Трудоемкость реализации АМ с помощью конкретной машины можно оценить на основе материала по низкоуровневому программированию, а также при сравнении АМ с Пи-кодом и RISK-машиной, предложенными Н. Виртом при разработке учебных языков Pascal и Oberon [4], и учебными машинами MIX и MMIX, описанными Д. Кнутом
9.
Семантический спуск от полного ЯП к его БС характеризуется сниже- нием трудоемкости реализации ядра ЯП и его АМ, сопровождаемое увеличе- нием трудоемкости применения частичной реализации ЯП. Трудоемкость применения можно оценивать числом понятий, возникающих при програм- мировании сверх тех, что присущи решению типовых задач.
Цели раскрутки:
– снижение трудоемкости начального этапа программирования;
– увеличение потенциала СП, т. е. числа типовых задач, решение которых обладает приемлемой для практики трудоемкостью.
Исследование разных схем частичных, смешанных, «ленивых» вычисле- ний и супер-метакомпиляции приводит к выводу о целесообразности совме- щения таких схем в рамках общей СП с целью использования их преиму- ществ на разных уровнях изученности решаемых задач. Частичные вычисле- ния допускают прогон программы при неполном комплекте входных данных. В результате выполняются те операции, для которых имеются данные. Одно- временно строится остаточная программа, которую можно выполнить с недо- стающими данными и получить итоговый результат, такой, как если бы все данные были заданы изначально. Смешанные вычисления допускают произ- вольную разметку программы на выполнимые и задержанные действия. Вы- полняются маршруты, которым задержанные действия не препятствуют и выводится остаточная программа, которая может быть выполнена после сня- тия блокировки с задержанных действий. «Ленивые» или отложенные вычис- ления выполняются в зависимости от необходимости операций для получе- ния результата с запоминанием промежуточных значений выражений для экономии повторных вычислений. Метакомпиляция обрабатывает про- грамму совместно с комплектом типовых данных, что дает целенаправлен- ной методику специализации программ.
|
| |  |
9 Кнут Д. Искусство программирования. Основные алгоритмы. М.: Мир, 1976. 735 с.
Система программирования может содержать пару «интерпретатор – компилятор». На практике достоинства интерпретации проявляются при от- ладке программ, а преимущества компиляции – при эксплуатации готового программного продукта. Более подробное обсуждение этой темы заслужи- вает отдельного разговора. Теория программирования утверждает, что опре- деление компилятора может быть выведено из определения интерпретатора методами смешанных вычислений. Компилятор по такой методике получа- ется как остаточная программа при смешанном вычислении интерпретатора.
Структуры данных
Кроме распределения памяти при компиляции различимы дисциплины обработки данных, обеспечивающие эффективность работы с памятью в про- цессе исполнения программ:
– new – delete – динамические запросы к системе памяти типа «куча»;
– компактизация – уплотнение пространства с целью размещения круп- ных целостных объектов;
– «близнецы» – метод укрупнения памяти и профилактики ее чрезмерной фрагментации при распределении на разно объемные блоки;
– стек – дисциплина доступа FILO;
– множество (Setl) – более 17-ти разных СД, динамически выбираемых СП для представления множеств в зависимости от характера их обработки и наличия свободной памяти.
Типичная реализация структур данных во многих системах программиро- вания:
– векторы с паспортом, хранящим при компиляции сведения о размерах и типе элементов, не доступные при исполнении программы;
– запись или структура, обеспечивающая доступ к заданному перечню разносортных элементов по статически определенным ключам;
– объединение заданного перечня разных ТД, размещаемых в разное время по одному и тому же адресу;
– множество небольшого числа перечислимых элементов, обработки ко- торых не выводят за пределы машинных команд над битовыми кодами;
– стек, совмещающий две дисциплины доступа, – FILO и вектор;
– хэш-таблицы, нормализующие время доступа к данным;
– списки и потоки, допускающие произвольное число элементов с изме- нением состава.
В результате стек хранит ссылки на границы уровней, что обеспечивает возможность возврата на любой нужный уровень, в частности, восстановле- ния процесса обработки в случае неожиданных ситуаций.
В машине списки хранятся не как последовательности символов, а как структурные формы, построенные из машинных слов как частей деревьев,
подобно записям в языке Pascal или структуры в языке C (только с типизиро- ванными указателями) при реализации односвязных списков. Преимущества списков для хранения данных в памяти:
– размер и даже число выражений, с которыми программа будет иметь дело, можно не предсказывать. Кроме того, можно не организовать для раз- мещения выражений блоки памяти фиксированной длины;
– ячейки можно переносить в список свободной памяти, как только исчез- нет необходимость в них. Даже возврат одной ячейки в список может быть полезен, но если данные хранятся линейно, то организовать использование лишнего или освободившегося пространства из блоков ячеек трудно;
– выражения, являющиеся продолжением нескольких выражений, могут быть предоставлены однократно;
– возможно размещение недовычисленных выражений над большеобъ- емными данными.
В любой момент времени только часть памяти, отведенной для списков, действительно используется для хранения полезных данных. Остальные ячейки организованы в простой список, называемый списком свободной па- мяти.
Самым интересным, можно сказать, революционным, механизмом ра- боты с памятью в языке Lisp, стала автоматизация повторного использования памяти – «сборка мусора». С начала 1960-х годов методам такой работы по- священы многочисленные исследования, которые продолжаются до наших дней и сильно активизировались в связи с включением похожего механизма в реализацию языка Java.
Общая идея всех таких методов достаточно проста:
– пока памяти хватает, о ней можно не беспокоиться и располагать новые данные в новых блоках памяти;
– если свободной памяти вдруг не оказалось, то надо выполнить «сборку мусора», в процессе которой, возможно, найдутся ставшие бесполезными для программы блоки;
– если память нашлась, ее снова можно тратить.
Специальная программа «Сборщик мусора» выполняет анализ достижи- мости всех блоков памяти простой пометкой узлов, видимых из конечного числа рабочих регистров системы программирования. К таким регистрам от- носятся промежуточные результаты вычислений, активная часть стека, ассо- циативный список, таблица атомов и др. После пометки все непомеченные узлы объединяются в список свободной памяти, передающий их для повтор- ного использования новым запросам. Такая автоматизация не лишена недо- статков.
Ряд неприятных следствий: непредсказуемые длинноты (время работы) при поиске очередной порции ячеек и «перегрев системы», если такие пор- ции слишком малы для продолжения счета. По мере роста производительно- сти оборудования разработаны простые и не столь обременительные алго- ритмы повторного использования памяти на базе параллельных процессов и профилактического копирования активных структур данных в дополнитель- ные блоки памяти. Такие методы не требуют сложной разметки и анализа до- стижимости. Кроме того, почти исключается необходимость присваиваний. Они в программах заменяются именованием.
Значительный резерв производительности функциональных программ дают деструктивные функции, являющиеся формальными аналогами чистых функций, но при выполнении сопровождаемые побочными эффектами. Такой подход позволяет при необходимости повышать эффективность программ, от- лаженных в стиле без использования присваиваний, простым привлечением деструктивных аналогов функций под ответственность программиста, точно знающего границы допустимых изменений хранимых данных.
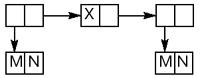
Непосредственная польза от сопоставления графического вида с пред- ставлением списков в памяти поясняется при рассмотрении функций, рабо- тающих со списками, на следующем примере, приведенном в руководстве по языку Lisp 1.5 [22]:
Диаграмма Пояснение
При создании структур много- кратные вхождения одинако- вых данных получают незави- симое расположение в памяти.
Рис. 6. Пример ((M. N) X (M. N))
Возможное для списков использование общих фрагментов ((M. N) X (M. N)) может быть представлено графически.
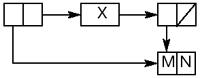
Диаграмма Пояснение
Слияние многократных вхож- дений одинаковых данных.
Рис. 7. Графическое представление эффективного размещения данных
Непосредственное текстовое представление в точности такой структуры невозможно, но ее можно построить с помощью одного из Lisp-выражений:
(LET ((a '(M. N))) (SETQ b (LIST a 'X a)))
((LAMBDA (a) (LIST a 'X a))'(M. N))
Реализационная прагматика
При классификации ЯСП ключевое значение имеет семантика, но для уяс- нения преимуществ ПП, поддерживаемой ЯП, требуется понимание реализа- ционной прагматики (РП), которая может быть не представлена в определе- нии или стандарте ЯП, но подразумеваться традиционно.
Реализационная прагматика, затрагивая все уровни определения ЯП, в ос- новном представляет решения в области конкретной организации работы с памятью, уточняющей решения и принципы, провозглашенные в определе- нии АМ. В первую очередь это относится к вопросам защиты областей па- мяти и их конечности, т. е. реагирования на дефицит памяти.
Реализационная прагматика, поддерживающая разные ЯП:
– списки, мусорщик, списки свойств атома (ФП);
– побочные эффекты, векторы, типы данных (ИП);
–
разностные списки, последовательный перебор, откатка (ЛП);
– ссылки, виртуальные и абстрактные методы и классы, множественное наследование (ООП).