

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Топ:
Процедура выполнения команд. Рабочий цикл процессора: Функционирование процессора в основном состоит из повторяющихся рабочих циклов, каждый из которых соответствует...
Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Генеалогическое древо Султанов Османской империи: Османские правители, вначале, будучи еще бейлербеями Анатолии, женились на дочерях византийских императоров...
Интересное:
Принципы управления денежными потоками: одним из методов контроля за состоянием денежной наличности является...
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Наиболее распространенные виды рака: Раковая опухоль — это самостоятельное новообразование, которое может возникнуть и от повышенного давления...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Арифметические выражения
Арифметические выражения состоят из операндов (чисел и переменных), операторов (+,-,/,*,div и mod) и скобок. Символы в правой части от знака равенства (который является предикатом =) составляют арифметическое выражение. Например:
А=1+6/(11+3)*Z
Шестнадцатеричные и восьмеричные числа начинаются с "0х" или "0о" соответственно. Например:
OxFFF=4095
86=0о112+12
Значение выражения может быть вычислено, только если все переменные в момент вычисления определены. При этом вычисления производятся в порядке, определяемом приоритетом операции. Операции с высшим приоритетом выполняются первыми.
Операции
Пролог может выполнять все четыре осноные арифметические операции (сложение, вычитание, умножение и деление) между целыми и вещественными числами. Тип результата приведен и таблице 1.
В случае смешанной целочисленной арифметики, включающей и знаковые и безнаковые числа, результат знаковый. Размер результата будет равен большему из размеров двух операндов.
Порядок вычислений
Арифметические операции вычисляются в следующем порядке:
· если выражение содержит подвыражение в скобках, подвыражение вычисляется первым;
· если выражение содержит операции умножения (*) или деления (/, div или mod), эти операции выполняются слева направо;
· если выражение содержит операции сложения (+) и вычитания (-), они выполняются также слева направо.
В выражении A=1+6/(11+3)*Z, предположим, что Z имеет значение 4, ибо переменные должны быть связаны до вычисления. Вычислим это выражение:
1. (11+3) - первое вычисляемое подвыражеие, т. к. оно заключено в скобки, оно вычисляется как 14.
2. Затем вычисляется 6/14, т. к. / и * вычисляются слева направо. В результате получим 0.428571.
|
|
3. Далее 0.428571*4 дает 1.714285.
4. Наконец, вычисляя 1+1.714285, получаем значение выражения 2.714285.
А получит значение 2.714285, которое принадлежит вещественному домену.
Следует поупражняться в управлении вещественными числами. В большинстве случаев они не представлены точно, и маленькие ошибки могут накапливаться, выдавая непредсказуемые результаты.
43. Целочисленная и вещественная арифметика.
Пролог поддерживает предикаты и функции модульной арифметики, целого деления, квадратные корни и абсолютные значения, тригонометрические и трансцендентные функции, округление (вверх или вниз) и усечение.
Функция mod/2
Функция mod вычисляет остаток от деления X на Y (где X и Y - целые).
Функция div/2
Функция div вычисляет целое частное от деления X ни Y (где X и Y - целые).
Функция abs/1
Функция abs возвращает абсолютное значение своего аргумента.
Функция cos/1
Функция cos возвращает значение косинуса своего аргумента.
Функция sin/1
Функция sin возвращает значение синуса своего аргумента.
Функция tan/1
Функция tan возвращает значение тангенса своего аргумента.
Функция arctan/1
Функция arctan возвращает арктангенса от вещественного значения, с которым связано X.
Функция ехр/1
Функция ехр возвращает значение е в степени значения, с которым связано X.
Функция ln/1
Функция ln возвращает значение натурального логарифма от X (по основанию е).
Функция log/1
Функция log возвращает значение логарифма по основанию 10 от X.
Функция sqrt/1
Функция sqrt возвращает квадратный корень от X.
Функция round/1
Функция round возвращает округленное значение X.
Функция trunc/1
Функция trunc усекает X справа до десятичной точки, отбрасывая дробную часть.
44. Поиск с возвратом.
Пролог при поиске решения задачи использует именно такой метод проб и возвращений назад; этот метод называется поиск с возвратом. Если, начиная поиск решения задачи (или целевого утверждения), Пролог должен выбрать между альтернативными путями, то он ставит маркер у места ветвления (называемого точкой отката) и выбирает первую подцель, которую и станет проверять. Если данная подцель не выполнится (что эквивалентно достижению тупика в лабиринте), Пролог вернется к точке отката и попробует проверить другую подцель.
|
|
Рассмотрим простой пример pro29_1.pro.
predicates
likes(symbol,symbol)
tastes(symbol,symboI)
food(symbol)
clauses
likes (bill,X):-
food(X),
tastes(X,good).
tastes(pizza,good).
tastes(brussels_sprouts,bad).
food(brussels_sprouts).
food(pizza).
Эта маленькая программа составлена из двух множеств фактов и одного правила. Правило, представленное отношением likes, утверждает, что Билл любит вкусную пищу.
Чтобы увидеть, как работает поиск с возвратом, дадим программе для решения следующее целевое утверждение:
likes(bill,What).
Замечание. Когда Пролог пытается произвести согласование целевого утверждения, он начинает поиск с вершины программы.
В данном случае Пролог будет искать решение, производя с вершины программы поиск соответствия с подцелью
likes (bill,What).
Он обнаруживает соответствие с первым предложением в программе и переменная what унифицируется с переменной X. Сопоставление с заголовком правила заставляет Пролог попытаться удовлетворить это правило. Производя это, он двигается по телу правила и обращается к первой находящейся здесь подцели: food(X).
45. Прерывание поиска с возвратом: отсечение.
Пролог предусматривает возможность отсечения, которая используется для прерывания поиска с возвратом; отсечение обозначается восклицательным знаком (!). Действует отсечение просто: через него невозможно совершить откат (поиск с возвратом).
Отсечение помещается в программу таким же образом, как и подцель в теле правила. Когда процесс проходит через отсечение, немедленно удовлетворяется обращение к cut и выполняется обращение к очередной подцели (если таковая имеется). Однажды пройдя через отсечение, уже невозможно произвести откат к подцелям, расположенным в обрабатываемом предложении перед отсечением, и также невозможно возвратиться к другим предложениям, определяющим обрабатывающий предикат (предикат, содержащий отсечение).
Существуют два основных случая применения отсечения.
· Если вы заранее знаете, что определенные посылки никогда не приведут к осмысленным решениям (поиск решений в этом случае будет лишней тратой времени), - примените отсечение, - программа станет быстрее и экономичнее. Такой прием называют зеленым отсечением.
|
|
· Если отсечения требует сама логика программы для исключения из рассмотрения альтернативных подцелей. Это - красное отсечение.
Использование отсечений
На этом шаге даются примеры, показывающие, как следует использовать отсечение, рассматриваются несколько условных правил (r1, r2 и r3), которые определяют условный предикат r, а также несколько подцелей - а, b, с и т. д.
Объявление списков
Чтобы объявить домен для списка целых, надо использовать декларацию домена, такую как:
domains integerlist=integer*Символ (*) означает "список чего-либо"; таким образом, integer* означает "список целых".
Обратите внимание, что у слова "список" нет специального значения в Прологе. С тем же успехом можно назвать список "занзибаром". Именно обозначение * (а не название), говорит компилятору, что это список.
Чтобы объявить список, составленный из целых, действительных и идентификаторов, надо определить один тип, включающий все три типа с функторами, которые покажут, к какому типу относится тот или иной элемент. Например:
elementlist=elements* % функторы здесь i,r и s elements=i(integer); r(real); s(symbol)Головы и хвосты
Список является рекурсивным составным объектом. Он состоит из двух частей - головы, которая является первым элементом, и хвоста, который является списком, включающим все последующие элементы. Хвост списка - всегда список, голова списка - всегда элемент. Например:
голова [а,b,с] есть а хвост [а,b,с] есть [b,с]Что происходит, когда вы доходите до одноэлементного списка? Ответ таков:
голова[с] есть с хвост [с] есть [ ]49. Работа со списками.
В Прологе есть способ явно отделить голову от хвоста. Вместо разделения элементов запятыми, это можно сделать вертикальной чертой "|". Например:
[а,b,с] эквивалентно [а| [b,с]]
и, продолжая процесс,
[а| [b,с]] эквивалентно [а | [b| [с]]], что эквивалентно [а| [b| [с| [] ]]]
Можно использовать оба вида разделителей в одном и том же списке при условии, что вертикальная черта есть последний разделитель. При желании можно набрать [а,b,с,d] как [a,b| [c,d]]. В таблице 1 вы найдете другие примеры.
|
|
| Таблица 1. Головы и хвосты списков | ||
| Список | Голова | Хвост |
| ['a','b','с'] | 'a' | ['b','с'] |
| ['a'] | 'a' | [] % пустой список |
| [ ] | Не определена | Не определен |
| [[1,2,3], [2,3,4],[ ]] | [1,2,3] | [[2,3,4],[ ]] |
В таблице 2 приведены несколько примеров на присвоение в списках.
| Таблица 2. Присвоение в списках | ||
| Список 1 | Список 2 | Присвоение переменным |
| [X,Y,Z] | [эгберт, ест,мороженое] | Х=эгберг, У=ест, Z=мороженое |
| [7] | [X | Y] | Х=7,Y=[ ] |
| [1,2,3,4] | [X, Y | Z] | X=1, Y = 2, Z = [3,4] |
| [1,2] | [3|X] | fail % неудача |
50. Использование списков.
Список является рекурсивной составной структурой данных, поэтому нужны алгоритмы для его обработки. Главный способ обработки списка - это просмотр и обработка каждого его элемента, пока не будет достигнут конец.
Алгоритму этого типа обычно нужны два предложения. Первое из них говорит, что делать с обычным списком (списком, который можно разделить на голову и хвост), второе - что делать с пустым списком.
Печать списков
Если нужно напечатать элементы списка, это делается так, как показано ниже.
domains
list = integer* % Или любой тип, какой вы хотите
predicates
write_a_list(list)
clauses
write_a_list([]). % Если список пустой - ничего не делать
write_a_list([H |T]):- % Присвоить Н-голова,Т-хвост, затем...
write(H),nl,
write_a_list(T).
goal
write_a_list([1,2,3]).
Вот два целевых утверждения write_a_list, описанные на обычном языке:
Печатать пустой список - значит ничего не делать.
Иначе, печатать список - означает печатать его голову (которая является одним элементом), затем печатать его хвост (список).
Подсчет элементов списка
Рассмотрим, как можно определить число элементов в списке. Что такое длина списка? Вот простое логическое определение:
Длина [ ] - 0.
Длина любого другого списка - 1 плюс длина его хвоста.
Можно ли применить это? В Прологе - да. Для этого нужны два предложения.
domains
list = integer* % или любой другой тип
predicates
length_of(list,integer)
clauses
length_of([],0).
length_of([_|T],L):-
length_of(T,TailLength),
L=TailLength + 1.
51. Основные предикаты управления строкой.
Предикаты, описываемые на этом шаге, являются основой обработки в Прологе; они служат для нескольких целей:
· разделение строки на подстроки и лексемы;
· построение строки из определенных подстрок и лексем;
· проверка, состоит ли строка из определенных подстрок или лексем;
· возврат лексемы или списка лексем из данной строки;
· проверка или определение длины строки;
· создание пустой строки определенной длины;
· проверка, является ли строка термином, определенным в Прологе;
· форматирование переменного числа аргументов в строковую переменную.
Предикат frontchar/3
Предикат frontchar действует согласно равенству:
|
|
String1 = объединение Char и String2
Предикат fronttoken/3
Предикат fronttoken выполняет три взаимосвязанные функции, в зависимости от типа аргументов, который используется для обращения к нему.
fronttoken(String1,Token,Rest) %(i, о, о) (i,i, о) (i,o,i) (i,i,i) (o,i,i)
Предикат frontstr/4
Предикат frontstr расщепляет String1 на две части. Синтаксис предиката:
frontstr(NumberOfChars,String1,StartStr,EndStr) % (i,i,o,o)
где StartStr содержит NumberOfChars первых символов из String1, a EndStr содержит остаток. При обращении к frontstr первые два параметра должны быть связанными, а последние два - свободными.
Предикат concat/3
Предикат concat устанавливает, что строка String3 является результатом сцепления String1 и String2. Он имеет форму:
concat(String1,Sring2,String3) % (i,i,o), (i,o,i), (o,i,i), (i,i,i)
Предикат isname/1
Предикат isname проверяет, является ли аргумент допустимым именем согласно синтаксису Пролога, и имеет формат:
isname(String) % (i)
Имя начинается с буквы алфавита или символа подчеркивания, за которым следует любое число букв, цифр и символов подчеркивания. Предыдущие и последующие пробелы игнорируются.
Предикат format/*
Предикат format выполняет преобразования, аналогичные writef, но format выдает результат в виде строковой переменной.
format(OutputString,FormatString,Arg1,Arg2,Arg3,..., ArgN) %(o,i,i,i,...,i)
52. Преобразования типов.
На этом шаге мы рассмотрим стандартные предикаты, предназначенные для преобразования типов. Это предикаты char_int, str_char, str_int, str_real, upper_lower.
Предикат char_int/2
Предикат char_int преобразует символ в целое число или целое в символ и имеет формат:
char_int(Char,Integer) % (i,o), (o,i), (i,i)
Предикат str_char/2
Предикат str_char преобразует строку, содержащую один и только один символ, в символ или символ в строку из одного символа; предикат имеет формат:
str_char(String,Char) % (i,o), (o,i), (i,i)
Предикат str_int/2
Предикат str_int преобразует строку, содержащую целое число, в его текстовое представление и имеет формат:
str_int(String,Integer) % (i,o), (o,i), (i,i)
Предикат str_real/2
Предикат str_real преобразует строку в вещественное число или вещественное число в строку и имеет формат:
str_real(String,Real) % (i,o), (o,i), (i,i)
Предикат upper_lower/2
Предикат upper_lower преобразует строку, все символы (или часть символов) которой являются символами верхнего регистра, в строку соответствующих символов нижнего регистра, и наоборот. Формат предиката:
upper_lower(Upper,Lower) % (i,o), (o,i), (i,i)
53. Множества.
Список, который не содержит повторных вхождений элементов называется множеством.
Начнем с написания предиката, превращающего произвольный список во множество. Для этого нужно удалить все повторные вхождения элементов. При этом мы воспользуемся предикатом delete_all. Предикат будет иметь два аргумента: первый – исходный список (возможно, содержащий повторные вхождения элементов), второй – выходной (то, что остается от первого аргумента после удаления повторных вхождений элементов).
Предикат будет реализован посредством рекурсии. Базисом рекурсии является очевидный факт: в пустом списке никакой элемент не встречается более одного раза.
Шаг рекурсии позволит выполнить правило: чтобы сделать из непустого списка множество, нужно удалить из хвоста списка все вхождения первого элемента списка, если таковые вдруг обнаружатся. После выполнения этой операции первый элемент гарантированно будет встречаться в списке ровно один раз. Для того чтобы превратить во множество весь список, остается превратить во множество хвост исходного списка. Для этого нужно только рекурсивно применить к хвосту исходного списка наш предикат, удаляющий повторные вхождения элементов. Полученный в результате из хвоста список с приписанным в качестве головы первым элементом и будет требуемым результатом.
Закодируем наши рассуждения.
list_set([],[]). /* пустой список является списком
в нашем понимании */
list_set ([H|T],[H|T1]):–
delete_all(H,T,T2),
/* T2 — результат удаления
вхождений первого элемента
исходного списка H из хвоста T */
list_set (T2,T1).
/* T1 — результат удаления повторных вхождений элементов из списка T2*/
Например, если применить этот предикат к списку [1,2,1,2,3, 2,1], то результатом будет список [1,2,3].
Заметим, что в предикате, обратном только что записанному предикату list_set и переводящем множество в список, нет никакой необходимости по той причине, что наше множество уже является списком.
54. Раздел предложений.
В раздел clauses (предложений) вы помещаете все факты и правила, составляющие вашу программу. Основное внимание на этом шаге было уделено рассмотрению предложений (фактов и правил) программы: что они означают, как их писать и т. д.
Если вы поняли, что собой представляют факты и правила и как их записывать в Прологе, то вы знаете, что все предложения для каждого конкретного предиката в разделе clauses должны располагаться вместе. Последовательность предложений, описывающих один предикат, называется процедурой.
Пытаясь разрешить цель, Пролог (начиная с первого предложения раздела clauses) будет просматривать каждый факт и каждое правило, стремясь найти сопоставление. По мере продвижения вниз по разделу clauses, он устанавливает внутренний указатель на первое предложение, являющееся частью пути, ведущего к решению. Если следующее предложение не является частью этого логического пути, то Пролог возвращается к установленному указателю и ищет очередное подходящее сопоставление, перемещая указатель на него (этот процесс называется поиск с возвратом).
55. Раздел предикатов.
Если в разделе clauses программы на Прологе вы описали собственный предикат, то вы обязаны объявить его в разделе predicates (предикатов); в противном случае Пролог не поймет, о чем вы ему "говорите". В результате объявления предиката вы сообщаете, к каким доменам (типам) принадлежат аргументы этого предиката.
Предикаты задают факты и правила. В разделе же predicates все предикаты просто перечисляются с указанием типов (доменов) их аргументов. Эффективность работы Пролога значительно возрастает именно из-за того, что вы объявляете типы объектов (аргументов), с которыми работают ваши факты и правила.
Имена предикатов
Имя предиката должно начинаться с буквы, за которой может располагаться последовательность букв, цифр и символов подчеркивания. Регистр букв не имеет значения, однако мы не советуем вам использовать заглавные буквы в качестве первой буквы имени предиката. Имя предиката может иметь длину до 250 символов.
В именах предикатов запрещается использовать пробел, символ минус, звездочку и другие алфавитно-цифровые символы.
Имена предикатов и аргументов могут состоять из любых комбинаций этих символов при условии, что вы подчиняетесь правилам построения соответствующих имен. Агументы предикатов
Аргументы предикатов должны принадлежать доменам, известным Прологу. Эти домены могут быть либо стандартными доменами, либо некоторыми из тех, что вы объявляли в разделе доменов.
56. Раздел доменов.
Домены позволяют задавать разные имена различным видам данных, которые, в противном случае, будут выглядеть абсолютно одинаково. В программах Пролога объекты в отношениях (аргументы предикатов) принадлежат доменам, причем это могут быть как стандартные, так и описанные вами специальные домены.
Раздел domains служит двум полезным целям. Во-первых, вы можете задать доменам осмысленные имена, даже если внутренне эти домены аналогичны уже имеющимся стандартным. Во-вторых, объявление специальных доменов используется для описания структур данных, отсутствующих в стандартных доменах. Иногда очень полезно описать новый домен - особенно, когда вы хотите прояснить отдельные части раздела predicates. Объявление собственных доменов, благодаря присваиванию осмысленных имен типам аргументов, помогает документировать описываемые вами предикаты.
57. Раздел цели.
Во существу, раздел goal (цели) аналогичен телу правила: это просто список подцелей. Цель отличается от правила лишь следующим:
· за ключевым словом goal не следует ":-";
· при запуске программы Пролог автоматически выполняет цель.
Это происходит так, как будто Пролог вызывает goal, запуская тем самым программу, которая пытается разрешить тело правила goal. Если все подцели в разделе goal истинны, - программа завершается успешно. Если же какая-то подцель из дела goal ложна, то считается, что программа завершается неуспешно (хотя чисто внешне никакой разницы в этих случаях нет, - программа просто завершит свою работу).
58. Описание доменов.
Как в любом другом языке программирования, в Прологе все используемые конструкции должны быть предварительно описаны. Поэтому в описании предиката мы должны указать типы его аргументов.
В Прологе имеется 6 встроенных типов доменов, решающих эту задачу. Кроме того, существует возможность создания новых типов доменов на базе стандартных.
Перечислим основные способы создания новых доменов.
1. Создание псевдонимов (альтернативных имен) стандартных доменов. Эта операция осуществляется по следующей схеме:
<новое имя домена> = <стандартное имя домена>.
Этот формат служит для объявления нового имени домена, состоящего из элементов (доменов) стандартных типов, к которым относятся типы, перечисленные в таблице 1. Этот способ применяется для объявления типов объектов, которые подобны синтаксически, но отличаются семантически (по смыслу), и поэтому не должны в программе смешиваться друг с другом. Отнесение их к различным, определенным программистом типам, позволяет компилятору осуществлять тщательный контроль их использования в программе.
2. Создание домена типа "список". Этот формат применяется при описании предикатов, осуществляющих обработку списков. Общий вид создания такого домена следующий:
<домен типа "список"> = <тип элементов списка>*.
Символ "*" (звездочка) "говорит" о том, что создаваемый домен является списком. Тип элементов списка может относиться как к стандартному типу, так и к доменам, определенным программистом. Например:
list_int = integer* /*Домен типа списка целых чисел.*/
list_char = char* /*Домен типа списка символов.*/
Более детально мы рассмотрим описание доменов типа "список" в соответствующем разделе.
3. Создание домена типа "структура". Чаще всего этот формат применяется при организации баз данных. Его общий вид следующий:
4. <структура> =
5. <функтор1> (<домен11>,<домен12>,...,<домен1N>);
6. <функтор2> (<домен21>,<домен22>,...,<домен2N>)
Объявление структуры (домена, состоящего из сложных и перекрывающихся объектов) состоит из имени структуры - функтора и доменов всех используемых компонент и подкомпонент данной структуры. Например, можно объявить домен "владелец" так:
владелец = имеет(фамилия,книга)
и затем задавать его элементы в программе, например, так:
имеет(Иванов,книга(Стругацкие,"Жук в муравейнике"))
7. Создание домена типа "файл". Этот домен применяется в том случае, когда в программе необходимо ссылаться на файлы с помощью файловых переменных (логических имен файлов). Формат создания такого домена следующий:
8. file = <имя1>;< имя1>;...; < имяN>.
59. Задание типов аргументов при декларации предикатов. Арность (размерность).
Объявление доменов аргументов в разделе predicates называется заданием типов аргументов. Предположим, имеется следующая связь объектов:
Символы
Символы имеют тип char. Печатные символы (ASCII 32-127) - это цифры (0-9), прописные буквы A-Z, строчные буквы a-z, символы пунктуации и специальные символы.
Символ-константа записывается в простых кавычках:
' a ' '3'
Числа
Числа могут быть целыми (integer) или вещественными (real). Вещественные имеют значения от 1е-308 до 1е308 (от 10-308 до 10+308).
63. Составные объекты данных и функторы.
Составные объекты данных позволяют интерпретировать некоторые части информации как единое целое таким образом, чтобы затем можно было легко разделить их вновь. Возьмем, например, дату "октябрь 15, 1991". Она состоит из трех частей информации - месяц, день и год. Представим ее на рис. 1, как древовидную структypy.
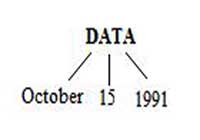
Рис.1. Древовидная структура даты
Вы можете сделать это, объявив домен, содержащий составной объект date:
domains
date_cmp = date(string,integer,integer)
а затем просто записать:
D=date("October",15,1991).
Такая запись выглядит как факт Пролога, но это не так - это объект данных, который вы можете обрабатывать наряду с символами и числами. Он начинается с имени, называемого функтором (в данном случае date), за которым следуют три аргумента.
Аргументы составного объекта данных могут сами быть составными объектами. Например, вы можете рассматривать чей-нибудь день рождения (рис. 2), как информацию со следующей структурой:
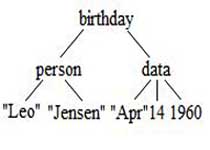
Рис.2. Древовидная структура даты рождения
На языке Пролог это выглядит следующим образом:
birthday(person("Leo", "Jensen"),date("Apr ", 14, 1991))
У составного объекта birthday в этом примере есть две части: объект person ("Leo","Jensen") и объект date("Apr",14,1900). Функторами для этих объектов будут person и date.
Интенсионал и экстенсионал понятия
Интенсиональные знания — это знания о связях между атрибутами (признаками) объектов данной предметной области. Они оперируют абстрактными объектами, событиями и отношениями.
Экстенсиональные знания представляют собой данные, характеризующие конкретные объекты, их состояния, значения параметров в пространстве и времени
10. Глубинные и поверхностные знания, их отличие
В глубинных знаниях отражается понимание структуры предметной области, назначение и взаимосвязь отдельных понятий (глубинные знания в фундаментальных науках — это законы и теоретические основания). Поверхностные знания обычно касаются внешних эмпирических ассоциаций с каким-либо феноменом предметной области.
Например, для разговора по телефону требуется лишь поверхностное знание того, что, сняв трубку и правильно набрав номер, мы соединимся с нужным абонентом. Большинство людей не испытывает необходимости в глубинных представлениях о структуре телефонной связи, конструкции телефонного аппарата, которыми, безусловно, пользуются специалисты по телефонии.
Отмечается, что большинство экспертных систем основано на применении поверхностных знаний. Это, однако, нередко не мешает достигать вполне удовлетворительных результатов. Вместе с тем, опора на глубинные представления помогает создавать более мощные, гибкие и интеллектуальные адаптивные системы. Наглядным примером может служить медицина. Здесь молодой и недостаточно опытный врач часто действует по поверхностной модели: «Если кашель — то пить таблетки от кашля, если ангина — то эритромицин» и т. п. В то же время опытный врач, основываясь на глубинных знаниях, способен порождать разнообразные способы лечения одной и той же болезни в зависимости от индивидуальных особенностей пациента, его состояния, наличия доступных лекарств в аптечной сети и т. д.
Глубинные знания являются результатом обобщения первичных понятий предметной области в некоторые более абстрактные структуры. Степень глубины и уровень обобщенности знаний непосредственно связаны с опытом экспертов и могут служить показателем их профессионального мастерства.
11. Процедурные и декларативные знания
Инженерия знаний определяет их как набор фактов, понятий, правил и эвристики, направленных па решение задач. Знания о каком-либо предмете могут быть разделены на две группы: декларативные и процедурные. Декларативные знания — это описательное представление в какой-либо предметной области. Это поверхностные знания о том, что собой представляет предмет, как он выглядит и что он означает. Знание того, «что» представляет собой отчет о прибылях и убытках, является примером декларативного знания (знания фактов). Процедурные знания являются набором интеллектуальных способностей, направленных на знание того, «как» сделать что-либо (например, как подготовить годовой отчет о прибылях и убытках фирмы). Процедурные знания являются предписывающими: они используют процедурные знания для определения образа действий.
Факты и понятия по большей части относятся к декларативным знаниям. Правила и алгоритмы являются примерами процедурных знаний. Наличие процедуры выполнения какого-либо действия не обязательно означает наличие навыков, необходимых для осуществления задачи. Декларативные и процедурные знания отдельного человека основаны на его опыте, воспитании и обучении. Знания подразумевают изучение, осведомленность и компетентность в различных вопросах, которые представлены в ментальных моделях (интеллектуальные модели).
Существует особый вид знаний, называемых здравым смыслом. Он формируется со временем и представляет собой накопленные декларативные и процедурные знания, которые сами собой разумеются для большинства людей. Здравый смысл, построенный на основе информации, представляет собой совокупность информации по какому-либо вопросу, которую «следует знать» всем. Такие знания также называются знаниями общего плана и могут быть описаны как процедуры, установленные порядки и процессы, направленные на эффективное выполнение различных (профессиональных) задач.
Наиболее важным аспектом знаний является их долговечность. Неизменные знания, такие как чаконы природы, не меняются со временем. Статичные знания, такие как политика бизнеса или его процедуры, статичны лишь какое-то время — рано или поздно их ждут перемены. Динамичные знания, такие как условия рынка или норма возврата инвестиций, изменяются от одного приложения к другому.
12. Модели представления знаний; продукционная модель
Продукционная система — это модель вычислений, играющая особо важную роль для создания алгоритмов поиска и для моделирования решения задач человеком. Продукционная система обеспечивает управление процессом решения задачи по образцу и состоит из набора продукционных правил, рабочей памяти и цикла управления "распознавание-действие".
Продукционную систему можно определить на основе следующих категорий.
1. Набор продукционных правил. Их часто просто называют продукциями. Продукция — это пара "условие-действие", которая определяет одну порцию знаний, необходимых для решения задачи. Условная часть правила — это образец (шаблон), который определяет, когда это правило может быть применено для решения какого-либо этапа задачи. Часть действия определяет соответствующий шаг в решении задачи.
2. Рабочая память содержит описание текущего состояния мира в процессе рассуждений. Это описание является образцом, который сопоставляется с условной частью продукции с целью выбора соответствующих действий при решении задачи. Если условие некоторого правила соответствует содержимому рабочей памяти, то может выполняться действие, связанное с этим условием. Действия продукционных правил предназначены для изменения содержания рабочей памяти.
3. Цикл "распознавание-действие". Управляющая структура продукционной системы проста: рабочая память инициализируется начальным описанием задачи. Текущее состояние решения задачи представляется набором образцов в рабочей памяти. Эти образцы сопоставляются с условиями продукционных правил; что порождает подмножество правил вывода, называемое конфликтным множеством. Условия этих правил согласованы с образцами в рабочей памяти. Продукции, содержащиеся в конфликтном множестве, называют допустимыми. Выбирается и активизируется одна из продукций конфликтного множества (разрешение конфликта). Активизация правила означает выполнение его действия. При этом изменяется содержание рабочей памяти. После того как выбранное правило сработало, цикл управления повторяется для модифицированной рабочей памяти. Процесс заканчивается, если содержимое рабочей памяти не соответствует никаким условиям.
13. Модели представления знаний; семантическая сеть
Понятие семантической сети основано на древней и очень простой идее о том, что «память» формируется через ассоциации между понятиями.
Базовыми функциональными элементами семантической сети служит структура из двух компонентов – узлов и связывающих их дуг. Таким образом, семантической сетью называется ориентированный граф с конечными вершинами. Каждый его узел представляет собой некоторое понятие, а дуга – отношение между парой понятий. Можно считать, что каждая из таких пар отношений представляет простой факт. Узлы в семантической сети соответствуют объектам, понятиям или событиям. Они обладают определенной маркировкой, позволяющий идентифицировать этот узел.
Основной принцип семантической сети: знания, которые семантически связаны между собой (связаны по смыслу) должны храниться рядом. В семантической сети имеется два типа дуг:
1. является (is)
2. имеет частью (has part)
Дуги обладают свойством транзитивности – устанавливают отношения иерархии наследования в сети (элементы низкого
|
|
|

Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ - конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой...

Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...

Индивидуальные очистные сооружения: К классу индивидуальных очистных сооружений относят сооружения, пропускная способность которых...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!