

Автоматическое растормаживание колес: Тормозные устройства колес предназначены для уменьшения длины пробега и улучшения маневрирования ВС при...

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Автоматическое растормаживание колес: Тормозные устройства колес предназначены для уменьшения длины пробега и улучшения маневрирования ВС при...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Топ:
Особенности труда и отдыха в условиях низких температур: К работам при низких температурах на открытом воздухе и в не отапливаемых помещениях допускаются лица не моложе 18 лет, прошедшие...
Оснащения врачебно-сестринской бригады.
Теоретическая значимость работы: Описание теоретической значимости (ценности) результатов исследования должно присутствовать во введении...
Интересное:
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Принципы управления денежными потоками: одним из методов контроля за состоянием денежной наличности является...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
По СБ с РВУ на РДК считывается очередной байт информации. По формуле (1) корректируются параметры канала.
Если СБ и Дл массива не равны нулю, то переходим к третьему этапу.
Если СБ = 0, а Дл массива ≠ 0, то это означает, что СБ заполнен полностью и по адресу с РКК производиться запись в память с РДК. Далее третий этап.
Если Дл массива =0, то РДК записывается в память и анализируется поле признаков (см. выполнение операции «запись»).
В мультиплексном канале существует 3 различных регистра для хранения адреса.
1. РА – хранит адрес памяти подканала.
2. РАКК – хранит адрес следующего управляющего слова.
3. Адр в РКК – хранит адрес массива, который считывается или записывается в ОП.
Магистральный ввод/вывод

Через общую шину могут обслуживаться одновременно только 2 устройства. Поэтому, в отличие от предыдущего случая, параллельное совмещение по времени выполнения программы в ЦП и ввод/вывод невозможно.
В каждый момент времени одно устройство является ведущим, а остальные являются ведомыми, за исключением ОП, которая всегда ведомая.
В общей шине выделяют 4 группы шин:
1. Шины данных
2. Шины управления
3. Адресные шины
4. Шины арбитража
Шины данных:
По шинам данных в параллельном коде данные пересылаются между ведущим и ведомым устройствами.
Шины управления предназначены для передачи управляющих сигналов.
Адресные шины:
При данном способе ввода/вывода существует единое адресное пространство для всех устройств. Следовательно, здесь не нужны специальные команды в/в, а достаточно команды move (команда пересылки), а адреса определяют между какими устройствами осуществляется передача. В этом заключается отличие от радиального в/в.
|
|
Шины арбитража(шина запроса на прерывание):
См. стековый механизм прерывания.
ВУ, готовое к приему или передаче 1-2 байт информации, выставляет сигнал прерывания на шину запроса. Запрос обрабатывается и в качестве программы обработки прерывания будет выступать программа в/в, под управлением которой 1-2 байта информации будут передаваться между двумя устройствами. Такой программно управляемый в/в характерен для медленных устройств. Для быстродействующих систем используют прямой доступ к памяти. Быстродействующие устройства подключаются к специальной шине запроса на прерывание, которая имеет наивысший приоритет. При поступлении запроса на шину прямого доступа к памяти общая шина освобождается для в/в. Однако программа, обрабатываемая в ЦП, с обработки не снимается, т.е. стековый механизм реализации прерывания в этом случае не работает.
Программно-управляемый ввод/вывод(для медленных ВУ)


|

 : ЗП1
: ЗП1
:

 РПn
РПn
|
|

 РП1
РП1
ВУ как только готово принять или передать байт информации на шину запроса на прерывание, выставляет запрос на прерывание.
В стэк записываются основные параметры прерванной программы(вектор состояния). По адресу вектора прерывания, который выдаёт ВУ, выбираются основные параметры прерывания во вводу/выводу(адрес 1-ой выполняемой команды, порог прерывания) и помещаются на регистры ЦП. В ЦП начинает выполняться программа прерывания по вводу/выводу. Под управлением этой программы происходит ввод/вывод 1-2 байта информации (обмен между ВУ и ОП или ЦП). После этого программа обработки прерываний завершает свою работу. Из стэка восстанавливаются основные параметры прерванной программы(вектор состояний), и она продолжает выполняться далее. Когда ВУ вновь будет готово принять или передать 1-2 байта информации, то оно вновь выставляет запрос на прерывание и т.д.
|
|
Параллельно ввод/вывод и обработка программы в ЦП выполняться не могут.
Прямой доступ к памяти(для быстродействующих ВУ)
Программа в ЦП не прерывается(стэковый механизм прерывания не задействуется). Непосредственно ввод/вывод осуществляется под управлением контроллера по вводу/выводу. При этом ВУ подаёт запрос на специальную шину: запрос прямого доступа к памяти. Эта линия всегда имеет самый высокий приоритет. В контроллере есть регистр адреса начала массива, регистр длины массива. Как только длина массива = 0 передача заканчивается.
Радиальный ввод/вывод

В отличие от магистрального ввода/вывода имеется отдельное адресное пространство. Это значит ВУ может иметь один и тот же адрес, что и ячейка памяти, использующая команды в/в.
Микропроцессоры.
Выделяют два основных направления:
- однокристальные
- секционированные
Секционированные микропроцессоры:
на одном кристалле выполнен полностью микропроцессор (мп) на ограниченное кол-во разрядов (например 4) Секции соединяются между собой, следовательно происходит наращивание разрядности мп до требуемого числа разрядов. Программирование ведется на микропрограммном уровне.
Однокристальные микропроцессоры:
весь процессор выполнен на одном кристалле. Программирование ведется на уровне машинных команд. На 1-ой ступени развития целиком мп не удавалось выполнить на одном кристалле, тогда мп был разделен «горизонтальными плоскостями» на несколько кристаллов.
Микропроцессоры серии INTEL.
| м/п | Год выпуска | Частота МГц | Кол-во транзисторов тыс.шт | Разряд шины | Размер адресного пространства | Примечания |
| Intel 8086 | 1978 | 5-10 | 29 | Внутр внешн 16/16 | 1Мбайт | 20 разрядов адресная шина |
| Intel 8088 | 1980 | 5-8 | 29 | 16/8 | 1Мбайт | Используем в PC-XT |
| 80286 | 1982 | 10-16 | 134 | 16/16 | 16Мбайт | Шина адреса 24 разряда, исп в PC-AT |
| 80386DX | 1985 | 20-33 | 275 | 32/32 | 4Гбайт | Шина адреса 32 разряда |
| 80386SX | 1988 | 20-30 | 275 | 32/16 | 4Гбайт | |
| 80486DX | 1989 | 25-50 | 1200 | 32/32 | 4Гбайт | |
| 80486DX2 DX4 | До 133 | |||||
| 80486SX | 1991 | До 33 | 1200 | 32/32 | 4Гбайт | |
| Pentium | 1993 | 150-200 | 3.1 млн | 32 | 4Гбайт | |
| Pentium Pro | 1995 | 150-200 | 5.5 млн +15.5млн или 31млн | 32 | 64Гбайт | 5.5 млн на осн кристалле 15.5млн(КЭШ 256Кб) 31млн(КЭШ 500Кб) |
| Pentium MMX | 1996 | 166-266 | 4.5 млн. | 32 | 64 Гбайт | |
| Pentium 2 | 1997 | 233-466 | 7 млн. | 32 | 64 Гбайт | |
| Celeron | 1988 | 266-300 | ||||
| Pentium III | 1999 | 500-1000 | 8.2 млн | ----//---- | ----//---- | |
| Pentium IV Prescott | 2000 | 2-3 ГГц от 3 ГГц | 55 млн 100 млн | 32 | ||
| Pentium M | 2003 | 1-2 ГГц | 77-144 млн | 32 | ||
| Core Yonah | 2004 | 1-2 ГГц | 155 млн | 32 | ||
| Core 2 Solo | 2006 | 1,6-3 ГГц | 64 |
INTEL 8086,8088
|
|
Впервые идет совмещение обработки команд во времени.
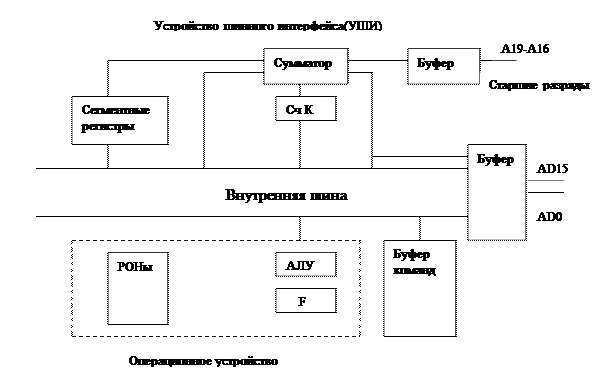
Выделяются 2 устройства: операционное устройство (ОУ) и устройство шинного интерфейса (УШИ). УШИ предназначено для вычисления адресов и формирования запросов к памяти (ОП) к ВУ. В УШИ включён буфер команд емкостью 6 байт (очередь команд). Как только в буфере команд освободится 2 байта (внешняя шина данных и ширина выборки ОП 2 байта) УШИ формирует опережающий запрос в память за командами. ОУ выполняет команды, находящиеся в буфере команд. Если требуется обращение к памяти за операндами или по записи результата, то ОУ выставляет запрос к УШИ. Если УШИ свободно, то запрос выполняется сразу же, если УШИ занято выборкой команд, то после получения 2-х очередных байт обрабатывается запрос от ОУ. Т.о. выбор следующей команды начинается не по завершению предыдущей команды, а по наличию 2х свободных байт в буфере команд- принцип опережающей обработки. Снижение производительности происходит из-за появления команд перехода. При появлении команд перехода содержимое буфера обнуляется и буфер команд заполняется с команды, на которую осуществляется переход. Мультиплексированы шины данных и шины адреса.
МИКРОПРОЦЕССОР 8088
Внешняя шина данных 8 разрядов для совместимости с ранее разработанными ВУ. Для реализации плавающей точки в м/п 8086 и в 8088 для повышения производительности на материнской плате мог отдельно устанавливаться мп, аппаратно реализующий операции с плавающей точкой.
| Тип операции | 8087 Мкс | 8086 и 8088 эмуляция мкс |
 + +
| 17-18 | 1600 |
| * | 27 | 2100 |
| √ | 36 | 19000 |
| Exp x | 130 | 17100 |
|
|
INTEL 80286
1.В отличие от 8086/8088 шина адреса и шина данных не мультиплексированы во времени (своя ША и ШД)
2. Разработчики предусмотрели реальный и защищенный режим. В защищённом режиме имеется возможность использования мультипрограммирования.
3. Конвейерная обработка команд
 Конвейерная обработка на уровне команд:
Конвейерная обработка на уровне команд:
 Каждый этап машинной команды обрабатывается на отдельном блоке. На 1-м такте 1-я команда подается на первый блок, то есть реализует 1-й этап(выборка команды из памяти). Во 2-м такте 1-я команда переходит на 2-й этап, а 2-я команда поступает на первый этап. В 3-ем такте, 1-я команда на 3 этапе, 2-я команда на 2-ом этапе, 3-я команда на 1-ом этапе. Т.е. конвейер команд аналогичен технологическому конвейеру. После заполнения конвейера каждый такт на конвейере заканчивает обрабатываться очередная команда. Поэтому говорят, что за первый такт выполняется 1 команда. Потеря производительности происходит в следствие команд перехода, когда содержимое конвейера обнуляется и в следствии информационных конфликтов
Каждый этап машинной команды обрабатывается на отдельном блоке. На 1-м такте 1-я команда подается на первый блок, то есть реализует 1-й этап(выборка команды из памяти). Во 2-м такте 1-я команда переходит на 2-й этап, а 2-я команда поступает на первый этап. В 3-ем такте, 1-я команда на 3 этапе, 2-я команда на 2-ом этапе, 3-я команда на 1-ом этапе. Т.е. конвейер команд аналогичен технологическому конвейеру. После заполнения конвейера каждый такт на конвейере заканчивает обрабатываться очередная команда. Поэтому говорят, что за первый такт выполняется 1 команда. Потеря производительности происходит в следствие команд перехода, когда содержимое конвейера обнуляется и в следствии информационных конфликтов

 R1 + R2 R1
R1 + R2 R1
 |
R3 + R1 R3
До тех пор пока результат для 1-й команды не будет записан в R1 вторая команда не может считывать операнды из R1 т.е. происходит блокирование конвейера. Для м/п INTEL 80286 число ступеней конвейера равно 4.
INTEL 80386 DX
Первый 32-х разрядный м/п. Уже в PC впервые поддерживается Windows. Работает как в реальном, так и в защищенном режиме. Поддерживается виртуальный режим м/п 8086 (если параллельно запущенно несколько задач. то каждая задача обрабат. на м/п 8086
INTEL 80386 SX
Уменьшены внешние шины данных с 32 до 16 разрядов, было вызвано совместимостью с ВУ, которые работали с м/п 80286
INTEL 80486 DX
DX2 – удвоение тактовой частоты
DX4 – утроение тактовой частоты
PENTIUM
PENTIUM PRO
|
|
1. В кристалле встроен КЭШ 1-го уровня на 16 Кбайт и КЭШ 2-го уровня либо на 256Кбайт либо на 512Кбайт. КЭШ 2-го уровня работает на тактовой частоте самого м/п, т.к встроена в кристалл.
2. В следующей модели фирма Intel отказалась от встроенного КЭШ 2-го уровня в кристалле, т.к. увеличился процент брака.
3. В Pentium Pro используют 14-ступенчатый конвейер.
4. В Pentium Pro (c него начинается серия Р6) используется конвейер с изменяемой последовательностью команд. Зависимая команда, поступающая на вход конвейера, не сдерживает выполнение следующей за ней независимой команды в окне просмотра. В предыдущих моделях зависимая команда блокировала выполнение всех следующих за ней команд.
PENTIUM MMX
Структура соответствует Pentium, однако увеличен КЭШ 1-го уровня до 32Кбайт (16 КЭШ команд +16 КЭШ данных)
Добавлено 57 новых команд для обработки видео изображения.
PENTIUM 2
Это есть Pentium Pro + Pentium MMX. Однако КЭШ 2-го уровня вынесен из кристалла и помещен на подложку в одном корпусе с основным кристаллом, работал на 0.5 тактовой частоте.
CELERON
Из подложки удален КЭШ 2-го уровня. Резко падает производительность системы. Начиная с модели 300А и выше, встраивается КЭШ внутрь кристалла на 128 Кбайт, который работает на частоте ЦП.
PENTIUM III
Структура Pentium 2, добавлены команды для обработки видео изображения.
PENTIUM 4
В последующих моделях Pentium III КЭШ встраивается в кристалл на 256 Кбайт. Все Pentium 4: КЭШ в кристалле.
PRESCOTT
31 ступень конвейера (гиперконвейрная обработка). КЭШ в кристалле увеличена до 1 Мб. КЭШ 3-го уровня 2Мб помещен на материнскую плату. Появляется новая обработка – гипертрейдинг. Чтобы заполнить 20-30 ступеней в КЭШ 1-го уровня находятся трассы микропрограмм. Гипертрейдинг – это псевдомультипрограммный режим, т.е на свободные блоки конвейера запускают вторую задачу, т.е одновременно обрабатываются 2 задачи.
PENTIUM D
На одной подложке (кристалле) помещены 2 ядра Prescott (каждый со своим КЭШ), отключив гипертрейдинг.
PENTIUM M
КЭШ 1-го уровня увеличена до 64 Кб. (архитектура P6 (продолжение Pentium III) 32Кб команд, 32Кб данных. КЭШ 2-го уровня 1-2Мб встроен в кристалл. Количество обрабатываемых блоков 9 штук)
CORE 2
КЭШ 1-го уровня увеличен до 2-4 Мб. КЭШ команд 32 Мб, КЭШ данных 32 Кб. Добавляется четвертый простой декодер. Число обрабатываемых блоков 11 штук: АЛУ с фиксированной точкой 3 штуки по 64 разряда, 2 шт. АЛУ с плавающей точкой 128р. Команды видеорежима 3 блока 128р. 3 блока обращения к памяти. Intel впервые в Core и Core 2 для двуядерных процессоров использовал общую КЭШ 2-го уровня. В Core 2 имеется связь между отдельными ядрами.
Системные интерфейсы
1. м/п 8086, 80286
тактовая частота 5-10, 10-16МГц
Проблемы которые решаются системным интерфейсами: связь ОП и ЦП, связь ядра с ВУ.

тактовая частота 5-8 Мгц
пропускная способность 5-10 Мбайт/сек
2. м/п 80386, 30 Мбайт/сек
На материнской плате появляются новые архитектурные решения: Появляется КЭШ, чтобы как можно реже обращаться к ОП. Стали использовать несколько структур решений:
1. Использование локальной шины
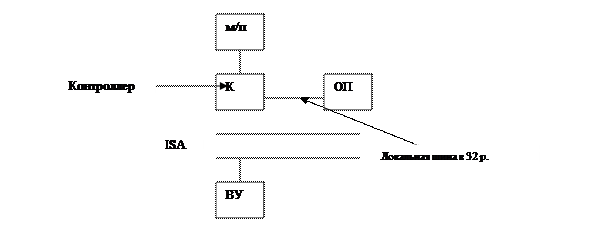
2 MCA, 16,32p, = 14 Мбайт/сек
использование в системах PS2, прекращ. существование
3 EISA, 32p, 33 Мбайт/сек
- расширенная шина ISA, прекращ. существование
3. м/п 80486
тактовая частота 33 Мгц
пропускная способность 130 Мбайт/сек
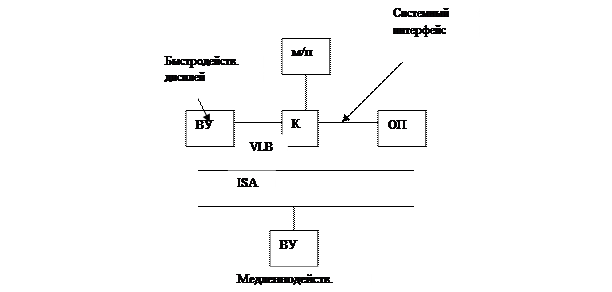
4. Pentium
PCI: 32разряда
133 Мбайт/сек
33 МГц
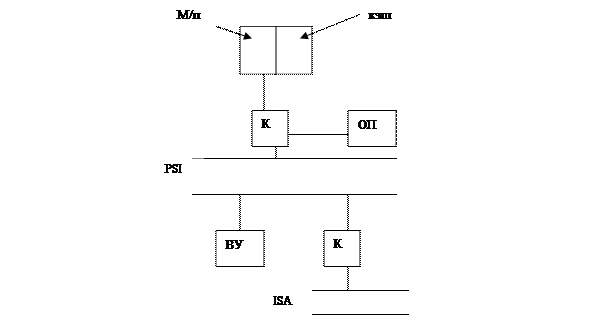
5. Pentium MMX: поддержка 3-х мерной графики
AGP: 133 МГц
633 Мбайт/сек

6. Pentium II
Системная шина 528-800 Мбайт/сек, 66-110 МГц, AGP - 500 Мбайт/сек
7. Pentium 4
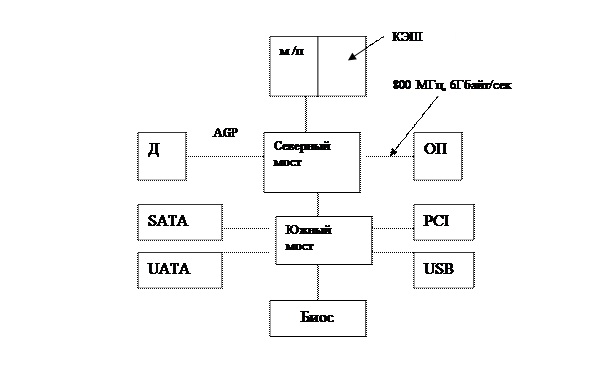
|
|
|

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...

Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!