До этого мы уже вычисляли итоги для конкретного отдела, примерно следующим образом:
SELECT
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные только по ИТ отделу
А теперь представьте, что нас попросили получить такие же цифры в разрезе каждого отдела. Конечно мы можем засучить рукава и выполнить этот же запрос для каждого отдела. Итак, сказано-сделано, пишем 4 запроса:
SELECT
'Администрация' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 -- данные по Администрации
SELECT
'Бухгалтерия' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 -- данные по Бухгалтерии
SELECT
'ИТ' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные по ИТ отделу
SELECT
'Прочие' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам
В результате мы получим 4 набора данных:
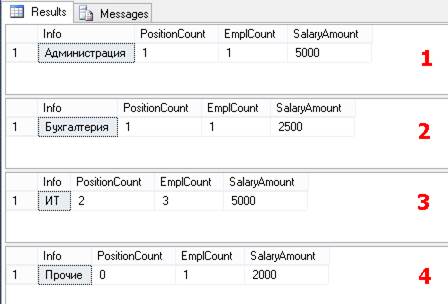
Обратите внимание, что мы можем использовать поля, заданные в виде констант – 'Администрация', 'Бухгалтерия', …
В общем все цифры, о которых нас просили, мы добыли, объединяем все в Excel и отдаем директору.
Отчет директору понравился, и он говорит: «а добавьте еще колонку с информацией по среднему окладу». И как всегда это нужно сделать очень срочно.
Мда, что делать?! Вдобавок представим еще что отделов у нас не 3, а 15.
Вот как раз то примерно для таких случаев служит конструкция GROUP BY:
SELECT
DepartmentID,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
| DepartmentID
| PositionCount
| EmplCount
| SalaryAmount
| SalaryAvg
|
| NULL
| 0
| 1
| 2000
| 2000
|
| 1
| 1
| 1
| 5000
| 5000
|
| 2
| 1
| 1
| 2500
| 2500
|
| 3
| 2
| 3
| 5000
| 1666.66666666667
|
Мы получили все те же самые данные, но теперь используя только один запрос!
Пока не обращайте внимание, на то что департаменты у нас вывелись в виде цифр, дальше мы научимся выводить все красиво.
В предложении GROUP BY можно указывать несколько полей «GROUP BY поле1, поле2, …, полеN», в этом случае группировка произойдет по группам, которые образовывают значения данных полей «поле1, поле2, …, полеN».
Для примера, сделаем группировку данных в разрезе Отделов и Должностей:
SELECT
DepartmentID,PositionID,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID,PositionID
| DepartmentID
| PositionID
| EmplCount
| SalaryAmount
|
| NULL
| NULL
| 1
| 2000
|
| 2
| 1
| 1
| 2500
|
| 1
| 2
| 1
| 5000
|
| 3
| 3
| 2
| 3000
|
| 3
| 4
| 1
| 2000
|
Давайте, теперь на этом примере, попробуем разобраться как работает GROUP BY
Для полей, перечисленных после GROUP BY из таблицы Employees определяются все уникальные комбинации по значениям DepartmentID и PositionID, т.е. происходит примерно следующее:
SELECT DISTINCT DepartmentID,PositionID
FROM Employees
| DepartmentID
| PositionID
|
| NULL
| NULL
|
| 1
| 2
|
| 2
| 1
|
| 3
| 3
|
| 3
| 4
|
После чего делается пробежка по каждой комбинации и делаются вычисления агрегатных функций:
SELECT
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL AND PositionID IS NULL
SELECT
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 AND PositionID=2
--...
SELECT
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 AND PositionID=4
А потом все эти результаты объединяются вместе и отдаются нам в виде одного набора:
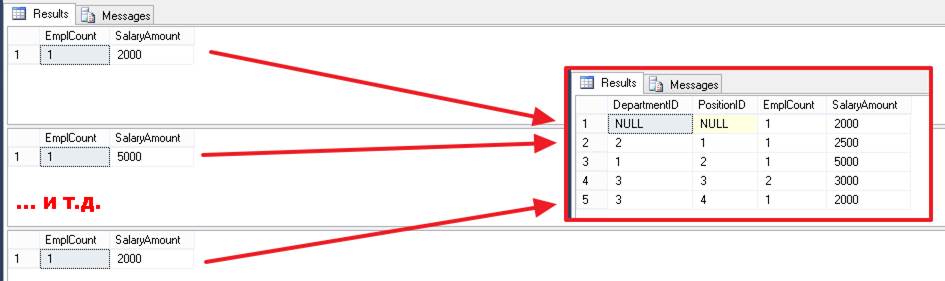
Из основного, стоит отметить, что в случае группировки (GROUP BY), в перечне колонок в блоке SELECT:
·Мы можем использовать только колонки, перечисленные в блоке GROUP BY
·Можно использовать выражения с полями из блока GROUP BY
·Можно использовать константы, т.к. они не влияют на результат группировки
·Все остальные поля (не перечисленные в блоке GROUP BY) можно использовать только с агрегатными функциями (COUNT, SUM, MIN, MAX, …)
·Не обязательно перечислять все колонки из блока GROUP BY в списке колонок SELECT
И демонстрация всего сказанного:
SELECT
'Строка константа' Const1, -- константа в виде строки
1 Const2, -- константа в виде числа
-- выражение с использованием полей участвуещих в группировке
CONCAT('Отдел № ',DepartmentID) ConstAndGroupField,
CONCAT('Отдел № ',DepartmentID,', Должность № ',PositionID) ConstAndGroupFields,
DepartmentID, -- поле из списка полей участвующих в группировке
-- PositionID, -- поле учавствующее в группировке, не обязательно дублировать здесь
COUNT(*) EmplCount, -- кол-во строк в каждой группе
-- остальные поля можно использовать только с агрегатными функциями: COUNT, SUM, MIN, MAX, …
SUM(Salary) SalaryAmount,
MIN(ID) MinID
FROM Employees
GROUP BY DepartmentID,PositionID -- группировка по полям DepartmentID,PositionID
| Const1
| Const2
| ConstAndGroupField
| ConstAndGroupFields
| DepartmentID
| EmplCount
| SalaryAmount
| MinID
|
| Строка константа
| 1
| Отдел №
| Отдел №, Должность №
| NULL
| 1
| 2000
| 1005
|
| Строка константа
| 1
| Отдел № 2
| Отдел № 2, Должность № 1
| 2
| 1
| 2500
| 1002
|
| Строка константа
| 1
| Отдел № 1
| Отдел № 1, Должность № 2
| 1
| 1
| 5000
| 1000
|
| Строка константа
| 1
| Отдел № 3
| Отдел № 3, Должность № 3
| 3
| 2
| 3000
| 1001
|
| Строка константа
| 1
| Отдел № 3
| Отдел № 3, Должность № 4
| 3
| 1
| 2000
| 1003
|
Так же стоит отметить, что группировку можно делать не только по полям, но также и по выражениям. Для примера сгруппируем данные по сотрудникам, по годам рождения:
SELECT
CONCAT('Год рождения - ',YEAR(Birthday)) YearOfBirthday,
COUNT(*) EmplCount
FROM Employees
GROUP BY YEAR(Birthday)
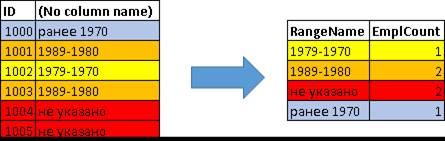
Рассмотрим пример с более сложным выражением. Для примера, получим градацию сотрудников по годам рождения:
SELECT
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END RangeName,
COUNT(*) EmplCount
FROM Employees
GROUP BY
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END
| RangeName
| EmplCount
|
| 1979-1970
| 1
|
| 1989-1980
| 2
|
| не указано
| 2
|
| ранее 1970
| 1
|
Т.е. в данном случае группировка делается по предварительно вычисленному для каждого сотрудника CASE-выражению:
SELECT
ID,
CASE
WHEN YEAR(Birthday)>=2000 THEN 'от 2000'
WHEN YEAR(Birthday)>=1990 THEN '1999-1990'
WHEN YEAR(Birthday)>=1980 THEN '1989-1980'
WHEN YEAR(Birthday)>=1970 THEN '1979-1970'
WHEN Birthday IS NOT NULL THEN 'ранее 1970'
ELSE 'не указано'
END
FROM Employees
Ну и конечно же вы можете объединять в блоке GROUP BY выражения с полями:
SELECT
DepartmentID,
CONCAT('Год рождения - ',YEAR(Birthday)) YearOfBirthday,
COUNT(*) EmplCount
FROM Employees
GROUP BY YEAR(Birthday),DepartmentID -- порядок может не совпадать с порядком их использования в блоке SELECT
ORDER BY DepartmentID,YearOfBirthday -- напоследок мы можем применить к результату сортировку
Вернемся к нашей изначальной задаче. Как мы уже знаем, отчет очень понравился директору, и он попросил нас делать его еженедельно, дабы он мог мониторить изменения по компании. Чтобы, не перебивать каждый раз в Excel цифровое значение отдела на его наименование, воспользуемся знаниями, которые у нас уже есть, и усовершенствуем наш запрос:
SELECT
CASE DepartmentID
WHEN 1 THEN 'Администрация'
WHEN 2 THEN 'Бухгалтерия'
WHEN 3 THEN 'ИТ'
ELSE 'Прочие'
END Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
ORDER BY Info -- добавим для большего удобства сортировку по колонке Info
| Info
| PositionCount
| EmplCount
| SalaryAmount
| SalaryAvg
|
| Администрация
| 1
| 1
| 5000
| 5000
|
| Бухгалтерия
| 1
| 1
| 2500
| 2500
|
| ИТ
| 2
| 3
| 5000
| 1666.66666666667
|
| Прочие
| 0
| 1
| 2000
| 2000
|
Хоть со стороны может выглядит и страшно, но все равно это получше чем было изначально. Недостаток в том, что если заведут новый отдел и его сотрудников, то выражение CASE нам нужно будет дописывать, дабы сотрудники нового отдела не попали в группу «Прочие».
Но ничего, со временем, мы научимся делать все красиво, чтобы выборка у нас не зависела от появления в БД новых данных, а была динамической. Немного забегу вперед, чтобы показать к написанию каких запросов мы стремимся прийти:
SELECT
ISNULL(dep.Name,'Прочие') DepName,
COUNT(DISTINCT emp.PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(emp.Salary) SalaryAmount,
AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
GROUP BY emp.DepartmentID,dep.Name
ORDER BY DepName
В общем, не переживайте – все начинали с простого. Пока вам просто нужно понять суть конструкции GROUP BY.
Напоследок, давайте посмотрим каким образом можно строить сводные отчеты при помощи GROUP BY.
Для примера выведем сводную таблицу, в разрезе отделов, так чтобы была подсчитана суммарная заработная плата, получаемая сотрудниками в разбивке по должностям:
SELECT
DepartmentID,
SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера],
SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора],
SUM(CASE WHEN PositionID=3 THEN Salary END) [Программисты],
SUM(CASE WHEN PositionID=4 THEN Salary END) [Старшие программисты],
SUM(Salary) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
| DepartmentID
| Бухгалтера
| Директора
| Программисты
| Старшие программисты
| Итого по отделу
|
| NULL
| NULL
| NULL
| NULL
| NULL
| 2000
|
| 1
| NULL
| 5000
| NULL
| NULL
| 5000
|
| 2
| 2500
| NULL
| NULL
| NULL
| 2500
|
| 3
| NULL
| NULL
| 3000
| 2000
| 5000
|
Т.е. мы свободно можем использовать любые выражения внутри агрегатных функций.
Можно конечно переписать и при помощи IIF:
SELECT
DepartmentID,
SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера],
SUM(IIF(PositionID=2,Salary,NULL)) [Директора],
SUM(IIF(PositionID=3,Salary,NULL)) [Программисты],
SUM(IIF(PositionID=4,Salary,NULL)) [Старшие программисты],
SUM(Salary) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
Но в случае с IIF нам придется явно указывать NULL, которое возвращается в случае невыполнения условия.
В аналогичных случаях мне больше нравится использовать CASE без блока ELSE, чем лишний раз писать NULL. Но это конечно дело вкуса, о котором не спорят.
И давайте вспомним, что в агрегатных функциях при агрегации не учитываются NULL значения.
Для закрепления, сделайте самостоятельный анализ полученных данных по развернутому запросу:
SELECT
DepartmentID,
CASE WHEN PositionID=1 THEN Salary END [Бухгалтера],
CASE WHEN PositionID=2 THEN Salary END [Директора],
CASE WHEN PositionID=3 THEN Salary END [Программисты],
CASE WHEN PositionID=4 THEN Salary END [Старшие программисты],
Salary [Итого по отделу]
FROM Employees
| DepartmentID
| Бухгалтера
| Директора
| Программисты
| Старшие программисты
| Итого по отделу
|
| 1
| NULL
| 5000
| NULL
| NULL
| 5000
|
| 3
| NULL
| NULL
| 1500
| NULL
| 1500
|
| 2
| 2500
| NULL
| NULL
| NULL
| 2500
|
| 3
| NULL
| NULL
| NULL
| 2000
| 2000
|
| 3
| NULL
| NULL
| 1500
| NULL
| 1500
|
| NULL
| NULL
| NULL
| NULL
| NULL
| 2000
|
И еще давайте вспомним, что если вместо NULL мы хотим увидеть нули, то мы можем обработать значение, возвращаемое агрегатной функцией. Например:
SELECT
DepartmentID,
ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера],
ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора],
ISNULL(SUM(IIF(PositionID=3,Salary,NULL)),0) [Программисты],
ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старшие программисты],
ISNULL(SUM(Salary),0) [Итого по отделу]
FROM Employees
GROUP BY DepartmentID
| DepartmentID
| Бухгалтера
| Директора
| Программисты
| Старшие программисты
| Итого по отделу
|
| NULL
| 0
| 0
| 0
| 0
| 2000
|
| 1
| 0
| 5000
| 0
| 0
| 5000
|
| 2
| 2500
| 0
| 0
| 0
| 2500
|
| 3
| 0
| 0
| 3000
| 2000
| 5000
|
Теперь в целях практики, вы можете:
·вывести названия департаментов вместо их идентификаторов, например, добавив выражение CASE обрабатывающее DepartmentID в блоке SELECT
·добавьте сортировку по имени отдела при помощи ORDER BY
GROUP BY в скупе с агрегатными функциями, одно из основных средств, служащих для получения сводных данных из БД, ведь обычно данные в таком виде и используются, т.к. обычно от нас требуют предоставления сводных отчетов, а не детальных данных (простыней). И конечно же все это крутится вокруг знания базовой конструкции, т.к. прежде чем что-то подытожить (агрегировать), вам нужно первым делом это правильно выбрать, используя «SELECT … WHERE …».
Важное место здесь имеет практика, поэтому, если вы поставили целью понять язык SQL, не изучить, а именно понять – практикуйтесь, практикуйтесь и практикуйтесь, перебирая самые разные варианты, которые только сможете придумать.
На начальных порах, если вы не уверены в правильности полученных агрегированных данных, делайте детальную выборку, включающую все значения, по которым идет агрегация. И проверяйте правильность расчетов вручную по этим детальным данным. В этом случае очень сильно может помочь использование программы Excel.






