена).
Теперь в FXML-файле нужно создать разметку: в текстовом виде или с помощью утилиты SceneBuilder. В объекте класса Scene, который является окном программы в операционной системе Microsoft Windows, создадим связанные элементы GridPane и BorderPane. Они служат для удобной расстановки элементов управления по рабочему пространству программы. Так же необходимо создать объект класса ImageView для показа захватываемого изображения на экран и объект класса Button для включения и выключения камеры.
Рис. 16. Интерфейс программы в утилитеSceneBuilder
Представленная на Рис. 17 программа - результат на данный момент. Пока она умеет лишь захватывать видео с камеры и выводить его на экран. Так же имеется кнопка Start/Stop Camera, которая соответственно включает и выключает камеру.
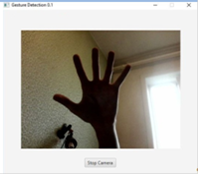
Рис. 17. Программа, захватывающая видеосигнал с камеры
Обработка изображения
Прежде чем приступить к написанию алгоритма, анализирующего изображение, нужно несколько отредактировать его, чтобы в дальнейшем облегчить работу как пользователю, так и программе.
В первую очередь, информация о цвете изображения является избыточной и нет нужды тратить вычислительные мощности на ее обработку. Тем более, она может не только оказаться ненужной, но и навредить, уменьшая эффективность распознавания объекта. Так же многие методы библиотеки OpenCV в принципе могут работать только с двухцветными изображениями. Поэтому в большинстве проектов по распознаванию объектов изображение переводится в бинарный вид (черные и белые пиксели без оттенков серого). Часто этот перевод происходит с помощью семплирования цвета - в таком случае программа запоминает определенный цвет и переводит все пикселы с цветами, имеющими похожий цвет, в белый, а все остальные пикселы - в черный. Однако в данном случае этот метод является излишним, так как предполагается только распознавание темного предмета на светлом фоне. Итак, как мы знаем, результатом захвата видеосигнала является объект frame класса Mat. Создадим метод, преобразующий его в двоичный вид и назовем его imageEdit. В результате всех преобразований над изображением оно должно максимально полно передавать информацию о положении объекта, то есть в идеале полностью обозначать объект одним из цветов, а фон - другим.
Первое необходимое действие - перевод изображения в монохромный вид. Оно производится методом Imgproc.cvtColor, который принимает три аргумента: объект изображения-источника, объект, в который записывается преобразованное изображение и тип преобразования. В качестве первых двух выберем объект frame, а типом преобразования будет COLOR_BGR2GRAY. Теперь для получения бинарного изображения, нужно произвести пороговое преобразование. За это отвечает метод Imgproc.threshold, который имеет пять аргументов: два первых повторяют аналогичные для Imgproc.cvtColor, третий - величина порога выбора цвета, четвертый - максимальное значение переменной, а пятый - тип преобразования (метод поддерживает различные алгоритмы, из который мы выбираем находящийся под номером один, в котором пиксел перекрашивается в белый цвет, если значение его яркости меньше порогового значения, и в черный в другом случае). Значение порога не может быть выбрано раз и навсегда, так как оно должно зависеть от внешних условий, таких как освещение. Поэтому добавим объект класса Slider в класс controller и в файл разметки. В нем же устанавливаются максимальное, минимальное значения и значение по умолчанию для слайдера. Теперь команду slider.getValue можно вставить в качестве третьего аргумента метода порогового преобразования и управлять величиной порога непосредственно с экрана.
Теперь изображение имеет бинарный вид, но необходимо произвести еще одно преобразование - размытие, защищающее от помех. Оно производится методом Imgproc.medianBlur. Аналогично с пороговым преобразованием, создадим слайдер, управляющий глубиной размытия и эмпирически выберем оптимальный тип алгоритма для данной задачи.
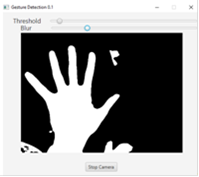
Рис. 18. Внешний вид программы после редактирования изображения
Выделение контуров
Добившись результата, в котором программа выдает качественное бинарное изображение руки, можно приступать к анализу этого изображения. Сейчас для компьютера оно представляет собой двоичный массив, в котором черные пиксели можно считать за состояние true, а белые - за состояние false. Наша задача - анализ информации, содержащейся в этом массиве и вынесение решения согласно этой информации. Алгоритм должен состоять из двух частей: первая каким-то образом структурирует информацию, содержащуюся в изображении, представляет всю полезную часть информации в виде определенного блока данных. Вторая часть сравнивает эти данные с определенными константами, заданными программистом. Если обработанные данные соответствуют какой-то из констант, то программа возвращает определенный результат, иначе - сообщение об ошибке или отсутствии необходимого типа изображения.
Самый примитивный вариант реализации - полностью игнорировать первый шаг, оставив данные в массиве двоичных переменных и сравнивать этот массив с заранее записанным в программу изображением какого-либо жеста. В таком случае используемый метод фактически представляет собой корреляционный прием: значение каждого пиксела полученного изображения перемножается со значением соответствующего пиксела заданного изображения. Затем эти значения суммируются и по этой сумме можно делать вывод о степени «похожести» двух изображений. Этот метод прост для программирования, но чрезвычайно неэффективен: из-за различных вариаций захваченного изображения (масштаб, положение руки, индивидуальные особенности каждого пользователя) метод будет давать существенные ошибки [11]. Поэтому в данном проекте мы перейдем от анализа пикселей к анализу контуров.
Стоит обговорить, какую информацию следует выделить из изображения для дальнейшей обработки. Начать следует с самых простых жестов - когда плоскость ладони перпендикулярна камере и в качестве переменных для вычислений используется только длины пальцев (прижат тот или иной палец или нет) и углы между пальцами. Для получения всей этой информации достаточно найти на изображении несколько точек, называемых экстремальными: кончик каждого пальца и каждую перепонку между пальцами. В таком случае необходимо создать два контура: один точно очерчивает руку, а другой соединяет крайние точки в многоугольник. В таком случае точки на кончиках пальцев - это и есть точки, по которым следует построить обводящий контур, а точки между пальцами можно найти как максимальные отклонения одного контура от другого. Значит сначала нужно найти и нарисовать оба контура, а затем производить операции над ними. Далее контур, повторяющий форму руки, будем называть внутренним (в программе он значится как contour), а контур, соединяющий экстремальные точки объекта в многоугольник, будем называть обводящим (или convexHull). Естественно, на изображении может быть целое множество контуров, и все контуры того или иного вида объединяются в массив, каждый элемент которого является, в свою очередь, массивом точек или иных типов переменных. Таким образом, и contour, и convexHull - это двухмерные массивы, и каждый отдельный контур можно выделить с помощью метода get(i), где i - номер контура [9].
Дополним метод обработки изображения командами, которые будут находить контуры изображения и графически выделять их на рабочем поле. Для начала пропишем команду LinkedList<MatOfPoint> contours = new LinkedList<>. Она создает массив объектов класса MatOfPoint - это тип данных, хранящий в себе положение множества точек на двухмерном пространстве изображения. Значит каждый контур будет обрабатываться программой, как массив точек, находящихся на определенной кривой. Затем с помощью команды contours.clear убедимся, что заданный массив пуст. Далее применяется метод findContours из класса Imgproc. Он, используя определенные алгоритмы, выделит контуры на порогах белого и черного цветов и запишет их в массив contours. Настройки алгоритма задаются двумя атрибутами: мы выбираем Imgproc.RETR_EXTERNAL для того, чтобы сообщить программе, что следует игнорировать внутренние контуры и выделять следует только наружные. Второй атрибут характеризует сам тип используемого алгоритма и эмпирическим путем было выявлено, что оптимально подходит Imgproc.CHAIN_APPROX_TC89_KCOS.
Далее произведем фильтрацию: интерес для анализа представляет только один объект, так что из всех выделенных контуров можно выбрать единственный с наибольшей площадью. Поэтому создадим новый объект MatOfPoint finalContours, он будет хранить в себе наибольший контур, который программа будет отрисовывать и над которым будут проводиться дальнейшие операции. Запишем в его первый элемент изначального массива контуров, а затем циклом будем проверять каждый последующий элемент contours и, если возвращенное методом Imgproc.contourArea значение площади будет превосходить значение площади единственного элемента finalContours, то элемент finalContours будет принимать значение элемента contours. Таким образом мы получили объект, содержащий только контур вокруг самого большого предмета на изображении.
В конце пропишем метод, рисующий все контуры на рабочем поле, Imgproc.drawContours. Его параметры не представляют особого интереса: это поле, в котором нужно рисовать, массив самих контуров, цвет и толщина линий.
Нахождение обводящего контура - менее тривиальная задача. Дело в том, что библиотека OpenCV умеет оперировать множеством типов переменных и массивов, причем разные ее методы требуют применения разных типов. Поэтому нередко приходится применять весьма нетривиальные преобразования, особенно реализации библиотеки для языка Java: многие операции, в отличие от реализаций для других языков программирования, здесь приходится производить вручную.
Как мы помним, контур, очерчивающий объект, программа воспринимает как массив класса MatOfPoint, содержащего в себе координаты каждой точки данного контура. Однако объект обводящего контура задается совершенно другим путем - метод Imgproc.convexHull находит не контур, а каждую крайнюю точку изображения как элемент массива MatOfInt, состоящего из целых чисел, тогда как для графического изображения пригоден только массив MatOfPoint. Итак, для единственного оставшегося после фильтрации внутреннего контура нужно создать элемент массива с помощью метода convexHull.add(new MatOfInt), а также применить сам метод Imgproc.convexHull, отыскивающий обводящий контур вокруг внутреннего, причем в атрибутах метода должны находиться нулевые элементы массивов contour и convexHull, которые выделяются с помощью метода get. В результате массив convexHull наполняется обводящим контуром.
Теперь преобразуем его в необходимый формат, MatOfPoint. Преобразование идет сначала из формата библиотеки OpenCV MatOfInt в обычный двухмерный массив переменных типа Point, и только потом непосредственно в формат MatOfInt. Создадим массив класса Point и назовем его hullpoints. Затем в каждом шаге цикла от нуля до количества обводящих контуров создадим новую точку в массиве и еще одним циклом присвоим новое значение с помощью метода convexHull.get. Массив же в формате MatOfPoint обозначим как hullmop и еще одним циклом по всем элементам hullpoints проведем преобразование. Происходит это тремя командами: создается объект MatOfPoint, затем метод fromArray(hullpoints.get) передает ему соответствующее счетчику значение массива hullpoints, затем метод hullmop.add записывает этот объект в соответствующий массив. [5]
Теперь контур доступен для рисования методом Imgproc.drawContours. Выберем для его отображения другой цвет и толщину линий. В результате программа имеет данный вид.
В результате программа имеет вид, показанный на рис. 19.
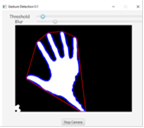
Рис. 19. Программа после выделения контуров






