

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Топ:
Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда...
Эволюция кровеносной системы позвоночных животных: Биологическая эволюция – необратимый процесс исторического развития живой природы...
Марксистская теория происхождения государства: По мнению Маркса и Энгельса, в основе развития общества, происходящих в нем изменений лежит...
Интересное:
Распространение рака на другие отдаленные от желудка органы: Характерных симптомов рака желудка не существует. Выраженные симптомы появляются, когда опухоль...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
При трансляции программы для каждого нового идентификатора в таблицу символов добавляется элемент. Однако поиск элементов ведется всякий раз, когда встречается этот идентификатор. Так как на этот процесс уходит много времени, необходимо выбрать такую организацию таблиц, которая допускала бы прежде всего эффективный поиск.
Простейший способ организации - использовать неупорядоченную таблицу. Новый элемент добавляется в таблицу в порядке поступления. Среднее время поиска пропорционально n/2 (в среднем приходится делать n/2 сравнений).
Элементы таблицы можно отсортировать. Тогда можно использовать процедуру бинарного поиска, при котором максимальное число сравнений будет равно 1+log2n. Однако сортировка – это слишком трудоемкая процедура для того, чтобы ее использовать при организации таблиц.
ХЕШ-АДРЕСАЦИЯ
Идеальный вариант – уметь по имени сразу определить адрес элемента. В этом смысле "хорошей" процедурой поиска является та, которая сможет определить хотя бы приблизительный адрес элемента. Одним из наиболее эффективных и распространенных методов реализации такой процедуры является хеш-адресация.
Хеш-адресация - это метод преобразования имени в индекс элемента в таблице. Если таблица состоит из N элементов, то им присваиваются номера 0,1,..,N-1. Тогда назовем хеш-функцией некоторое преобразование имени в адрес. Простейший вариант хеш-функции – это использование внутреннего представления первой литеры имени.
Пока для двух различных символов результаты хеширования различны, время поиска совпадает с временем, затраченным на хеширование. Однако, все проблемы начинаются тогда, когда результаты хеширования совпадают для двух и более различных имен. Эта ситуация называется коллизией.
|
|
Хорошая хеш-функция распределяет адреса равномерно, так что коллизии возникают не слишком часто. Но прежде, чем говорить о реализации хеш-функций, обратимся к вопросу о том, каким образом разрешаются коллизии.
СПОСОБЫ РЕШЕНИЯ ЗАДАЧИ КОЛЛИЗИИ. РЕХЕШИРОВАНИЕ
Пусть хешируется имя S и при этом обнаруживается коллизия. Обозначим через h значение хеш-функции. Тогда сравниваем S с элементом по адресу (h+p1)mod N, где N - длина таблицы (максимальное число элементов в таблице). Если опять возникает коллизия, то выбираем для сравнения элемент с адресом (h+p2)mod N и т.д. Это будет продолжаться до тех пор, пока не встретится элемент (h+pi)mod N, который либо пуст, либо содержит S, либо снова является элементом h (pi=0, и тогда считается, что таблица полна).
Способы рехеширования заключаются в выборе чисел p1,p2,..,pn. Рассмотрим наиболее распространенные из них.
Для начала введем параметр, называемый коэффициентом загрузки таблицы lf:
lf = n/N, где
n - текущее количество элементов в таблице, N - максимально возможное число элементов.
Линейное рехеширование
pi = i (т.е. p1=1, p2=2,..,pn=n).
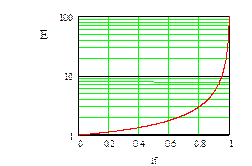
Среднее число сравнений E при коэффициенте загрузки lf определяется как
E(lf) = (1-lf/2)/(1-lf).
Это – очень неплохой показатель. В частности, при 10-ти процентной загрузке имеем E, равное 1.06, при 50-ти процентном заполнении E равно всего 1.5, а при 90 процентах загрузки требуется сделать в среднем всего 5.5 сравнений.
Ниже приведен график этой функции:
Случайное рехеширование
Пусть максимальное число элементов в таблице кратно степени двойки, т.е. N=2k. Вычисление pi осуществляется по следующему алгоритму:
R:= 1
Вычисляем pi:
R:= R*5
выделяем младшие k+2 разрядов R и помещаем их в R
pi:= R>>1 (сдвигаем R вправо на 1 разряд)
Перейти к П.2
Среднее число сравнений E при коэффициенте загрузки lf
E = -(1/lf)log2(1-lf)
Рехеширование сложением
pi = i(h+1), где h - исходный хеш-индекс.
Этот метод хорош для N, являющихся простыми числами.
|
|
ХЕШ-ФУНКЦИИ
Как уже говорилось, хеш-адресация – это преобразование имени в индекс. Имя представляет множество литер (символов), и для вычисления индекса поступают обычно следующим способом:
- Берется S', являющееся результатом суммирования литер из исходного символа S (либо простое суммирование, либо поразрядное исключающее ИЛИ):
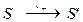
- Вычисляется окончательный индекс. При этом возможны самые различные варианты. В частности:
Умножить S' на себя и использовать n средних битов в качестве значения h (для N=2n);
Использовать какую-либо логическую операцию (например, исключающее ИЛИ) над некоторыми частями S';
Если N=2n, то разбить S' на n частей и просуммировать их. Использовать n крайних правых битов результата;
Разделить S' на длину таблицы, и остаток использовать в качестве хеш-индекса.
Итак, хорошая хеш-функция – это та, которая дает как можно более равномерное и случайное распределение индексов по именам, т.е. для "похожих" или "близких" имен хеш-функция должна выдавать сильно разнящиеся индексы, т.е. не допускает группировки имен в таблице символов.
Приведем пример фрагмента программы, реализующей хеш-адресацию:
struct name //элемент таблицы символов
{ char *string; //имя
name *next; //ссылка на следующий элемент
double value; //значение
};
const TBLSIZE = 23; // Количество "ящиков", по которым раскладываем символы
name *table[TBLSIZE];
name *findname(char *str, int ins)
// Функция поиска в таблице имени name
// Если ins!=0, то происходит добавление элемента в таблицу
{ int hi = 0; //Это, фактически, наш хеш-индекс
char *pp = str;
// Суммируем по исключающему ИЛИ каждый символ строки.
// Далее сдвигаем для того, чтобы индекс был лучше
// (исключаем использование только одного байта)
while (*pp)
{ hi<<=1;
hi^= *pp++;
}
if (hi<0) hi = -hi;
//Берем остаток
hi %= TBLSIZE;
//Поиск. Мы нашли список, теперь используем
// метод линейного рехеширования
for(name *n=table[hi];n;n=n->next)
if(strcmp(str,n->string)==0) return n; //Нашли. Возвращаем адрес
//Ничего не нашли
if(ins==0) return NULL; // error("Имя не найдено")
//Добавляем имя
name *nn = new name;
nn->string = new char[strlen(str)+1];
strcpy(nn->string, str);
nn->value = 0;
nn->next = table[hi];
table[hi] = nn;
return nn;
}
В данном примере таблица символов представляет собой не линейный список, а множество списков, адреса начала которых содержатся в некотором массиве. (Представьте себе аналогию с множеством ящиков, в которых и осуществляется поиск. Тогда хеш-индекс будет представлять собой номер некоторого ящика.)
|
|
Условно механизм работы с подобной организацией таблицы символов можно изобразить так:

|
|
|

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

Своеобразие русской архитектуры: Основной материал – дерево – быстрота постройки, но недолговечность и необходимость деления...

Историки об Елизавете Петровне: Елизавета попала между двумя встречными культурными течениями, воспитывалась среди новых европейских веяний и преданий...

Археология об основании Рима: Новые раскопки проясняют и такой острый дискуссионный вопрос, как дата самого возникновения Рима...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!