

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...

Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...
Топ:
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Процедура выполнения команд. Рабочий цикл процессора: Функционирование процессора в основном состоит из повторяющихся рабочих циклов, каждый из которых соответствует...
Оценка эффективности инструментов коммуникационной политики: Внешние коммуникации - обмен информацией между организацией и её внешней средой...
Интересное:
Подходы к решению темы фильма: Существует три основных типа исторического фильма, имеющих между собой много общего...
Распространение рака на другие отдаленные от желудка органы: Характерных симптомов рака желудка не существует. Выраженные симптомы появляются, когда опухоль...
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:

Для смены текущей базы данных можно использовать выпадающий список:
Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.

После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.

Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.
СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
|
|
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL — язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML — подмножество языка SQL:
· Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
· Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
-- однострочный комментарий
и
/*
многострочный
комментарий
*/
Собственно, все для теории этого будет достаточно.
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).
|
|
Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение
)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID)
)
Или:
CREATE TABLE Employees(
ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
|
|
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:
· CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
· DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
· ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
· ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY (поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
· ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:
· Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
· ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
· ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
· ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY (поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:
· PRIMARY KEY – первичный ключ;
· FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
· UNIQUE – позволяет создать уникальность;
· CHECK – позволяет осуществлять корректность введенных данных;
· DEFAULT – позволяет задать значение по умолчанию;
· Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
|
|
Так же мы частично затронули тему индексов и разобрали понятие кластерный (CLUSTERED) и некластерный (NONCLUSTERED) индекс.
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.
Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','[email protected]',2,1,NULL),
(1001,N'Петров П.П.','19831203','[email protected]',3,3,1003),
(1002,N'Сидоров С.С.','19760607','[email protected]',1,2,1000),
(1003,N'Андреев А.А.','19820417','[email protected]',4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексов
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> (column [ ASC | DESC ] [,...n ])
[ INCLUDE (column_name [,...n ]) ]
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.
Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
|
|
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.
Скрипт создания БД Test
Все, теперь мы готовы приступить к изучению языка DML.
Задание псевдонимов для таблиц
При перечислении колонок их можно предварять именем таблицы, находящейся в блоке FROM:
SELECT Employees.ID,Employees.Name
FROM Employees
Но такой синтаксис обычно использовать неудобно, т.к. имя таблицы может быть длинным. Для этих целей обычно задаются и применяются более короткие имена – псевдонимы (alias):
SELECT emp.ID,emp.Name
FROM Employees AS emp
или
SELECT emp.ID,emp.Name
FROM Employees emp -- ключевое слово AS можно отпустить (я предпочитаю такой вариант)
Здесь emp – псевдоним для таблицы Employees, который можно будет использоваться в контексте данного оператора SELECT. Т.е. можно сказать, что в контексте этого оператора SELECT мы задаем таблице новое имя.
Конечно, в данном случае результаты запросов будут точно такими же как и для «SELECT ID,Name FROM Employees». Для чего это нужно будет понятно дальше (даже не в этой части), пока просто запоминаем, что имя колонки можно предварять (уточнять) либо непосредственно именем таблицы, либо при помощи псевдонима. Здесь можно использовать одно из двух, т.е. если вы задали псевдоним, то и пользоваться нужно будет им, а использовать имя таблицы уже нельзя.
На заметку. В ORACLE допустим только вариант задания псевдонима таблицы без ключевого слова AS.
Ненадолго вернемся к DDL
Так как данных для демонстрационных примеров начинает не хватать, а рассказать хочется более обширно и понятно, то давайте чуть расширим нашу таблицу Employess. К тому же немного вспомним DDL, как говорится «повторение – мать учения», и плюс снова немного забежим вперед и применим оператор UPDATE:
-- создаем новые колонки
ALTER TABLE Employees ADD
LastName nvarchar(30), -- фамилия
FirstName nvarchar(30), -- имя
MiddleName nvarchar(30), -- отчество
Salary float, -- и конечно же ЗП в каких-то УЕ
BonusPercent float -- процент для вычисления бонуса от оклада
GO
-- наполняем их данными (некоторые данные намерено пропущены)
UPDATE Employees
SET
LastName=N'Иванов',FirstName=N'Иван',MiddleName=N'Иванович',
Salary=5000,BonusPercent= 50
WHERE ID=1000 -- Иванов И.И.
UPDATE Employees
SET
LastName=N'Петров',FirstName=N'Петр',MiddleName=N'Петрович',
Salary=1500,BonusPercent= 15
WHERE ID=1001 -- Петров П.П.
UPDATE Employees
SET
LastName=N'Сидоров',FirstName=N'Сидор',MiddleName=NULL,
Salary=2500,BonusPercent=NULL
WHERE ID=1002 -- Сидоров С.С.
UPDATE Employees
SET
LastName=N'Андреев',FirstName=N'Андрей',MiddleName=NULL,
Salary=2000,BonusPercent= 30
WHERE ID=1003 -- Андреев А.А.
Убедимся, что данные обновились успешно:
SELECT *
FROM Employees
| ID | Name | … | LastName | FirstName | MiddleName | Salary | BonusPercent |
| 1000 | Иванов И.И. | Иванов | Иван | Иванович | 5000 | 50 | |
| 1001 | Петров П.П. | Петров | Петр | Петрович | 1500 | 15 | |
| 1002 | Сидоров С.С. | Сидоров | Сидор | NULL | 2500 | NULL | |
| 1003 | Андреев А.А. | Андреев | Андрей | NULL | 2000 | 30 |
Задание псевдонимов для столбцов запроса
Думаю, здесь будет проще показать, чем написать:
SELECT
-- даем имя вычисляемому столбцу
LastName+' '+FirstName+' '+MiddleName AS ФИО,
-- использование двойных кавычек, т.к. используется пробел
HireDate AS "Дата приема",
-- использование квадратных скобок, т.к. используется пробел
Birthday AS [Дата рождения],
-- слово AS не обязательно
Salary ZP
FROM Employees
| ФИО | Дата приема | Дата рождения | ZP |
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
Как видим заданные нами псевдонимы столбцов, отразились в заголовке результирующей таблицы. Собственно, это и есть основное предназначение псевдонимов столбцов.
Обратите внимание, т.к. у последних 2-х сотрудников не указано отчество (NULL значение), то результат выражения «LastName+' '+FirstName+' '+MiddleName» так же вернул нам NULL.
Для соединения (сложения, конкатенации) строк в MS SQL используется символ «+».
Запомним, что все выражения в которых участвует NULL (например, деление на NULL, сложение с NULL) будут возвращать NULL.
На заметку.
В случае ORACLE для объединения строк используется оператор «||» и конкатенация будет выглядеть как «LastName||' '||FirstName||' '||MiddleName». Для ORACLE стоит отметить, что у него для строковых типов есть исключение, для них NULL и пустая строка '' это одно и тоже, поэтому в ORACLE такое выражение вернет для последних 2-х сотрудников «Сидоров Сидор» и «Андреев Андрей». На момент версии ORACLE 12c, насколько я знаю, опции которая изменяет такое поведение нет (если не прав, прошу поправить меня). Здесь мне сложно судить хорошо это или плохо, т.к. в одних случаях удобнее поведение NULL-строки как в MS SQL, а в других как в ORACLE.
В ORACLE тоже допустимы все перечисленные выше псевдонимы столбцов, кроме […].
Для того чтобы не городить конструкцию с использованием функции ISNULL, в MS SQL мы можем применить функцию CONCAT. Рассмотрим и сравним 3 варианта:
SELECT
LastName+' '+FirstName+' '+MiddleName FullName1,
-- 2 варианта для замены NULL пустыми строками '' (получаем поведение как и в ORACLE)
ISNULL(LastName,'')+' '+ISNULL(FirstName,'')+' '+ISNULL(MiddleName,'') FullName2,
CONCAT(LastName,' ',FirstName,' ',MiddleName) FullName3
FROM Employees
| FullName1 | FullName2 | FullName3 |
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
В MS SQL псевдонимы еще можно задавать при помощи знака равенства:
SELECT
'Дата приема'=HireDate, -- помимо "…" и […] можно использовать '…'
[Дата рождения]=Birthday,
ZP=Salary
FROM Employees
Использовать для задания псевдонима ключевое слово AS или же знак равенства, наверное, больше дело вкуса. Но при разборе чужих запросов, данные знания могут пригодиться.
Напоследок скажу, что для псевдонимов имена лучше задавать, используя только символы латиницы и цифры, избегая применения '…', "…" и […], то есть использовать те же правила, что мы использовали при наименовании таблиц. Дальше, в примерах я буду использовать только такие наименования и никаких '…', "…" и […].
Немного о строках
В случае проверки строки на наличие Unicode символов, нужно будет ставить перед кавычками символ N, т.е. N'…'. Но так как у нас в таблице все символьные поля в формате Unicode (тип nvarchar), то для этих полей можно всегда использовать такой формат. Пример:
SELECT ID,Name
FROM Employees
WHERE Name LIKE N'Пет%'
SELECT ID,LastName
FROM Employees
WHERE LastName=N'Петров'
Если делать правильно, при сравнении с полем типа varchar (ASCII) нужно стараться использовать проверки с использованием '…', а при сравнении поля с типом nvarchar (Unicode) нужно стараться использовать проверки с использованием N'…'. Это делается для того, чтобы избежать в процессе выполнения запроса неявных преобразований типов. То же самое правило используем при вставке (INSERT) значений в поле или их обновлении (UPDATE).
При сравнении строк стоит учесть момент, что в зависимости от настройки БД (collation), сравнение строк может быть, как регистро-независимым (когда 'Петров'='ПЕТРОВ'), так и регистро-зависимым (когда 'Петров'<>'ПЕТРОВ').
В случае регистро-зависимой настройки, если требуется сделать поиск без учета регистра, то можно, например, сделать предварительное преобразование правого и левого выражения в один регистр – верхний или нижний:
SELECT ID,Name
FROM Employees
WHERE UPPER(Name) LIKE UPPER(N'Пет%') -- или LOWER(Name) LIKE LOWER(N'Пет%')
SELECT ID,LastName
FROM Employees
WHERE UPPER(LastName)=UPPER(N'Петров') -- или LOWER(LastName)=LOWER(N'Петров')
Немного о датах
При проверке на дату, вы можете использовать, как и со строками одинарные кавычки '…'.
Вне зависимости от региональных настроек в MS SQL можно использовать следующий синтаксис дат 'YYYYMMDD' (год, месяц, день слитно без пробелов). Такой формат даты MS SQL поймет всегда:
SELECT ID,Name,Birthday
FROM Employees
WHERE Birthday BETWEEN '19800101' AND '19891231' -- сотрудники 80-х годов
ORDER BY Birthday
В некоторых случаях, дату удобнее задавать при помощи функции DATEFROMPARTS:
SELECT ID,Name,Birthday
FROM Employees
WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31)
ORDER BY Birthday
Так же есть аналогичная функция DATETIMEFROMPARTS, которая служит для задания Даты и Времени (для типа datetime).
Еще вы можете использовать функцию CONVERT, если требуется преобразовать строку в значение типа date или datetime:
SELECT
CONVERT(date,'12.03.2015',104),
CONVERT(datetime,'2014-11-30 17:20:15',120)
Значения 104 и 120, указывают какой формат даты используется в строке. Описание всех допустимых форматов вы можете найти в библиотеке MSDN задав в поиске «MS SQL CONVERT».
Функций для работы с датами в MS SQL очень много, ищите «ms sql функции для работы с датами».
Примечание. Во всех диалектах языка SQL свой набор функций по работе с датами и применяется свой подход по работе с ними.
Немного о числах и их преобразованиях
Информация этого раздела наверно больше будет полезна ИТ-специалистам. Если вы таковым не являетесь, а ваша цель просто научится писать запросы для получения из БД необходимой вам информации, то такие тонкости вам возможно и не понадобятся, но в любом случае можете бегло пройтись по тексту и взять что-то на заметку, т.к. если вы взялись за изучение SQL, то вы уже приобщаетесь к ИТ.
В отличие от функции преобразования CAST, в функции CONVERT можно задать третий параметр, который отвечает за стиль преобразования (формат). Для разных типов данных может использоваться свой набор стилей, которые могут повлиять на возвращаемый результат. Использование стилей мы уже затрагивали при рассмотрении преобразования строки функцией CONVERT в типы date и datetime.
Подробней про функции CAST, CONVERT и стили можно почитать в MSDN – «Функции CAST и CONVERT (Transact-SQL)»: msdn.microsoft.com/ru-ru/library/ms187928.aspx
Для упрощения примеров здесь будут использованы инструкции языка Transact-SQL – DECLARE и SET.
Конечно, в случае преобразования целого числа в вещественное (которое я привел вначале данного урока, в целях демонстрации разницы между целочисленным и вещественным делением), знание нюансов преобразования не так критично, т.к. там мы делали преобразование целого числа в вещественное (диапазон которого намного больше диапазона целых):
DECLARE @min_int int SET @min_int=-2147483648
DECLARE @max_int int SET @max_int=2147483647
SELECT
-- (-2147483648)
@min_int,CAST(@min_int AS float),CONVERT(float,@min_int),
-- 2147483647
@max_int,CAST(@max_int AS float),CONVERT(float,@max_int),
-- numeric(16,6)
@min_int/1., -- (-2147483648.000000)
@max_int/1. -- 2147483647.000000
Возможно не стоило указывать способ неявного преобразования, получаемого делением на (1.), т.к. желательно стараться делать явные преобразования, для большего контроля типа получаемого результата. Хотя, в случае, если мы хотим получить результат типа numeric, с указанным количеством цифр после запятой, то мы можем в MS SQL применить трюк с умножением целого значения на (1., 1.0, 1.00 и т.д):
DECLARE @int int SET @int=123
SELECT
@int*1., -- numeric(12, 0) - 0 знаков после запятой
@int*1.0, -- numeric(13, 1) - 1 знак
@int*1.00, -- numeric(14, 2) - 2 знака
-- хотя порой лучше сделать явное преобразование
CAST(@int AS numeric(20, 0)), -- 123
CAST(@int AS numeric(20, 1)), -- 123.0
CAST(@int AS numeric(20, 2)) -- 123.00
В некоторых случаях детали преобразования могут быть действительно важны, т.к. они влияют на правильность полученного результата, например, в случае, когда делается преобразование числового значения в строку (varchar). Рассмотрим примеры по преобразованию значений типа money и float в varchar:
-- поведение при преобразовании money в varchar
DECLARE @money money
SET @money = 1025.123456789 -- произойдет неявное преобразование в 1025.1235, т.к. тип money хранит только 4 цифры после запятой
SELECT
@money, -- 1025.1235
-- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0)
CAST(@money as varchar(20)), -- 1025.12
CONVERT(varchar(20), @money), -- 1025.12
CONVERT(varchar(20), @money, 0), -- 1025.12 (стиль 0 - без разделителя тысячных и 2 цифры после запятой (формат по умолчанию))
CONVERT(varchar(20), @money, 1), -- 1,025.12 (стиль 1 - используется разделитель тысячных и 2 цифры после запятой)
CONVERT(varchar(20), @money, 2) -- 1025.1235 (стиль 2 - без разделителя и 4 цифры после запятой)
-- поведение при преобразовании float в varchar
DECLARE @float1 float SET @float1 = 1025.123456789
DECLARE @float2 float SET @float2 = 1231025.123456789
SELECT
@float1, -- 1025.123456789
@float2, -- 1231025.12345679
-- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0)
-- стиль 0 - Не более 6 разрядов. По необходимости используется экспоненциальное представление чисел
-- при преобразовании в varchar здесь творятся действительно страшные вещи
CAST(@float1 as varchar(20)), -- 1025.12
CONVERT(varchar(20), @float1), -- 1025.12
CONVERT(varchar(20), @float1, 0), -- 1025.12
CAST(@float2 as varchar(20)), -- 1.23103e+006
CONVERT(varchar(20), @float2), -- 1.23103e+006
CONVERT(varchar(20), @float2, 0), -- 1.23103e+006
-- стиль 1 - Всегда 8 разрядов. Всегда используется экспоненциальное представление чисел.
-- этот стиль для float тоже не очень точен
CONVERT(varchar(20), @float1, 1), -- 1.0251235e+003
CONVERT(varchar(20), @float2, 1), -- 1.2310251e+006
-- стиль 2 - Всегда 16 разрядов. Всегда используется экспоненциальное представление чисел.
-- здесь с точностью уже получше
CONVERT(varchar(30), @float1, 2), -- 1.025123456789000e+003 - OK
CONVERT(varchar(30), @float2, 2) -- 1.231025123456789e+006 - OK
Как видно из примера, плавающие типы float, real в некоторых случаях действительно могут создать большую погрешность, особенно при перегонке в строку и обратно (такое может быть при разного рода интеграциях, когда данные, например, передаются в текстовых файлах из одной системы в другую).
Если нужно явно контролировать точность до определенного знака, более 4-х, то для хранения данных, порой лучше использовать тип decimal/numeric. Если хватает 4-х знаков, то можно использовать и тип money – он примерно соотвествует numeric(20,4).
-- decimal и numeric
DECLARE @money money SET @money = 1025.123456789 -- 1025.1235
DECLARE @float1 float SET @float1 = 1025.123456789
DECLARE @float2 float SET @float2 = 1231025.123456789
DECLARE @numeric numeric(28,9) SET @numeric = 1025.123456789
SELECT
CAST(@numeric as varchar(20)), -- 1025.12345679
CONVERT(varchar(20), @numeric), -- 1025.12345679
CAST(@money as numeric(28,9)), -- 1025.123500000
CAST(@float1 as numeric(28,9)), -- 1025.123456789
CAST(@float2 as numeric(28,9)) -- 1231025.123456789
Примечание.
С версии MS SQL 2008, можно использовать вместо конструкции:
DECLARE @money money
SET @money = 1025.123456789
Более короткий синтаксис инициализации переменных:
DECLARE @money money = 1025.123456789
Заключение второй части
В этой части, я постарался вспомнить и отразить наиболее важные моменты, касающиеся базового синтаксиса. Базовая конструкция – это костяк, без которого нельзя приступать к изучению более сложных конструкций языка SQL.
Агрегатные функции
Здесь мы рассмотрим только основные и наиболее часто используемые агрегатные функции:
| Название | Описание |
| COUNT(*) | Возвращает количество строк полученных оператором «SELECT … WHERE …». В случае отсутствии WHERE, количество всех записей таблицы. |
| COUNT(столбец/выражение) | Возвращает количество значений (не равных NULL), в указанном столбце/выражении |
| COUNT(DISTINCT столбец/выражение) | Возвращает количество уникальных значений, не равных NULL в указанном столбце/выражении |
| SUM(столбец/выражение) | Возвращает сумму по значениям столбца/выражения |
| AVG(столбец/выражение) | Возвращает среднее значение по значениям столбца/выражения. NULL значения для подсчета не учитываются. |
| MIN(столбец/выражение) | Возвращает минимальное значение по значениям столбца/выражения |
| MAX(столбец/выражение) | Возвращает максимальное значение по значениям столбца/выражения |
Агрегатные функции позволяют нам сделать расчет итогового значения для набора строк полученных при помощи оператора SELECT.
Рассмотрим каждую функцию на примере:
SELECT
COUNT(*) [Общее кол-во сотрудников],
COUNT(DISTINCT DepartmentID) [Число уникальных отделов],
COUNT(DISTINCT PositionID) [Число уникальных должностей],
COUNT(BonusPercent) [Кол-во сотрудников у которых указан % бонуса],
MAX(BonusPercent) [Максимальный процент бонуса],
MIN(BonusPercent) [Минимальный процент бонуса],
SUM(Salary/100*BonusPercent) [Сумма всех бонусов],
AVG(Salary/100*BonusPercent) [Средний размер бонуса],
AVG(Salary) [Средний размер ЗП]
FROM Employees
| Общее кол-во сотрудников | Число уникальных отделов | Число уникальных должностей | Кол-во сотрудников у которых указан % бонуса | Максимальный процент бонуса | Минимальный процент бонуса | Сумма всех бонусов | Средний размер бонуса | Средний размер ЗП |
| 6 | 3 | 4 | 3 | 50 | 15 | 3325 | 1108.33333333333 | 2416.66666666667 |
Для большей наглядности я решил здесь сделать исключение и воспользовался синтаксисом […] для задания псевдонимов колонок.
Подведем итоги
Сведем данные полученные во второй и третьей части и рассмотрим конкретное месторасположение каждой изученной нами конструкции и укажем порядок их выполнения:
| Конструкция/Блок | Порядок выполнения | Выполняемая функция |
| SELECT возвращаемые выражения | 4 | Возврат данных полученных запросом |
| FROM источник | 0 | В нашем случае это пока все строки таблицы |
| WHERE условие выборки из источника | 1 | Отбираются только строки, проходящие по условию |
| GROUP BY выражения группировки | 2 | Создание групп по указанному выражению группировки. Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках |
| HAVING фильтр по сгруппированным данным | 3 | Фильтрация, накладываемая на сгруппированные данные |
| ORDER BY выражение сортировки результата | 5 | Сортировка данных по указанному выражению |
Конечно же, вы так же можете применить к сгруппированным данным предложения DISTINCT и TOP, изученные во второй части.
Эти предложения в данном случае применятся к окончательному результату:
SELECT
TOP 1 -- 6. применится в последнюю очередь
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
HAVING SUM(Salary)>3000
ORDER BY DepartmentID -- 5. сортировка результата
| SalaryAmount |
| 5000 |
SELECT
DISTINCT -- показать только уникальные значения SalaryAmount
SUM(Salary) SalaryAmount
FROM Employees
GROUP BY DepartmentID
| SalaryAmount |
| 2000 |
| 2500 |
| 5000 |
Как получились данные результаты проанализируйте самостоятельно.
Заключение
Основная цель которую я ставил в данной части – раскрыть для вас суть агрегатных функций и группировок.
Если базовая конструкция позволяла нам получить необходимые детальные данные, то применение агрегатных функций и группировок к этим детальным данным, дало нам возможность получить по ним сводные данные. Так что, как видите здесь все важно, т.к. одно опирается на другое – без знания базовой конструкции мы не сможем, например, правильно отобрать данные, по которым нам нужно просчитать итоги.
Здесь я намеренно стараюсь показывать только основы, чтобы сосредоточить внимание начинающих на самых главных конструкциях и не перегружать их лишней информацией. Твердое понимание основных конструкций (о которых я еще продолжу рассказ в последующих частях) даст вам возможность решить практически любую задачу по выборке данных из РБД. Основные конструкции оператора SELECT применимы в таком же виде практически во всех СУБД (отличия в основном состоят в деталях, например, в реализации функций – для работы со строками, временем, и т.д.).
В последующем, твердое знание базы даст вам возможность самостоятельно легко изучить разные расширения языка SQL, такие как:
·GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), …
·PIVOT, UNPIVOT
·и т.п.
В рамках данного учебника я решил не рассказывать об этих расширениях, т.к. и без их знания, владея только базовыми конструкциями языка SQL, вы сможете решать очень большой спектр задач. Расширения языка SQL по сути служат для решения какого-то определенного круга задач, т.е. позволяют решить задачу определенного класса более изящно (но не всегда эффективней в плане скорости или затраченных ресурсов).
Если вы делаете первые шаги в SQL, то сосредоточьтесь в первую очередь, именно на изучении базовых конструкций, т.к. владея базой, все остальное вам понять будет гораздо легче, и к тому же самостоятельно. Вам в первую очередь, как бы нужно объемно понять возможности языка SQL, т.е. какого рода операции он вообще позволяет совершить над данными. Донести до начинающих информацию в объемном виде – это еще одна из причин, почему я буду показывать только самые главные (железные) конструкции.
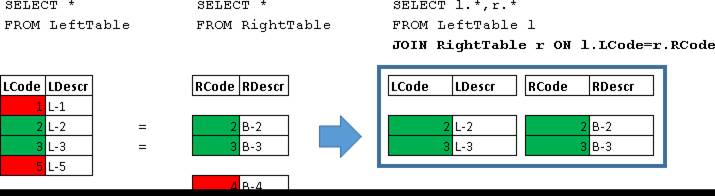
JOIN
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
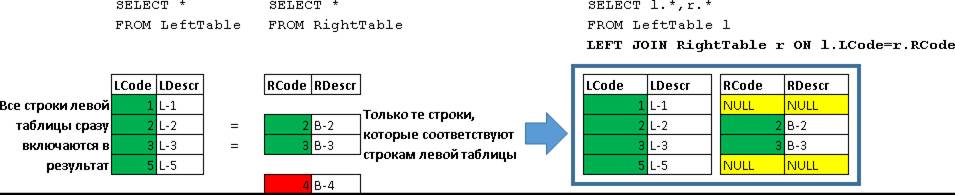
LEFT JOIN
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)
RIGHT JOIN
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)

По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
SELECT l.*,r.*
FROM RightTable r
LEFT JOIN LeftTable l ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode
 Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ - конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой...  Историки об Елизавете Петровне: Елизавета попала между двумя встречными культурными течениями, воспитывалась среди новых европейских веяний и преданий... Семя – орган полового размножения и расселения растений: наружи у семян имеется плотный покров – кожура...  Автоматическое растормаживание колес: Тормозные устройства колес предназначены для уменьшения длины пробега и улучшения маневрирования ВС при... © cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста. |