

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Эмиссия газов от очистных сооружений канализации: В последние годы внимание мирового сообщества сосредоточено на экологических проблемах...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Эмиссия газов от очистных сооружений канализации: В последние годы внимание мирового сообщества сосредоточено на экологических проблемах...
Топ:
Когда производится ограждение поезда, остановившегося на перегоне: Во всех случаях немедленно должно быть ограждено место препятствия для движения поездов на смежном пути двухпутного...
Проблема типологии научных революций: Глобальные научные революции и типы научной рациональности...
Характеристика АТП и сварочно-жестяницкого участка: Транспорт в настоящее время является одной из важнейших отраслей народного...
Интересное:
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Инженерная защита территорий, зданий и сооружений от опасных геологических процессов: Изучение оползневых явлений, оценка устойчивости склонов и проектирование противооползневых сооружений — актуальнейшие задачи, стоящие перед отечественными...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
СТРУКТУРЫ ДАННЫХ И
АЛГОРИТМЫ ОБРАБОТКИ. Часть 1
 |
Утверждено редакционно-
издательским советом
университета в качестве
учебного пособия
Вологда 2005
УДК 681.3.06
ББК Р23
Рецензенты:
Сипин А.С., к.ф-м.н, доцент кафедры Прикладной математики ВГПУ
Кузнецов Р.Н., директор учебного центра "Мезон"
Ржеуцкая С.Ю., Андрианов И.А.
Структуры и алгоритмы обработки данных. Часть 1: Учеб. пособие. - Вологда: ВоГТУ, 2005. – 232 с.
ISBN 5-87851-152-5
Учебное пособие предназначено для студентов специальности 230105 – программное обеспечение вычислительной техники и автоматизированных систем, но может быть полезно студентам всех специальностей, связанных с компьютерными технологиями. Первая часть содержит определение основных понятий, анализ и реализацию линейных и иерархических структур данных и алгоритмов сортировки и поиска.
УДК 681.3.06
ББК Р23
©Вологодский государственный
технический университет, 2005
ISBN 5-87851-152-5 ©Ржеуцкая С.Ю.,
Андрианов И.А.
Введение
Пособие предназначено для студентов специальности 230105 — «Программное обеспечение вычислительной техники и автоматизированных систем», но может использоваться студентами других специальностей, связанных с компьютерными технологиями, в качестве дополнительного материала.
Исследование структур данных и алгоритмов их обработки — это основа, на которой держатся все остальные компьютерные науки. Грамотное решение задач в любой области программирования невозможно без обширных и прочных знаний типовых структур данных и алгоритмов.
Несмотря на динамичное развитие различных направлений информационных технологий, в этой области положение довольно стабильно. Конечно, новые задачи часто требуют нестандартных решений, поэтому набор востребованных структур данных и алгоритмов постоянно пополняется. Тем не менее, основные способы организации данных и алгоритмы их обработки хорошо проработаны, имеется несколько фундаментальных учебников и монографий по этому вопросу, например [7,9,2,13].
|
|
При изложении авторы в основном ориентируются на известные, много раз переиздававшиеся фундаментальные работы. Мы старались изложить лаконично и систематизированно материал, почерпнутый из большого количества источников, дополнить его собственными примерами и сведениями о современном состоянии некоторых проблем. Иногда в различных источниках встречается несогласованность терминологии. В этом случае употребляются наиболее распространенные термины, а остальные все-таки упоминаются со ссылкой на авторов.
Все примеры в пособии написаны на языке С++, при этом авторы старались сделать тексты программ понятными, поэтому использовали такие конструкции языка, которые не затрудняют чтение исходных текстов. Мы стремились показать различные подходы к программированию алгоритмов обработки данных, поэтому там, где это уместно, использовался объектно-ориентированный подход и шаблоны. Сделано и небольшое введение в функциональное программирование в разделах, посвященных рекурсивной обработке линейных и иерархических списков.
Пособие содержит десять глав. В первой из них определяются основные понятия и дается первое введение в анализ алгоритмов. Вторая и третья главы содержат довольно подробное описание линейных и иерархических структур данных с примерами реализации. Три следующих главы посвящены практически важным задачам сортировки и поиска данных, причем в шестой главе рассматриваются способы сортировки и поиска данных во внешней памяти. Затем разбирается обширная группа методов и алгоритмов для решения задач дискретной оптимизации под общим названием «исчерпывающий поиск». Восьмая глава посвящена классическим алгоритмам на графах. В следующей главе разбираются алгоритмы поиска в текстовых последовательностях, которые в последнее время приобретают повышенную актуальность в связи с массовым распространением поисковых систем. Наконец, последняя глава содержит введение в NP-полные задачи и способы их приближенного решения.
|
|
Представленный материал полностью охватывает программу курса «Структуры данных и алгоритмы обработки» и может использоваться в качестве учебника по данной дисциплине.
В качестве дополнения к пособию следует использовать методические указания по структурам и алгоритмам обработки данных, в которых содержатся практические задания.
1. Основные понятия и определения
Первая глава является вводной и посвящена определению основных понятий.
Разумеется, способы организации данных и алгоритмы их обработки нельзя рассматривать отдельно друг от друга. Однако в рамках данной главы полезно сначала сосредоточиться на терминологии, которая относится к определению данных, а затем разобрать наиболее фундаментальные понятия, касающиеся алгоритмов. Здесь уместно привести высказывание Фредерика П.Брукса. «Покажите мне ваши блок-схемы и спрячьте таблицы, и я ничего не пойму. Покажите мне таблицы, и блок-схемы мне не понадобятся — все будет очевидно и так.» Таблицы (дословный перевод английского tables) — это структуры данных, а блок-схемы — способ записи алгоритмов. Иными словами, выбор структур данных определяет используемые алгоритмы. Возможно, это чересчур упрощенный подход, но важность грамотного выбора способов организации данных нельзя оспорить[14].
Существует несколько фундаментальных понятий, которые относятся к определению данных. Это типы данных, абстрактные типы данных и структуры данных. Разберем данные понятия по порядку.
1.1. Типы данных
Понятие типа данных
Понятие типа данных хорошо проработано в начальном курсе программирования, поэтому кратко остановимся только на тех моментах (и терминологии), которые важны для дальнейшего изложения.
Любая переменная, константа, а также значение выражения или функции относятся к определенному типу данных.
Тип данных о пределяет множество допустимых значений данных и множество операций над этими значениями.
|
|
Все типы данных, используемые в языках высокого уровня, можно разделить на две большие группы:
· скалярные (простые);
· структурированные (составные, конструируемые).
Скалярные типы, в свою очередь, делятся на несколько групп:
· базовые (встроенные в язык), т. е. типы, предопределенные в языке программирования;
· производные от базовых (например, перечисляемый тип или диапазон в языке Pascal);
· ссылочные типы (указатели), обеспечивающие возможность работы с множеством абстрактных адресов памяти.
Структурированные (конструируемые) типы имеют в своей основе скалярные типы данных и используются для определения совокупностей данных. В языке программирования предопределены средства спецификации таких типов и некоторый набор операций, дающих возможность доступа к отдельным элементам составных значений.
Большинство языков программирования представляет стандартный набор структурированных типов:
· массивы (в том числе строки — массивы символов);
· записи (в языке С они называются структурами, аналоги записей с вариантами — объединения);
· в некоторых языках, например в Pascal, есть множества.
Важно отметить, что в языке высокого уровня внутреннее представление типа данных скрыто от программиста, а доступ к значениям типа осуществляется через предопределенный набор операций, реализация которых также скрыта. Такой принцип называется инкапсуляцией, и это обозначает, что внутреннее представление данных как бы заключено в непроницаемую капсулу, а доступным является лишь внешнее представление типа, содержащееся в описании языка.
Внутреннее представление данных, размер выделяемой памяти и реализация операций предоставляются на усмотрение разработчиков компиляторов. Единственное, что предоставляют практически все языки программирования, — операция sizeof(тип) для определения размера области памяти, отводимой под переменную заданного типа.
Все же полное незнание внутренего представления стандартных типов в языках высокого уровня может привести к многочисленным ошибкам при реализации алгоритмов. Поэтому очень кратко остановимся на этом вопросе.
|
|
Понятие структуры данных
Наиболее общим и фундаментальным понятием в определении данных является понятие структуры данных.
Определим структуру данных как совокупность элементов данных, между которыми установлены определенные отношения (связи) [14].
Это определение имеет столь общий характер, что может использоваться в различных случаях, имея несколько разный смысл. Рассмотренные выше конструируемые типы данных обычно относят к элементарным структурам данных. Возможно, по этой причине конструируемые типы данных часто называют структурированными, а запись в языке С называется структурой. В дальнейшем не будем путать структуры в смысле языка С со структурами данных в широком понимании.
Кроме структурированных типов данных имеется еще ряд структур данных, которые относят к элементарным или базовым, хотя в большинство языков программирования не встроена их явная поддержка. Эти структуры будут подробно рассмотрены в следующих разделах, а затем будут использоваться как элементарные кирпичики при конструировании более сложных структур данных или описании алгоритмов.
Структуры данных принято рассматривать на двух уровнях — логическом и физическом. На логическом (абстрактном или внешнем) уровне рассматриваются наиболее существнные признаки структуры, которые не зависят от способа внутреннего представления данных в памяти. Возможность анализа структуры данных на логическом уровне обеспечивает концепция АТД, рассмотренная выше.
На физическом (внутреннем) уровне рассматривается конкретный способ представления структуры в оперативной памяти. При этом принимается во внимание как способ хранения самих элементов данных, так и способ представления отношений между данными. В этом случае иногда используются такие термины как структура хранения или внутренняя структура.
Внутреннее представление структур данных оказывает очень сильное влияние на реализацию алгоритмов, поэтому рассмотрим этот вопрос подробнее.
Вычислительные модели
Алгоритмы создаются для конкретного исполнителя, и при разработке алгоритма разработчик ориентируется на его возможности – доступные ресурсы, операции и стоимости их использования. Все эти факторы учитываются в так называемой вычислительной модели [10].
В теоретических исследованиях, когда основной интерес представляет доказательство конечности алгоритма и его правильности, рассматривают вычислительные модели, удобные для анализа (но не для программирования!), с которыми легче работать математикам. Одна из наиболее известных таких моделей - машина Тьюринга.
|
|
При разработке и анализе "практических" алгоритмов чаще всего в качестве вычислительной модели рассматривается так называемая машина с произвольным доступом, которая, по существу, является моделью современного компьютера. В такой модели имеется оперативная память и один процессор, который последовательно выполняет инструкции программы в оперативной памяти. При этом задан набор инструкций, поддерживаемых процессором – арифметические операции, пересылка данных, управление выполнением программы. Каждая инструкция выполняется за константное время.
В модели с внешней памятью, кроме быстрой памяти ограниченного объёма, имеется также внешняя память, обращения к которой производятся значительно медленнее, а обмен данными идёт блоками фиксированного размера (страницами).
В некоторых задачах требуется модель многопроцессорной машины с возможностью распараллеливания вычислений и др.
Обычно можно преобразовать алгоритм, рассчитанный на одну вычислительную модель, в алгоритм для другой модели, решающий ту же саму задачу (правда, вследствие преобразований исходный алгоритм может измениться до такой степени, что превратится по существу в уже другой алгоритм).
Время работы алгоритма
Пусть n – размер входа (для задач, где размер входа задаётся несколькими числами, рассуждения будут аналогичны). Определим более точно, что понимать под временем работы алгоритма. Поскольку алгоритм – это ещё не программа для конкретной вычислительной машины, время его работы нельзя измерять, например, в секундах. Обычно под временем работы алгоритма понимают число элементарных операций, которые он выполняет. При этом, если алгоритм записан на каком-то псевдокоде или языке высокого уровня, предполагается, что выполнение одной строки требует не более чем фиксированного числа операций (если, конечно, это не словесное описание каких-то сложных действий).
Примечание
Действуя более формально, мы могли бы записать алгоритм с помощью инструкций предполагаемой вычислительной модели, назначить каждой из них некую стоимость и вывести выражение для стоимости алгоритма. Однако, это достаточно трудоёмко и в большинстве случаев не требуется.
Рекурсия и итерация
Рекурсия — это такой способ организации вычислительного процесса, при котором подпрограмма в ходе выполнения обращается сама к себе.
Рекурсия широко применяется в математике. В качестве примера дадим рекурсивное определение суммы первых n натуральных чисел. Сумма первых n натуральных чисел равна сумме первых (n – 1) натуральных чисел плюс n, а сумма первого числа равна 1. Или: Sn = Sn-1 + n; S1 = 1.
Напишем функцию, которая вычисляет сумму, пользуясь данным определением:
int sum(int n)
{ if (n==1) sum=1; else sum=sum(n-1)+n;
}
Обратим внимание на следующие обстоятельства.
Рекурсивная функция содержит всегда, по крайней мере, одну терминальную ветвь и условие окончания (if (n==1) sum=1).
При выполнении рекурсивной ветви (else sum=sum(n-1)+n) процесс выполнения функции приостанавливается, но его переменные не удаляются из стека. Происходит новый вызов функции, переменные которой также помещаются в стек и т.д. Так образуется последовательность прерванных процессов, из которых выполняется всегда последний, а по окончании его работы продолжает выполняться предыдущий процесс. Целиком весь процесс считается выполненным, когда стек опустеет, или, другими словами, все прерванные процессы выполнятся.
Большинство алгоритмов можно реализовать двумя способами: итерацией (т. е. с помощью цикла) и рекурсией. Так, приведенный пример с суммой легко реализуется при помощи цикла, причем это решение более эффективное, т. к. не требует дополнительных расходов стековой памяти. Вообще, если задача имеет очевидное нерекурсивное решение, то следует избрать именно его.
Пример анализа рекурсивного алгоритма
В качестве более интересного примера применения рекурсии рассмотрим следующую задачу. Требуется возвести число a в степень b (a и b – натуральные). Если решать данную задачу «в лоб», то нам потребуется выполнить b умножений: ab=a·a·a…·a (b раз). Однако,
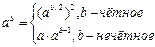
Например, можно вычислять ab, используя следующие соображения: 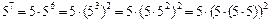 - итого всего 4 операции умножения, а не 7.
- итого всего 4 операции умножения, а не 7.
Несложно написать рекурсивную функцию, выполняющую вычисления по данной формуле:
unsigned int pow(unsigned int a, unsigned int b)
{ if (b==1) return a; //терминальная ветвь
else
if (b % 2 == 0)
{ unsigned int p = pow(a,b/2);
return p*p;
}
else return pow(a,b-1)*a;
}
Оценим время выполнения данного алгоритма в худшем случае.
При выполнении функции pow число b, передаваемое при рекурсивном вызове, либо делится на 2 (если оно чётное), либо уменьшается на 1 (если оно нечётное) и тем самым становится чётным. Отсюда можно сделать вывод, что после двух последовательных рекурсивных вызовов число b уменьшится не менее чем в два раза. Рекурсия остановится, когда b станет равным 1. Таким образом, если k-общее число вызовов, то получается следующее соотношение:
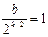 ,
,
откуда k=2log2b. Поскольку другие операции внутри рекурсивной функции выполняются за константное время, то, пренебрегая мультипликативной константой 2 и основанием логарифма, получим точную асимптотическую оценку T(b)= Θ (logb), где b — степень (целое число), в которую возводится целое число a.
Отметим, что наименьшее число операций алгоритм будет выполнять, если b является степенью двойки. В этом случае при каждом рекурсивном вызове аргумент будет уменьшаться в два раза. Тогда общее число вызовов k найдётся так:
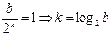
Отсюда заключаем, что асимптотическая оценка для наилучшего случая совпадает с оценкой для наихудшего случая, причем это точная асимптотическая оценка, т. к. она получена на основе точно рассчитанного выражения для оценки времени выполнения алгоритма путем отбрасывания мультикативной константы.
Несложно показать, что аналогичная оценка выполняется и для памяти: M(b)=Θ(logb) – при каждом рекурсивном вызове в стек помещается некоторое постоянное число байт – локальные переменные и параметры функции.
1.7. Первые примеры
В качестве первых примеров подобраны небольшие задачи-этюды, решение которых не требует никаких специальных знаний, но позволяет освоить или закрепить некоторые полезные приемы программирования, которые могут найти применение и при решении серьезных задач. Они сгруппированы по темам.
Примеры рекурсивных алгоритмов
Пример 1. Последовательность чисел Фибоначчи определяется так:a(0)= 1, a(1) = 1, a(k) = a(k-1) + a(k-2) при k >= 2. Первые члены этой последовательности: 1 1 2 3 5 8 13 21 и т. д. Дано n, вычислить a(n).
Задача имеет очевидное нерекурсивное решение, имеющее сложность C*n. При больших n вычисления могут занять много времени, поэтому приведем быстрый рекурсивный алгоритм решения этой задачи. Пара соседних чисел Фибоначчи получается из предыдущей умножением на матрицу
|1 1|
|1 0|
(проверьте сами), так что задача сводится к возведению матрицы в степень n. Это можно сделать за C*log n действий при помощи примерно такого же рекурсивного алгоритма, что и для возведения числа в степень (см. разд. 1.6.2).
#include <iostream.h>
typedef int Matr[2][2];
void mult(Matr t1, Matr t2, Matr p)
{ p[0][0] = t1[0][0]*t2[0][0] + t1[0][1]*t2[1][0];
p[0][1] = t1[0][0]*t2[1][0] + t1[0][1]*t2[1][1];
p[1][0] = t1[1][0]*t2[0][0] + t1[1][1]*t2[1][0];
p[1][1] = t1[1][0]*t2[1][0] + t1[1][1]*t2[1][1];
}
void power(Matr t, int n)
{ Matr tmp,tmp2;
if (n==0)
{ t[0][0] = 1; t[1][1] = 1; t[1][0] = 0; t[0][1] = 0;
return;
}
if (n%2==0)
{ power(t,n/2); mult(t,t,tmp); memcpy(t,tmp,4*sizeof(int));
}
else
{ memcpy(tmp,t,4*sizeof(int)); power(t,n-1); mult(tmp,t,tmp2);
memcpy(t,tmp2,4*sizeof(int));
}
}
int main(void)
{ Matr t = {1,1,1,0};
power(t,10); cout << t[0][0] << endl;
return 0;
}
Многие задачи, требующие перебора различных вариантов, имеют компактное рекурсивное решение. Приведем пример одной из таких задач.
Пример 2. Перечислить все представления положительного целого числа n в виде суммы последовательности невозрастающих целых положительных слагаемых. Например, для числа 3 таких представлений будет всего два:
2+1 и 1+1+1.
#include <iostream.h>
int a[1000];
void summa(int n, int max, int k)
{ if (n<max) max=n;
for (int i=max; i>0; i--)
{ a[k]=i;
if (i==n)
{ for (int i=0; i<k; i++) cout<<a[i]<<"+";
cout<<a[k]<<endl;
}
else summa(n-i,i,k+1);
}
}
void main()
{ int n;
cout<<"Введите число N: "; cin>>n;
summa(n,n,0);
}
Линейные структуры данных
К линейным структурам данных относятся различные виды линейных списков.
Линейный список представляет собой такой способ организации совокупности элементов одного типа, при котором, каждый элемент, кроме первого, имеет одного предшественника (предыдущий элемент) и каждый элемент, кроме последнего, имеет одного преемника (следующий элемент). Если последний элемент имеет в качестве преемника первый элемент, а первый в качестве предшественника — последний, то такой список называют кольцевым (циклическим).
Специальными видами линейных списков с ограниченным набором операций являются стеки, очереди, деки. С них удобно начать изложение, поскольку набор базовых операций в этих структурах существенно ограничен по сравнению с произвольными списками, а реализация этих операций не должна вызвать затруднений. Между тем эти структуры используются при решении различных задач, в частности, многие алгоритмы, которые будут рассматриваться в следующих разделах пособия, будут опираться именно на применение стеков или очередей как элементарных структур данных.
Далее будет рассмотрено два основных подхода к обработке линейных списков — итеративная обработка списка с выделенным текущим элементом и рекурсивная обработка списка. При изложении первого подхода отдельно рассмотрим однонаправленные и двунаправленные списки (Л1-списки и Л2-списки [12]), а также особенности кольцевых списков.
Изложение материала строится так. Сначала каждая структура рассматривается на логическом уровне как абстрактный тип данных. Затем рассматриваются различные способы реализации с небольшими фрагментами программного кода на С++. В заключение приводятся примеры программ, использующих данные структуры.
2.1. АТД "Стек", "Очередь", "Дек"
Деки
Иногда используют списки, в которых вставка и удаление элементов выполняются с обоих концов. Такой список называется деком. (сокращение от английского double ended queue- о чередь с двумя концами).
Дек представляет собой универсальную структуру данных, которая может функционировать и как стек, и как очередь. В качестве частных случаев различают деки с ограниченным вводом, в которых на одном конце не разрешена вставка, и деки с ограниченным выводом, где не разрешено удаление на одном из концов.
Формальную спецификацию дека можно выполнить аналогично стеку или очереди.
Реализация стеков
Примеры программ с использованием стеков
Стеки широко используются при разработке трансляторов, например, при анализе и вычислении арифметических выражений. Эта задача является предметом отдельного курса, но в качестве введения в проблему приведем компактные примеры анализа и преобразования скобочного выражения.
Пример 1.
Приведенная программа проверяет правильность расстановки скобок в заданной строке текста, длина которой в принципе не ограничена. При этом просматриваются все символы скобок: круглых, квадратных и фигурных. Учитывается, что различные скобки могут быть вложены одна в другую. Список из открывающихся скобок строится по принципу стека. Это значит, что та скобка, которая была помещена в стек последней, будет извлечена из него первой, и легко проверить, соответствует ли закрывающая скобка своей открывающей. Все остальные символы программа игнорирует.
Для проверки соответствия скобок используются две вспомогательные строки с открывающимися и закрывающимися скобками. Стандартная функция strchr() возвращает указатель на найденный символ, поэтому, чтобы найти номер данного символа, приходится вычитать из этого указателя указатель на начало строки. Все остальное просто.
Листинг 2.1 Проверка правильности расстановки всех видов скобок в строке
#include <iostream.h>
#include "stack.h"
#include "stack.cpp"
void main()
{ char s[80];
cout<<"Введите строку, содержащую скобки "; cin.getline(s,80);
stack<char> st;
char *kind1="([{", *kind2=")]}";
for (int i=0; i<strlen(s); i++)
{ if(strchr(kind1,s[i])) st.push(s[i]);
if(strchr(kind2,s[i]))
if((st.isnull())||(strchr(kind1,st.pop())-kind1!=strchr(kind2,s[i])-kind2))
{ cout<<"Ошибка!";cin.get(); return;
}
}
if (!st.isnull()) cout<<"Ошибка!";
else cout<<"Ошибок нет";
st.makenull(); cin.get();
}
Пример 2.
Усложним задачу. Пусть имеется скобочное выражение, в котором присутствуют только круглые скобки. Требуется скобки самого глубокого уровня вложенности оставить без изменения, скобки следующего уровня заменить на квадратные, а все остальные скобки заменить на фигурные.
Листинг 2.2 Преобразование скобок
#include <iostream.h>
#include "stack.h"
#include "stack.cpp"
int main()
{ char s[80]; stack<char> st;
cout<<"Введите строку, содержащую только круглые скобки "; cin.getline(s,80);
int l; //Уровень вложеннности скобок в данный момент
for (int i=0; i<strlen(s); i++)
{ if (s[i]=='(') {st.push(i); l=1;}
if (s[i]==')')
if (st.isnull()) {cout<<"Ошибка!!!"; cin.get(); return 1;}
else {
int p=st.pop();
if (l==2) {s[p]='['; s[i]=']';}
if (l>2) {s[p]='{'; s[i]='}';}
l++;
}
}
if (!st.isnull()) cout<<"Ошибка!!!";
else cout<<"Получили:\n"<<s;
st.makenull(); cin.get();
}
Реализация очередей
Очереди с приоритетами
В реальных задачах часто возникает необходимость организации очередей, принцип работы которых отличен от FIFO. Порядок выборки элементов в них определяется приоритетами элементов. Приоритет — это некоторое числовое значение, связанное с элементами очереди, в простейшем случае, это может быть само значение элемента. При выборке элемента из очереди каждый раз выбирается элемент с наибольшим приоритетом.
Различают два способа реализации очередей с приоритетами.
1. Очереди с приоритетным включением. В этом случае очередь всё время поддерживается упорядоченной, т.е. каждый новый элемент помещается в то место очереди, которое определяется его приоритетом.
2. Очереди с приоритетным исключением. Новые элементы помещаются в конец очереди, при исключении элемента отыскивается элемент с максимальным приоритетом.
Реализация очередей с приоритетами на базе отсортированных массивов или списков используется при небольшом количестве элементов такой очереди. При небольшом количестве приоритетов может использоваться так называемый корзинный способ. Наиболее удобной формой реализации больших очередей с приоритетами является реализация с помощью частично упорядоченных деревьев.
Пример программы с использованием очереди
Очереди также часто, как и стеки, используются в качестве элементарных структур данных при реализации более сложных структур и алгоритмов. В следующих разделах будет достаточно примеров использования очередей, один из примеров приведем ниже (подробнее с алгоритмом решения аналогичных задач можно познакомиться в главе 8, посвященной алгоритмам на графах).
Пример. Лабиринт представляет собой клетчатое поле NxM клеток, некоторые из них пустые, другие закрашены - через них проходить нельзя. За один шаг можно перейти из текущей клетки в одну из свободных соседних. Требуется найти длину кратчайший путь из левого верхнего угла в правый нижний. Лабиринт считывается из текстового файла input. txt, где в первой строке записаны числа N и M (через пробел), а в каждой из последующих N строк находятся M символов информации о клетках лабиринта. При этом символ пробела обозначает пустую клетку, символ 'x' - закрашенную. Результат работы программы выводится на экран.
Идея решения состоит в следующем («метод волны»). Для начала определим тип элементов очереди как структуру из трёх полей — координаты клетки и число шагов до неё от левого верхнего угла:
struct cell
{ int x,y,l;
};
typedef cell type_of_data;
После чтения информации о лабиринте создаем очередь и помещаем в нее первый элемент с координатами левого верхнего угла и числом шагов 0.
На каждом шаге извлекаем очередной элемент, смотрим, в какие соседние клетки можно переместиться из текущей, и помещаем в очередь элементы, соответствующие этим клеткам. При этом для них делаем количество шагов на единицу больше, чем для извлечённого элемента. После этого необходимо пометить текущую клетку как закрашенную, чтобы не возвращаться в нее в дальнейшем, и перейти к извлечению нового элемента из очереди.
В конце концов либо окажется, что очередь пуста (это означает, что все возможные пути пройдены, и все свободные клетки помечены), либо очередной из извлеченных элементов окажется с координатами правого нижнего угла. В последнем случае количество шагов в структуре и будет решением задачи, т.е. длиной кратчайшего пути. Это объясняется тем, что элементы в очередь помещаются по возрастанию количества шагов.
#include <fstream.h>
#include "queue.h"
main() {
ifstream fi("input.txt");
int N,M;
fi>>N>>M; fi.get(); //Считывание размеров лабиринта
char s[100]; int a[10][10], i, j;
for (i=0; i<N; i++) { //Чтение информации о клетках
fi.getline(s,100);
for (j=0; j<M; j++) {
if (s[j]=='.') a[i][j]=0;
else a[i][j]=1;
}
}
queue q; // Очередь абсцисс, ординат и длин путей
cell c;
// Заносим в очередь первую клетку:
c.x=0; c.y=0; c.l=0; q.enqueue(c);
int len;
while (!q.isnull())
{c=q.gethead(); q.dequeue();
i=c.y; j=c.x; len=c.l;
if ((i==N-1)&&(j==M-1)) break; // Путь найден
// Проверяем соседние с (i,j) клетки:
c.l++; //увеличиваем путь на 1
if((i>0)&&(!a[i-1][j])){c.y--; q.enqueue(c); c.y++;}
if((i<N-1)&&(!a[i+1][j])){c.y++;q.enqueue(c);c.y--;}
if((j>0)&&(!a[i][j-1])){c.x--; q.enqueue(c); c.x++;}
if((j<M-1)&&(!a[i][j+1])){c.x++;q.enqueue(c);c.x--;}
a[i][j]=1;
}
if((i==N-1)&&(j==M-1))cout<<"Длина кратч. пути"<<len;
else {
q.makenull();
cout<<"Путь в лабиринте не найден.";
}
cin.get(); return 0;
}
Стеки и очереди являются частными случаями более универсальной структуры данных— линейных списков.
Операции над списками
Набор операций над списками существенно расширен по сравнению со стеками или очередями. В первую очередь это касается операций вставки и удаления — их теперь можно выполнять не только на концах, но в любой позиции списка, в зависимости от положения текущего элемента.
Операция вставки неформально определяется так — вставить элемент перед текущим, при этом текущим должен стать новый элемент. Особый случай вставки — новый элемент добавляется в конец списка.
При удалении текущего элемента следующий становится текущим. Нельзя удалять из пустого списка.
Одна из часто выполняемых операций над списками — получение значения текущего элемента. Можно выделить отдельную операцию изменения значения текущего элемента. Хотя ее можно представить как последовательность из двух операций (удаления с последующей вставкой), это будет неудобно в реализации.
Для любых списков требуются дополнительные операции создания пустого списка и проверки списка на наличие в нем хотя бы одного элемента.
Поскольку все базовые операции определяются относительно текущего элемента, обязательно должна быть обеспечена возможность изменения текущего элемента, иными словами, механизм передвижения по списку. Различные виды списков отличаются друг от друга именно по возможности передвижения по списку. Определим соответствющие абстрактные типы данных.
Однонаправленные списки
Двусвязные списки
Схематическое изображение двусвязного списка на основе указателей показано на рис.2.
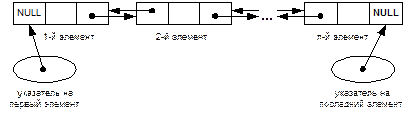 Рис.2.14. Двусвязный список
Рис.2.14. Двусвязный список
При работе с двусвязным списком уже не нужен дополнительный указатель на элемент, предшествующий текущему, т. к. все необходимые указатели есть в каждом элементе, а значит, для выполнения вставок и удалений достаточно только указателя на текущий элемент. Однако для реализации все-таки опять потребуется три дополнительных указателя — на первый, последний и текущий элементы (например, first, last, cur). Они являются формуляром списка и их значения полностью определяют состояние списка.
Структуры, описывающие двунаправленный спиоск, могут иметь, например, такой вид:
struct item //один элемент списка
{type_of_data data;
item *next, *prev;
};
struct list_l2 // структура списка
{ item *first, *last; *cur;//указатели на первый, последний и текущий элементы.
//прототипы функций
...
};
Также, как и для списков Л1, можно выделить три особых состояния:
· head=last=cur=NULL — список пуст, в этом состоянии нельзя удалять элементы, первый добавленный элемент будет одновременно и началом и концом списка;
· head ≠ NULL; last ≠ NULL;cur=head — «начало списка»; в этом состоянии новый элемент вставляется перед первым;
· head ≠ NULL; last ≠ NULL; cur=NULL; — «конец списка», в этом состоянии новый элемент вставляется после последнего, а удалить текущий элемент нельзя.
Обратим внимание, что в двунаправленном списке размер каждого элемента списка больше, чем в однонаправленном, поскольку указующая часть содержит не один, а два указателя. Фактически каждый указатель хранится два раза, поскольку каждый элемент, кроме первого и последнего, имеют и предыдущий, и следующий. Интересно отметить, что в случае ссылочной реализации с использованием массива можно хранить не два индекса (next и prev), а одно значение, равное разности next-prev. Нетрудно убедиться, что имея такие разности и зная индексы первого и последнего элемента списка, можно без труда восстановить цепочки индексов как при движении в прямом, так и в обратном направлении. В этом случае мы даже не увеличиваем расход памяти под элементы списка по сравнению с Л1, правда немного проигрываем в быстродействии при обходе списков за счет необходимости вычисления индексов.
В целом реализация функций для работы с двунаправленными списками выполняется аналогично однонаправленным спискам, поэтому это можно проделать самостоятельно.
Кольцевые списки
В кольцевом списке вообще нет пустых указателей, поскольку крайние элементы указывают друг на друга. Кольцевые списки могут быть как односвязными, так и двусвязными (на рис. 2.15. кольцевой список является односвязным).
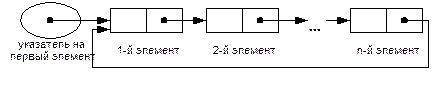 Рис.2.15. Кольцевой односвязный список
Рис.2.15. Кольцевой односвязный список
Реализация операций с кольцевыми списками отличается от линейных списков только деталями, связанными с крайними элементами.
Примеры программ, использующих списки
Иерархические списки
Деревья и леса
Другой подход к представлению иерархических структур представляют собой деревья и леса. Это достаточно распространенные структуры, которые используются как базовые большим количеством алгоритмов обработки данных, и в связи с этим заслуживают самого пристального внимания.
В данной главе сосредоточим максимум внимания на общих свойствах деревьев и лесов как структур данных, которые будут использоваться при изучении следующих разделов. Для этого сначала рассмотрим их как абстрактные математические объекты, а затем перейдем к формальной функциональной спецификации и различным формам реализации.
Особый вид деревьев — бинарные — будут рассмотрены отдельно.
Определения
Когда речь идет об иерархических структурах, то под термином «дерево» обычно понимают дерево с корнем (корневое дерево). Однако заметим, что корневое дерево — это частный случай более общего определения дерева, называемого иначе свободным деревом. Свободные деревья, в свою очередь, являются частным случаем графов и определяются в терминах теории графов. Они будут рассмотрены позже. В данной главе будем рассматривать только корневые деревья, называя их просто деревьями.
Формально дерево можно рекурсивно определить следующим образом [8].
Дерево (tree) — конечное множество T одного или более узлов (nodes) со следующими свойствами:
1. Существует один выделенный узел, называемый корнем (root) этого дерева T. Дерево может состоять и из одного корня.
2. Остальные узлы (если они есть) распределены среди k непересекающихся множеств T1, Т2,..., Tk, и каждое их этих множеств, в свою очередь, является деревом. Деревья T1, Т2,..., Tk называются поддеревьями (subtrees) этого корн
|
|
|

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...

Таксономические единицы (категории) растений: Каждая система классификации состоит из определённых соподчиненных друг другу...

Наброски и зарисовки растений, плодов, цветов: Освоить конструктивное построение структуры дерева через зарисовки отдельных деревьев, группы деревьев...

Автоматическое растормаживание колес: Тормозные устройства колес предназначены для уменьшения длины пробега и улучшения маневрирования ВС при...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!