

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
Топ:
Оценка эффективности инструментов коммуникационной политики: Внешние коммуникации - обмен информацией между организацией и её внешней средой...
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Комплексной системы оценки состояния охраны труда на производственном объекте (КСОТ-П): Цели и задачи Комплексной системы оценки состояния охраны труда и определению факторов рисков по охране труда...
Интересное:
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Берегоукрепление оползневых склонов: На прибрежных склонах основной причиной развития оползневых процессов является подмыв водами рек естественных склонов...
Средства для ингаляционного наркоза: Наркоз наступает в результате вдыхания (ингаляции) средств, которое осуществляют или с помощью маски...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
В.Э. Карпов
КЛАССИЧЕСКАЯ ТЕОРИЯ КОМПИЛЯТОРОВ
Утверждено Редакционно-издательским советом института
в качестве Учебного пособия
Москва 2003
УДК 681.3.06
ББК 32.973
К26
Рецензенты: докт. техн. наук И.П.Беляев (НИИ
информационных технологий);
канд. техн. наук А.Н.Таран (НИИ
информационных систем)
Карпов В.Э.
К26 Теория компиляторов. Учебное пособие — Московский государственный институт электроники и математики. М., 2003. – с
ISBN
Рассматриваются основы теории формальных языков. Приводятся методы и алгоритмы построения основных частей трансляторов и интерпретаторов.
Для студентов, изучающих курс "Системное программное обеспечение по специальности "Управление и информатика в технических системах".
УДК 681.3.06
ББК 32.973
ISBN Ó Карпов В.Э., 2003
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ. 4
ТЕРМИНОЛОГИЯ.. 5
ПРОЦЕСС КОМПИЛЯЦИИ.. 6
ЛОГИЧЕСКАЯ СТРУКТУРА КОМПИЛЯТОРА.. 6
ОСНОВНЫЕ ЧАСТИ КОМПИЛЯТОРА.. 8
Лексический анализ (сканер) 9
Работа с таблицами. 11
Синтаксический и семантический анализ. 11
ТЕОРИЯ ФОРМАЛЬНЫХ ЯЗЫКОВ. ГРАММАТИКИ.. 14
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ. 14
ИЕРАРХИЯ ХОМСКОГО.. 16
РЕГУЛЯРНЫЕ ГРАММАТИКИ.. 18
КОНЕЧНЫЕ АВТОМАТЫ.. 19
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ. 19
ДЕТЕРМИНИРОВАННЫЕ И НЕДЕТЕРМИНИРОВАННЫЕ КОНЕЧНЫЕ АВТОМАТЫ.. 20
ПОСТРОЕНИЕ ДКА ПО НКА.. 25
ПРОГРАММИРОВАНИЕ СКАНЕРА.. 27
|
|
ОРГАНИЗАЦИЯ ТАБЛИЦ СИМВОЛОВ. ХЕШ-ФУНКЦИИ.. 29
ХЕШ-АДРЕСАЦИЯ.. 29
СПОСОБЫ РЕШЕНИЯ ЗАДАЧИ КОЛЛИЗИИ. РЕХЕШИРОВАНИЕ. 30
ХЕШ-ФУНКЦИИ.. 31
КОНТЕКСТНО-СВОБОДНЫЕ ГРАММАТИКИ.. 33
ОК-ГРАММАТИКИ.. 36
СИНТАКСИЧЕСКИ УПРАВЛЯЕМЫЙ ПЕРЕВОД.. 37
АВТОМАТЫ С МАГАЗИННОЙ ПАМЯТЬЮ... 41
ОПЕРАТОРНЫЕ ГРАММАТИКИ (ГРАММАТИКИ ПРОСТОГО ПРЕДШЕСТВИЯ) 44
МАТРИЦЫ ПЕРЕХОДОВ.. 47
ВНУТРЕННИЕ ФОРМЫ ПРЕДСТАВЛЕНИЯ ПРОГРАММЫ.. 52
ПОЛЬСКАЯ ФОРМА.. 52
ТЕТРАДЫ.. 57
ОПТИМИЗАЦИЯ ПРОГРАММ.. 58
ИНТЕРПРЕТАТОРЫ.. 61
КОМПИЛЯТОРЫ КОМПИЛЯТОРОВ.. 65
ПРИЛОЖЕНИЕ. ВВЕДЕНИЕ В ПРОЛОГ. 67
БИБЛИОГРАФИЧЕСКИЙ СПИСОК.. 78
ВВЕДЕНИЕ
В настоящем пособии излагаются основы классической теории компиляторов – одной из важнейших составных частей системного программного обеспечения.
Несмотря на более чем полувековую историю вычислительной техники, формально годом рождения теории компиляторов можно считать 1957, когда появился первый компилятор языка Фортран, созданный Бэкусом и дающий достаточно эффективный объектный код. До этого времени создание компиляторов было весьма "творческим" процессом. Лишь появление теории формальных языков и строгих математических моделей позволило перейти от "творчества" к "науке". Именно благодаря этому стало возможным появление сотен новых языков программирования. Более того, формальная теория компиляторов дала новый стимул развитию математической лингвистики и методам искусственного интеллекта, связанных с естественными и искусственными языками.
Основу теории компиляторов составляет теория формальных языков – весьма сложный, насыщенный терминами, определениями, математическими моделями и прочими формализмами раздел математики. Именно "языковой" стороне теории компиляторов прежде всего уделяется внимание в этом пособии. Разумеется, и формирование объектного кода, и машинно-зависимая оптимизация, и компоновка, безусловно, важны. Однако все это – частности, зависящие прежде всего от конкретной архитектуры вычислительной машины, от конкретной операционной системы. Наша же задача – научиться основам построения компиляторов. Архитектура меняется год от года, основы же остаются неизменными (на то они и основы) уже не один десяток лет.
|
|
Конечно, построить компилятор или интерпретатор можно и без всякой теории. Возможно, он даже будет работать. Но все дело в том, что, во-первых, этот титанический труд будет малоэффективен, а во-вторых, в лучшем случае мы получим "одноразовый" продукт, не пригодный для дальнейшего развития.
В пособии помимо теоретических сведений приводится ряд конкретных приемов, методов и алгоритмов. Фактически здесь содержится все то, что необходимо знать для построения одной из составляющей части компилятора – интерпретатора. Кроме того, в пособии приведен ряд примеров программ на языке Пролог. Знание Пролога является весьма желательным – уж больно просто и элегантно реализуются на нем важнейшие части компилятора. Несмотря на свой почтенный возраст, Пролог является достаточно экзотическим языком программирования, считаясь прежде всего языком искусственного интеллекта. Для создателя же компилятора Пролог – это очень удобный инструмент. В Приложении приведены некоторые сведения об этом языке, достаточные, по крайней мере, для того, чтобы понять суть приводимых примеров.
Но главное при изучении этого курса – постараться понять "анатомию" составных частей компилятора, представить себе, как можно самому реализовать тот или иной механизм. В этом смысле курс является весьма "практическим". Впрочем, и сама теория компиляторов не есть нечто искусственное, надуманное. Сначала была практика. Теория создавалась как раз для того, чтобы помочь разработчику в его практической деятельности, поэтому в любом, самом "заумном" определении, понятии и т.п. следует искать рациональное зерно.
ТЕРМИНОЛОГИЯ
Начнем с того, что дадим классические определения терминам, которые будут использоваться нами далее.
Транслятор - это программа, которая переводит текст исходной программы в эквивалентную объектную программу. Если объектный язык представляет собой автокод или некоторый машинный язык, то транслятор называется компилятором.
Автокод очень близок к машинному языку; большинство команд автокода - точное символическое представление команд машины.
|
|
Ассемблер - это программа, которая переводит исходную программу, написанную на автокоде или на языке ассемблера (что, суть, одно и то же), в объектный (исполняемый) код.
Интерпретатор принимает исходную программу как входную информацию и выполняет ее. Интерпретатор не порождает объектный код. Обычно интерпретатор сначала анализирует исходную программу (как компилятор) и транслирует ее в некоторое внутреннее представление. Далее интерпретируется (выполняется) это внутреннее представление.
Условно это можно изобразить следующим образом:
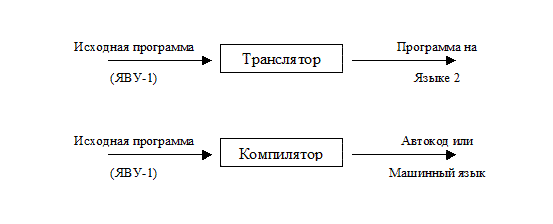
Компиляторы пишутся как на автокоде, так и на языках высокого уровня. Кроме того, существуют и специальные языки конструирования компиляторов - компиляторы компиляторов.
Компилятор компиляторов (КК) – система, позволяющая генерировать компиляторы; на входе системы - множество грамматик, а на выходе, в идеальном случае, - программа. Иногда под КК понимают язык программирования, в котором исходная программа - это описание компилятора некоторого языка, а объектная программа - сам компилятор для этого языка. Исходная программа КК - это просто формализм, служащий для описания компиляторов, содержащий, явно или неявно, описание лексического и синтаксического анализаторов, генератора кодов и других частей создаваемого компилятора. Обычно в КК используется реализация схемы т.н. синтаксически управляемого перевода. Кроме того, некоторые из них представляют собой специальные языки высокого уровня, на которых удобно описывать алгоритмы, используемые при создании компиляторов.
ПРОЦЕСС КОМПИЛЯЦИИ
ОСНОВНЫЕ ЧАСТИ КОМПИЛЯТОРА
Итак, можно выделить следующие этапы компиляции:
Лексический анализ. Замена лексем их внутренним представлением (например, замена операторов, разделителей и идентификаторов числами).
Синтаксический анализ. Иногда на этом этапе также вводятся дополнительные разделители и заменяются существующие для облегчения обработки.
Генерация промежуточного кода (трансляция). На этом этапе осуществляется контроль типа и вида всех идентификаторов и других операндов. При этом обычно преобразование исходной программы в промежуточную (например, польскую) форму записи осуществляется одновременно с синтаксическим анализом.
|
|
Оптимизация кода.
Распределение памяти для переменных в готовой программе.
Генерация объектного кода и компоновка программных сегментов.
На всех этих этапах происходит работа с различного рода таблицами. В частности, для каждого блока (если таковые существуют в языке) идентификаторы, описанные внутри, запоминаются вместе со своими атрибутами. Условно все эти этапы можно изобразить следующим образом:
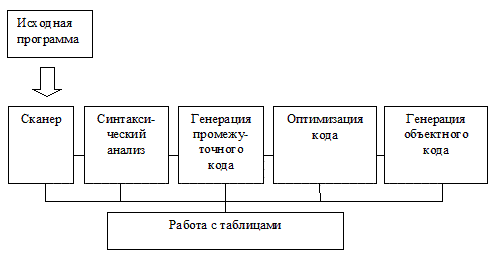
Очевидна зависимость структуры компилятора от структуры ЭВМ, точнее, от имеющейся производительности системы. Например, при малой памяти увеличивается количество проходов компиляции(т.н. многопроходные компиляторы), а при наличии памяти большого объема можно все этапы компиляции произвести за один проход(и тогда мы имеем дело с однопроходным компилятором). Тем не менее, независимо от вычислительных ресурсов, всю вышеперечисленную работу приходится так или иначе делать.
Далее мы рассмотрим вкратце некоторые из этих составных частей процесса компиляции.
Лексический анализ (сканер)
На входе сканера - цепочка символов некоторого алфавита (именно так выглядит для сканера наша исходная программа). При этом некоторые комбинации символов рассматриваются сканером как единые объекты. Например:
- один или более пробелов заменяются одним пробелом;
- ключевые слова (вроде BEGIN, END, INTEGER и др.);
- цепочка символов, представляющая константу;
- цепочка символов, представляющая идентификатор (имя);
Таким образом, лексический анализатор (ЛА) группирует определенные терминальные символы (т.е. входные символы) в единые синтаксические объекты - лексемы. В простейшем случае лексема - это пара вида <тип_лексемы, значение>.
Задача выделения лексем из входного потока зачастую оказывается весьма нетривиальной и зависящей от структуры конкретного языка. Как будет интерпретироваться такая входная последовательность "567АВ"? Это может быть одна лексема (идентификатор), а может – и пара лексем – константа "567" и имя "АВ". Во втором случае либо между лексемами необходимо указание разделителя (например, пробела), либо надо заранее знать, что будет следовать дальше.
Существует два основных типа лексических анализаторов - прямые (ПЛА) и непрямые (НЛА).
Прямой ЛА определяет лексему, расположенную непосредственно справа от текущего указателя, и сдвигает указатель вправо от части текста, образующей лексему (ПЛА определяет тип лексемы, которая образована символами справа от указателя).
Непрямой ЛА определяет, образуют ли знаки, расположенные непосредственно справа от указателя, лексему этого типа. Если да, то указатель передвигается вправо от части текста, образующей лексему. Иными словами, для него заранее задается тип лексемы, и он распознает символы справа от указателя и проверяет, удовлетворяют ли они заданному типу.
|
|
У ПЛА более сложная структура - он должен выполнять больше операций, нежели НЛА. Тем не менее в большинстве современных языков программирования используется синтаксис прямых лексических анализаторов (это может быть видно по внешнему виду фраз языка).
Фортран – это классический пример языка, использующего непрямой лексический анализатор. Все дело в том, что в этом языке игнорируются пробелы. Рассмотрим, например, конструкцию
DO5I=1,10 …
Для разбора этого предложения необходим непрямой лексический анализатор, который и определит, что означает цепочка "DO5I" – идентификатор "DO5I", или же ключевое слово "DO", за которым следует метка 5, а далее – имя переменной "I". Впрочем, аналогичные неприятности ожидают и разработчиков компиляторов языков типа C или C++, в которых существуют строковые комментарии "/*…*/" и "//…". При проведении лексического анализа, встретив символ "/", изначально неясно, является ли он оператором или началом строкового комментария. И вообще, многосимвольные лексемы – штука малоприятная для анализа.
Итак, на выходе сканера - внутреннее представление имен, разделителей и т.п. Например:
Вход сканера: AVR:= B + CDE; // Комментарии
Выход сканера: 38, -8, 65, -2, 184
(Если мы условимся обозначать оператор присваивания ":=" числом с кодом –8, операцию сложения – числом –2, а имена переменных числами 38, 65 и 184).
Кроме того, сканер занимается формированием различного рода таблиц. И прежде всего – таблицы имен, в которую он будет заносить распознанные имена – идентификаторы, константы, метки и т.п.
Работа с таблицами
Таблица имен представляет собой структуру, подобную следующей:
| Номер элемента | Идентификатор | Дополнительная информация (тип, размер и т.п.) |
| 1 | A | идент., тип = "строка" |
| … | … | … |
| N | 3.1415 | константа, число |
Механизм работы с таблицами должен обеспечивать:
(1) быстрое добавление новых идентификаторов и сведений о них;
(2) быстрый поиск информации.
К работе с таблицами мы еще вернемся, когда будем рассматривать хеш-функции.
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ
Общение на каком-либо языке – искусственном или естественном- заключается в обмене предложениями или, точнее, фразами. Фраза - это конечная последовательность слов языка. Фразы необходимо уметь строить и распознавать.
Если существует механизм построения фраз и механизм признания их корректности и понимания (механизм распознавания), то мы говорим о существовании некоторой теории рассматриваемого языка.
Определение: Язык L - это множество цепочек конечной длины в алфавите S.
Возникает вопрос – каким образом можно задать язык? Во-первых, язык можно задать полным его перечислением. С точки зрения математики это вовсе не является полной бессмысленностью. А во-вторых, можно иметь некоторое конечное описание языка.
Одним из наиболее эффективных способов описания языка является грамматика. Строго говоря, грамматика - это математическая система, определяющая язык. Как мы убедимся далее, грамматика пригодна не только для задания (или генерации) языка, но и для его распознавания.
Далее нам потребуются некоторые термины и обозначения. Начнем с определения замыкания множества.
Если å - множество (алфавит или словарь), то å* - замыкание множества å, или, иначе, свободный моноид, порожденный å, т.е. множество всех конечных последовательностей, составленных из элементов множества å, включая и пустую последовательность.
Например, пусть A = {a, b, c}. Тогда A*={e, a, b, c, aa, ab, ac, bb, bc, cc, …}. Здесь e – это пустая последовательность.
Символом å+ мы будем обозначать положительное замыкание множества å (или, иначе, свободную полугруппу, порожденную множеством å). В отличие от свободного моноида в положительное замыкание не входит пустая последовательность.
Теперь все готово к тому, чтобы дать основное определение.
Определение. Грамматика - это четверка G = (N, S,P,S), где
N - конечное множество нетерминальных символов (синтаксические переменные или синтаксические категории);
S - конечное множество терминальных символов (слов) (SÇN=Æ);
P - конечное подмножество множества
(NÈS)*N(NÈS)* ´ (NÈS)*
Элемент (a,b) множества P называется правилом или продукцией и записывается в виде a®b;
S - выделенный символ из N (SÎN), называемый начальным символом (эта особая переменная называется также "начальной переменной" или "исходным символом").
Пример:
G = ({A,S},{0,1},P,S),
P = (S®0A1, 0A®00A1, A®e)
Определение. Язык, порождаемый грамматикой G (обозначим его через L(G)) - это множество терминальных цепочек, порожденных грамматикой G.
Или, иначе, язык L, порождаемый (распознаваемый) грамматикой, есть множество последовательностей (слов), которые
(3) состоят лишь из терминальных символов;
(4) можно породить, начиная с символа S.
И опять нам требуются определения и обозначения:
Определение: Пусть G = (N, S, P, S). Отношение ÞG на множестве (NÈS)* называется непосредственной выводимостью jÞGy (y непосредственно выводима из j), если abg - цепочка из (NÈS)* и b®d - правило из P, то abgÞGadg.
Транзитивное замыкание отношения ÞG обозначим через Þ+G.
Запись jÞ+G y означает: y выводима из j нетривиальным образом.
Рефлексивное и транзитивное замыкание отношения ÞG обозначим через Þ*G. Запись jÞ*G y означает: y выводима из j. (Если Þ* - это рефлексивное и транзитивное замыкание отношения Þ, то последовательность a1Þa2, a2Þa3,.., am-1Þam, где aiÎ(NÈS)*, записывается так: a1Þ*am.)
При этом предполагалось наличие следующих определений:
Определение A. k-я степень отношения R на множестве A (Rk):
(1) aR1b тогда и только тогда, когда aRb (или R1ºR);
(2) aRib для i>1 тогда и только тогда, когда $ cÎA: aRc и cRi-1b.
Определение B. Транзитивное замыкание отношения R на множестве A (R+):
aR+b тогда и только тогда, когда aRib для некоторого i>0.
Определение C. Рефлексивное и транзитивное замыкание отношения R на множестве A (R*):
(1) aR*a для " aÎA;
(2) aR*b, если aR+b
Таким образом, получаем формальное определение языка L:
L(G)={ w | w Î å *, S Þ * w }
Нормальная форма Бэкуса-Наура. Нормальная форма Бэкуса-Наура (НФБ или БНФ) служит для описания правил грамматики. Она была впервые применена Науром при описании синтаксиса языка Фортран. По сути БНФ является альтернативной, более упрощенной, менее строгой и потому более распространенной формой записи грамматики. Далее мы будем пользоваться ею наравне с формальными определениями в силу ее большей наглядности.
Пример:
<число>::= <чс>
<чс>::= <чс><цифра>|<цифра>
<цифра>::= 0|1|...|9
ИЕРАРХИЯ ХОМСКОГО
Вернемся к определению грамматики как четверки вида G = (N, å, P, S), где нас интересует вид правил P, под которыми понимается конечное подмножество множества
(NÈS)*N(NÈS)* ´ (NÈS)*
В зависимости от конкретики реализаций правил P существует следующая классификация грамматик (в порядке убывания общности вида правил):
Грамматика типа 0: Правила этой грамматики определяются в самом общем виде.
P: xUy®z
Для распознавания языков, порожденных этими грамматиками, используются т.н. машины Тьюринга – очень мощные (на практике практически неприменимые) математические модели.
Грамматика типа 1: Контекстно-зависимые (чувствительные к контексту)
P: xUy®xuy
Грамматика типа 2: Контекстно-свободные. Распознаются стековыми автоматами (автоматами с магазинной памятью)
P: U®u
Грамматика типа 3: Регулярные грамматики. Распознаются конечными автоматами
P: U®a или U®aA
При этом приняты следующие обозначения:
u Î (NÈS)+
x, y, z Î (NÈS)*
A,U Î N
a Î S
Условно иерархию Хомского можно изобразить так:
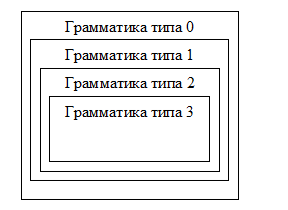
Итак, иерархия Хомского необходима для классификации грамматик по степени их общности. При этом, как видно,
Грамматика типа 0 - самая сложная, никаких ограничений на вид правил в ней не накладывается.
Грамматика типа 1 – контекстно-зависимая; в ней возможность замены цепочки символов может определяться ее (т.е. цепочки) контекстом.
Грамматика типа 2 – контекстно-свободная; в левой части нетерминалы меняются на что угодно.
Грамматика типа 3 - регулярная грамматика, самая ограниченная, самая простая.
РЕГУЛЯРНЫЕ ГРАММАТИКИ
Начнем изучение грамматик с самого простого и самого ограниченного их типа – регулярных грамматик. Вот некоторые примеры:
Идентификатор (в форме БНФ)
<идент>::= <бкв>
<идент>::= <идент><бкв>
<идент>::= <идент><цфр>
<бкв>::= a|b|...|z
<цфр>::= 0|1|...|9
Арифметическое выражение (без скобок)
G = (N, å,P,S)
N={S,E,op,i}
å={<число>, <идент>,+,-,*,/}
P={S®i
S®iE
E®op S
op®+
op®-
op®*
op®/
i®<число>
i®<идент>}
Ту же грамматику бесскобочных выражений можно изобразить в виде БНФ (это не совсем строго, зато весьма наглядно):
<expr>::= <число>|<идент>
<expr>::= <expr><op><expr>
<op>::= +|-|*|/
<число>::= <цфр>
<число>::= <число><цфр>
Еще один пример:
Z::= U0 | V1
U::= Z1 | 1
V::= Z0 | 0
Порождаемый этой грамматикой язык состоит из последовательностей, образуемых парами 01 или 10, т.е. L(G) = { Bn | n > 0}, где B = { 01, 10}.
Стоит, однако, рассмотреть чуть более сложный объект (например, арифметические выражения со скобками), как регулярные грамматики оказываются слишком ограниченными:
Арифметическое выражение (со скобками)
G0=({E,T,F},{a,+,*,(,),#},P,E)
P = { E ® E+T|T
T ® T*F|F
F ® (E)|a}
Это, разумеется, уже не регулярная, а контекстно-свободная грамматика.
Тем не менее регулярные грамматики играют очень важную роль в теории компиляторов. По крайней мере их достаточно для того, чтобы реализовать первую часть компилятора – сканер. Ведь сканер имеет дело именно с такими простыми объектами, как идентификаторы и константы.
Итак, будем считать, что мы как минимум умеем порождать фразы регулярных языков. Однако все-таки нашей основной задачей является не порождение, а распознавание фраз. Поэтому далее рассмотрим один из наиболее эффективных распознающих механизмов – конечный автомат.
КОНЕЧНЫЕ АВТОМАТЫ
ФОРМАЛЬНОЕ ОПРЕДЕЛЕНИЕ
Как уже говорилось выше, грамматика - это порождающая система. Автомат - это формальная воспринимающая система (или акцептор). Правила автомата определяют принадлежность входной формы данному языку, т.е. автомат – это система, которая распознает принадлежность фразы к тому или иному языку.
Говорят, что автомат эквивалентен данной грамматике, если он воспринимает весь порождаемый ею язык и только этот язык. Как и грамматики, автоматы определяются конечными алфавитами и правилами переписывания.
Определение. Конечный автомат (КА) - это пятерка КА = (å,Q,q0,T,P), где
å - входной алфавит (конечное множество, называемое также входным словарем);
Q - конечное множество состояний;
q0 - начальное состояние (q0ÎQ);
T - множество терминальных (заключительных) состояний, TÌQ;
P – подмножество отображения вида Q´å®Q, называемое функцией переходов. Элементы этого отображения называются правилами и обозначаются как
qiak®qj, где qi и qj - состояния, ak - входной символ: qi, qj Î Q, akÎå.
КА можно рассматривать как машину, которая в каждый момент времени находится в некотором состоянии qÎQ и читает поэлементно последовательность w символов из å, записанную на конечной слева ленте. При этом читающая головка машины двигается в одном направлении (слева направо), либо лента перемещается (справа налево). Если автомат в состоянии qi читает символ ak и правило qiak®qj принадлежит P, то автомат воспринимает этот символ и переходит в состояние qj для обработки следующего символа:

Таким образом, суть работы автомата сводится к тому, чтобы прочитать очередной входной символ и, используя соответствующее правило перехода, перейти в другое состояние.
Связь между конечными автоматами и регулярными грамматиками самая непосредственная, что следует из утверждения:
Каждой грамматике можно поставить в соответствие эквивалентный ей автомат, и каждому автомату соответствует эквивалентная ему грамматика.
Итак, мы установили взаимосвязи между грамматиками, языками и автоматами:
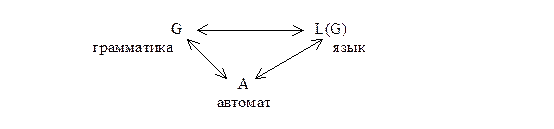
ПОСТРОЕНИЕ ДКА ПО НКА
Обычно при описании тех или иных объектов наличие дополнительных ограничений снижает общность. Однако большая общность НКА по сравнению с ДКА является кажущейся. Дело в том, что справедливо следующее утверждение:
Для любого НКА можно построить эквивалентный ему конечный детерминированный автомат.
Для построения детерминированного автомата можно воспользоваться следующей теоремой:
Теорема. Пусть НКА F= (å,Q,q0,T,P) допускает множество цепочек L. Определим ДКА F'= (å',Q',q0',T',P') следующим образом:
Множество состояний Q' состоит из всех подмножеств множества Q. Обозначим элемент множества Q' через [S1,S2,..,Sl], где S1,S2,..,SlÎQ.
å' = å.
Отображение P' определяется как
P'([S1,S2,..,Sm],x) = [R1,R2,..,Rm],
где P({S1,S2,..,Sm },x) = { R1,R2,..,Rm }, Si,RiÎQ, xÎå.
Пусть q0={S1,S2,..,Sk}.
Тогда q0'=[S1,S2,..,Sk].
Пусть множество заключительных состояний T={Sj, Sk,.., Sn}.
Тогда T'=[Sj, Sk,.., Sn].
Или, иначе,
T'={t=[Sa,Sb,..,Sc] | $ Sb: SbÎT}.
Построенный таким образом детерминированный конечный автомат будет эквивалентен в смысле "вход-выход" исходному НКА.
Приведем пример построения ДКА по НКА. Пусть дан недетерминированный автомат
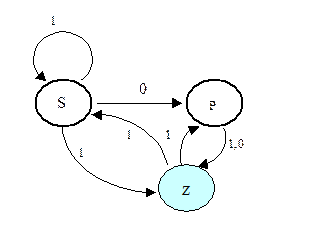
Правила переходов: {S1®S, S1®Z, S0®P, P1®Z, P0®Z, Z1®P, Z1®S}.
Начальные состояния: {S, P}.
Заключительные состояния: {Z}.
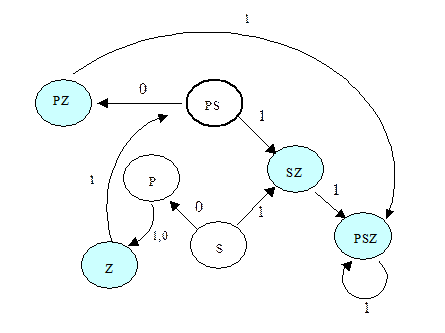
Множество состояний ДКА будет таким: {S, P, Z, PS, SZ, PSZ, PZ}. Их будет ровно 2n-1, где n – количество состояний исходного автомата.
Его правила переходов:
{S1®SZ, S0®P, P1®Z, P0®Z, Z1®PS, PS1®SZ, PS0®PZ, SZ1®PSZ, PSZ1®PSZ, PZ1®PSZ}.
Начальное состояние: SP.
Заключительные состояния: {Z, PZ, SZ, PSZ}.
Тогда детерминированный автомат будет выглядеть так:
После упрощения автомата, т.е. удаления вершин, не достижимых из начальной, получим такой автомат:
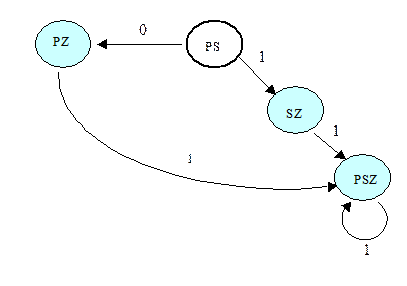
Завершая рассуждения о недетерминированных автоматах, следует отметить еще один момент, связанный с множеством начальных состояний (н.с.) в НКА. Дело в том, что когда имеется несколько н.с., работа автомата заключается в том, что переход по входному символу осуществляется одновременно из всех начальных состояний. Именно в этом заключается суть процедуры объединения всех н.с. в одно. Это особенно важно при моделировании НКА, скажем, средствами Пролога.
ПРОГРАММИРОВАНИЕ СКАНЕРА
Итак, теперь все готово к тому, чтобы приступить к построению сканера. Напомним, что нам необходимо построить лексический анализатор для выделения из входного потока исходных составляющих языка – лексем или символов. Символами являются:
(7) разделители или операторы (+,-,*,/,(,) и т.п.);
(8) служебные слова (что-то вроде begin, end,... и т.п.);
(9) идентификаторы;
(10) числа.
Кроме того, необходимо исключать комментарии (как строчные, типа '//', так и многострочные, вида '/*...*/').
Строить сканер мы будем, используя конечный автомат. К автомату предъявляются следующие минимальные требования:
Автомат должен формировать поток лексем;
Автомат должен заносить полученные лексемы в таблицу символов или имен.
Наш распознающий автомат упрощенно может выглядеть следующим образом:
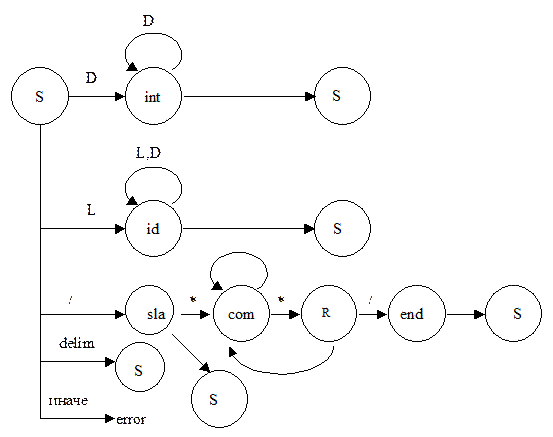
Здесь под символом D понимается цифра, L означает букву, а delim – разделитель (пробел, табуляцию и т.п.). Состояние int отвечает за распознавание числа, id – за распознавание имени, а sla, com, end и R – за распознавание комментариев. Чтобы не загромождать схему дугами, переходы в основное состояние S обозначены дублированием этой вершины.
При этом следует отметить, что
При переходе в начальное состояние S иногда требуется возвращать обратно считываемый символ входной последовательности, т.е. необходимо сместить указатель на одну позицию назад. Иначе мы просто будем терять часть лексем, т.к. автомат -–это устройство, последовательно считывающее очередной входной символ на каждом такте работы.
Автомат в таком виде бесполезен, он не выполняет никаких полезных процедур.
Следовательно, автомат необходимо дополнить процедурной частью. Именно процедурная часть отвечает за формирование имен, которые далее будут заноситься в таблицу символов, за возврат считанного символа обратно во входной поток, за инициализацию и т.д. Дополнение автомата этой процедурной частью автомата заключается в том, что когда автомат совершает очередной переход, должна выполняться связанная с этим переходом одна или несколько процедур (или подпрограмм). Это, разумеется, несколько усложняет структуру автомата, однако эту работу выполнять необходимо, т.к. мы занимаемся не только проверкой входной последовательности, но и ее преобразованием в поток лексем.
ХЕШ-АДРЕСАЦИЯ
Идеальный вариант – уметь по имени сразу определить адрес элемента. В этом смысле "хорошей" процедурой поиска является та, которая сможет определить хотя бы приблизительный адрес элемента. Одним из наиболее эффективных и распространенных методов реализации такой процедуры является хеш-адресация.
Хеш-адресация - это метод преобразования имени в индекс элемента в таблице. Если таблица состоит из N элементов, то им присваиваются номера 0,1,..,N-1. Тогда назовем хеш-функцией некоторое преобразование имени в адрес. Простейший вариант хеш-функции – это использование внутреннего представления первой литеры имени.
Пока для двух различных символов результаты хеширования различны, время поиска совпадает с временем, затраченным на хеширование. Однако, все проблемы начинаются тогда, когда результаты хеширования совпадают для двух и более различных имен. Эта ситуация называется коллизией.
Хорошая хеш-функция распределяет адреса равномерно, так что коллизии возникают не слишком часто. Но прежде, чем говорить о реализации хеш-функций, обратимся к вопросу о том, каким образом разрешаются коллизии.
ХЕШ-ФУНКЦИИ
Как уже говорилось, хеш-адресация – это преобразование имени в индекс. Имя представляет множество литер (символов), и для вычисления индекса поступают обычно следующим способом:
- Берется S', являющееся результатом суммирования литер из исходного символа S (либо простое суммирование, либо поразрядное исключающее ИЛИ):
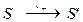
- Вычисляется окончательный индекс. При этом возможны самые различные варианты. В частности:
Умножить S' на себя и использовать n средних битов в качестве значения h (для N=2n);
Использовать какую-либо логическую операцию (например, исключающее ИЛИ) над некоторыми частями S';
Если N=2n, то разбить S' на n частей и просуммировать их. Использовать n крайних правых битов результата;
Разделить S' на длину таблицы, и остаток использовать в качестве хеш-индекса.
Итак, хорошая хеш-функция – это та, которая дает как можно более равномерное и случайное распределение индексов по именам, т.е. для "похожих" или "близких" имен хеш-функция должна выдавать сильно разнящиеся индексы, т.е. не допускает группировки имен в таблице символов.
Приведем пример фрагмента программы, реализующей хеш-адресацию:
struct name //элемент таблицы символов
{ char *string; //имя
name *next; //ссылка на следующий элемент
double value; //значение
};
const TBLSIZE = 23; // Количество "ящиков", по которым раскладываем символы
name *table[TBLSIZE];
name *findname(char *str, int ins)
// Функция поиска в таблице имени name
// Если ins!=0, то происходит добавление элемента в таблицу
{ int hi = 0; //Это, фактически, наш хеш-индекс
char *pp = str;
// Суммируем по исключающему ИЛИ каждый символ строки.
// Далее сдвигаем для того, чтобы индекс был лучше
// (исключаем использование только одного байта)
while (*pp)
{ hi<<=1;
hi^= *pp++;
}
if (hi<0) hi = -hi;
//Берем остаток
hi %= TBLSIZE;
//Поиск. Мы нашли список, теперь используем
// метод линейного рехеширования
for(name *n=table[hi];n;n=n->next)
if(strcmp(str,n->string)==0) return n; //Нашли. Возвращаем адрес
//Ничего не нашли
if(ins==0) return NULL; // error("Имя не найдено")
//Добавляем имя
name *nn = new name;
nn->string = new char[strlen(str)+1];
strcpy(nn->string, str);
nn->value = 0;
nn->next = table[hi];
table[hi] = nn;
return nn;
}
В данном примере таблица символов представляет собой не линейный список, а множество списков, адреса начала которых содержатся в некотором массиве. (Представьте себе аналогию с множеством ящиков, в которых и осуществляется поиск. Тогда хеш-индекс будет представлять собой номер некоторого ящика.)
Условно механизм работы с подобной организацией таблицы символов можно изобразить так:

ОК-ГРАММАТИКИ
Несмотря на кажущуюся общность КСГ, при описании естественно-подобных языков существуют ограничения, связанные с различного рода бесконтекстными согласованиями (рода, падежа, числа и т.п.).
Для решения проблемы подобных согласований можно ввести еще одну разновидность грамматик - грамматики определенных клауз. Их особенностью является наличие контекстуальных аргументов.
Рассмотрим, каким образом может осуществляться согласование родов. Допустим, у нас есть группа существительных (ГС), состоящая из местоимения (Мест), прилагательного (Прил) и существительного (Сущ). Тогда определение ГС, учитывающее согласование родов, может выглядеть так:
Гс ® Мест(k), Прил(k), Сущ(k), ГС
При этом k является контекстуальным аргументом, отвечающим за согласование родов. Этот аргумент является логической переменной:
Мест(муж) ® этот
Мест(жен) ® эта
Прил(муж) ® второй
Прил(жен) ® вторая
Сущ(жен) ® строка
Сущ(муж) ® пароль
и т.д.
На Прологе введение контекстуального аргумента выглядит так:
mest(“муж”,”этот”).
pril ("жен", "вторая").
и т.п.
Алгоритм разбора
Нам потребуются два стека: стек операторов OP и стек аргументов ARG. Обозначим через S верхний символ в стеке операторов OP, а через R - входной символ.
Далее циклически выполняем следующие действия:
Если R - идентификатор, то поместить его в ARG и пропустить шаги 2,3.
Если f(S)<g(R), то поместить R в OP и взять следующий символ.
Если f(S)³g(R), то вызвать семантическую процедуру, определяемую символом S. Эта процедура выполняет семантическую обработку, например, исключает из ARG связанные с S аргументы и заносит в ARG результат операции. Это – т.н. редукция сентенциальной формы.
Построим матрицу, строки которой будут соответствовать f(S), а столбцы – g(R). Для грамматики
E®E+T | T
T®T*F | F
F®(E) | i
эта матрица будет выгляд
|
|
|

История развития хранилищ для нефти: Первые склады нефти появились в XVII веке. Они представляли собой землянные ямы-амбара глубиной 4…5 м...

Биохимия спиртового брожения: Основу технологии получения пива составляет спиртовое брожение, - при котором сахар превращается...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!