Основная терминология теории БД
БД – совместно используемый набор логически связанных данных при такой минимальной избыточности их, что позволяет удовлетворять потребности пользователей.
Предметная область – это отражение в БД совокупности объектов реального мира, имеющих отношение к некоторой области знаний и представляющих практическую ценность.
Поскольку БД является динамической моделью предметной области, то каждому объекту присущ ряд характерных для него свойств.
Свойства объекта отображаются с номером переменных величин, которые называются атрибутами. Каждый атрибут может иметь множество значений.
Атрибуты могут быть: атрибуты - признаки; атрибуты - основания.
Атрибуты – признаки – являются качественной характеристикой объекта и участвуют в операциях сравнения, сортировки, компоновки.
Атрибуты – основания – отражают количественную характеристику объекта и как правило участвуют в вычислительных операциях (рост, вес, дата, время).
Любой объект – это совокупность атрибутов–признаков и атрибутов–основания. Множество всех возможных значений атрибута – домен, а совокупность атрибутов – кортеж (отдельная запись, строка в таблице).
Модели данных
Модель представления данных является комбинацией трех компонентов:
1. Множество структур данных, объекты которых составляют содержимое БД.
2. Множество операций, которые применяются для поиска и обработки данных.
3. Множество ограничений целостности, которые явно или неявно определяют множество допустимых значений БД.
Существует три модели представления БД:
- иерархическая;
- сетевая;
- реляционная
(Э. Кодд предложил еще 2: объектно-ориентированная и объектно-реляционная)
Иерархическая модель
Иерархическая модель возникла как обобщение файловой системы и появилась в результате анализа структур данных языка Коболь.
В иерархической модели данные представляются в виде связного графа (дерева). Вершина дерева (Корень) имеет самый высокий уровень и не подчиняется ни какой другой вершине, все остальные вершины починяются какой-то одной вершине, расположенной на более высоком уровне. Уровень вершины измеряется расстоянием до корня. Вершины которые подчиняются другим вершинам называются сыновьями дерева. Иерархическая модель может применятся как при рассмотрение логических структур данных, так и при создании физической структуры данных. Дуга дерева соответствует типу связи и и располагается между двумя типами вершин. Между двумя вершинами может быть не более одной связи.
Иерархическая модель имеет ряд недостатков, которые появились при обработке данных:
1. Существует дублирование данных;
2. Симметричные запросы реализуются по разным алгоритмам;
3. В этой модели затруднительна, а иногда не возможна, реализация связи один ко многим.
Сетевая модель.
Сетевая модель предназначена для ликвидации недостатков, присущих иерархической модели. Данные представляются в виде записей и связей между этими записями. Запись может иметь как множество подчиненных ей записей, так и записей, которым она подчиняется. В С.М. непосредственно реализуются связи М:Н.
1. Поддерживаются бин. связи и связи 1:1, 1:М. Связи М:М поддерживаются с помощью декомпозиции. Типы записей непосредственно связаны друг с другом с помощью конструкции «тип набора» (основной элемент- запись, и 2 указателя(на предыдущую запись и последующую)). Целостность на уровне ссылок поддерживается за счет конструкции тип набора
2. Доступ к типам записей осуществляется путем перемещения по структуре. Для доступа к данным могут использоваться специальные команды.
Реляционная модель
Структурар реляционных данных
Реляционная БД основывается на понятии отношения. Физическим представлением этого отношения является таблица. Т.е. плоская таблица, которая состоит из строк и столбцов. БД – это набор таблиц.
Домен – поименованный столбец отношения.
Кортеж – поименованная строка отношения.
Т.о. каждый атрибут определяется на некотором домене. Отношения характеризуется рядом следующих свойств:
1. Степень – количество атрибутов, которое содержит это отношение.
2. Кардинальность отношения – количество содержащих в отношении кортежей. Может меняться.
Отношения в БД
Реляционная модель представляет из себя набор нормализованных отношений.
| Официальный термин
| Альтернативный термин
| Альтернативный термин2
|
| Отношение
| Таблица
| Файл
|
| Кортеж
| Строка
| Запись
|
| Атрибут
| Столбец
| Поле
|
Реляционная схема – имя отношения, за которым записывается множество пар имен столбцов и доменов.
Отношение R(А1,А2,А3,…,Аn) – n-арное отношения, которое определены на доменах D1,D2,…Dn реляционная схема будет иметь следующий вид:
R (A 1: D 1, A 2: D 2, …, An: Dn)
Свойства отношений
Отношение обладает следующими характеристиками:
1. имеет уникальное имя;
2. Каждая ячейка представляет из себя атомарное неделимое значение;
3. Каждый атрибут отношения имеет уникальное имя;
4. Значения атрибутов берутся из одного и того же домена;
5. каждый картеж отношения является уникальным;
6. Порядок следования отношений является неизменным.
Отношения удовлетворяющие выше указанным характеристикам называются нормализованными отношениями, т.е. отношениями отвечающие первой нормальной форме. Всякое отношение должно приводиться к этой форме для построения реляционной БД.
Реляционные ключи
Реляционная целостность
Для всех допустимых БД задаются правила целостности. В реляционной модели существует два основных правила целостности:
1. Целостность сущностей;
2. Ссылочная целостность.
Первое правило относится к первичным ключам: в базовом отношении первичный ключ не может иметь отсутствующих значений, определенных как NULL. Определитель NULL указывает, что значение атрибута в банный момент не определено или не приемлемо для данного кортежа.
Второе правило касается внешних (вторичных) ключей: если в отношении существует внешний ключ, то его значение должно соответствовать значению потенциального ключа в базовом отношении. Допускается определить внешний ключ как NULL-значение.
Реляционные языки
Используются для управления отношениями в реляционных СУБД. Рел яз подразделяются на процедурные и непроцедурные. Процедурные – пользователь точно указывает системе, как следует манипулировать данными. Непроцедурные – требуют указания какие данные нужны для работы. Реляционная алгебра – процедурный язык. Реляционное исчисление – непроцедурный язык.
Проблемы ER - моделирования
При разработке концептуальной модели могут иметь место проблемы, возникающие в следствие неправильной интерпретации некоторых связей. Эти проблемы называются ловушками соединения (connection trap). Рассмотрим два основных типа ловушек соединения: ловушки разветвления и ловушки разрыва.
Ловушка разветвления возникает когда две или больше связей типа 1:М разветвляются из одной сущности.
Ловушка разрыва может возникнуть при наличии связи с частичным участием. Например, одно отделение компании имеет много сотрудников, которые работают со сдаваемыми в аренду объектами. Однако не все сотрудники непосредственно работают с объектами, а также не все сдаваемые объекты находятся в ведении кого-либо из работников компании. В данном случае возникает проблема, если необходимо выяснить, какие объекты недвижимости приписаны к тому или иному отделению компании.
Функциональная зависимость
Функциональная зависимость описывает связь между отношениями: R(A,B) A->B.
Атрибут B функциональная зависимость от атрибута A, что означает, что каждое значение атрибута A связано только с одним значением атрибута B. При наличии функциональной зависимости атрибут или группа атрибутов, которые расположены слева от стрелки называются детерминантом.
Сотрудники_отделения:
Nсотр -> ФИО, Адрес, Должность, З/П, Nотд, Адрес_отд, Nтел_отд.
Nотд -> Адрес_отд, Nтел_отд.
Адрес_отд -> Nотд, Nтел_отд.
Nтел_отд -> Nотд, Адрес_отд.
Первичный ключ - Nотд, поскольку все остальные атрибуты функционально зависят от Nотд.
I НФ
Нормализация отношений выполняется на основе анализа первичных ключей и существования функциональных зависимостей между атрибутами. Как правило, нормализация выполняется в несколько этапов. Каждый этап соответствует определенной «Нормальной форме» (НФ). При проектировании реляционных БД требования 1-ой НФ должны выполняться всегда, остальные по желанию проектировщика. Однако, чтобы исключить аномалии обновления и избыточности данных рекомендуется приводить отношение к 3-ей НФ.
Ненормализованное отношение приводится к 1-ой НФ следующими способами:
- Выравнивание таблиц или добавление строк;
- Один атрибут или группа атрибутов, которые назначены ключом отношения повторяющейся группы помещается вместе с ключом в отдельные отношения. Во вновь созданных отношениях устанавливаются свои первичные ключи.
II НФ
2 - ая НФ – основывается на полной функциональной зависимости. Полная функциональная зависимость означает, что если атрибут B функционально зависит от некоторого значения атрибута A, то зависит от полного значения этого атрибута, а не какого-то его подмножества. Если имеет место полная функциональная зависимость между атрибутами A и B, то удаление какого-либо значения атрибута A приводит к полной потери этой зависимости. При частичной зависимости это сохраняется. 2-ая НФ применяется к отношениям с составными ключами. Считается, что отношение находится во 2-ой НФ, если оно удовлетворяет 1-ой НФ и каждый атрибут, который не входит в состав первичного ключа, функционально полно завит от первого ключа.
На этом этапе, если имеется частичная зависимость, они удаляются из отношения и помещаются в новое отношение вместе с копией их детерминанта.
Отношение «Клиент - аренда»
Первичный ключ: (N_клиента, N_объекта)
f1: N_клиента, N_объекта -> Нач_аренды, Кон_аренды
f2: N_клиента -> ФИО_клиента
f3: N_ объекта -> Адрес, Стоимость, N_владельца, ФИО_владельца
f4: N_клиента, Нач_аренды -> N_объекта, Адрес, Кон_аренды, Стоимость, N_владельца, ФИО_владельца
1 – для первичного ключа
2 – частичная
3 – частичная
4 – функциональная зависимость для потенциального ключа
Для того, что бы отношение преобразовать ко 2-ой НФ необходимо создать новое отношение и атрибуты, которые не входят в первичный ключ вместе с копией детерминанта поместить в новое отношение.
f2: Клиент (N_клиента, ФИО_клиента)
f1: Аренда (N_клиента, N_объекта, Нач_аренды, Кон_аренды)
f3: Владелец объектов (N_объекта, Адрес, Стоимость, N_владельца, ФИО_владельца)
III НФ
Если имеет место
 A->B
A->B
B->C
то говорят, что атрибут C транзитивно зависит от A через атрибут B, при условии, что атрибут A функционально не зависит ни от атрибута B, ни от атрибута C.
N_сотрудника -> N_отдела
N_отдела -> N_адреса_отдела
Отношение удовлетворяет 3-ей НФ, если оно находиться во 2-ой НФ, и не имеет атрибутов для входящих в первичный ключ, которые бы транзитивно зависли от этого ключа. Если в отношение существует транзитивная зависимость, то она исключается из отношения, образуя новое отношение, которое помещается в зависимые атрибуты в месте с копией детерминанта.
Объекты (N_объекта, Адрес, Стоимость, N_владельца)
Владельцы (N_владельца, ФИО_владельца)
Т.о. общую схему декомпозиции отношения «Клиент_Аренда» мы можем представить следующим образом:

Процесс нормализации отношения заключается в декомпозиции отношения посредством выполнения последовательных операций в проекции. Полученное отношение можно соединить без потерь и вернуться к исходному отношению. Текущую процедуру называют неаддитивной процедурой построения отношений.
НФБК
Однако бывает необходимость введения более сильных зависимостей – НФ Бойса-Кодда (НФ БК).
НФ БК учитывает все потенциальные ключи, которые входят в отношения. Если отношение имеет единственный потенциальный ключ, то 3-я НФ и НФ БК – эквивалентны. Считается, что отношение находящееся в НФ БК, если каждый его детерминант является потенциальным ключом. Что бы убедиться, что отношение находится в НФ БК необходимо отыскать все его детерминанты и убедиться, что они являются потенциальными ключами.
Клиенты, Объекты, Владельцы удовлетворяют НФ БК.
(N_клиента, N_объекта)
(N_клиента, Нач_аренды)
(N_объекта, Нач_аренды)
Нарушение требований НФ БК происходит:
1 – если имеются два или более составных ключа;
2 – если перекрывается потенциальный ключ, т.е. если какой-то атрибут входит в несколько ключей.
Рассмотрим отношение «Собеседование».
(N_клиента, Дата_собеседования)
(N_сотрудника, Дата_собеседования, Время_собеседования)
(N_комнаты, Время_собеседования, Дата_собеседования)
f1: N_клиента, Дата_собеседования - > Время_собеседования, N_сотрудника, N_комнаты
f2: N_сотрудника, Дата_собеседования, Время_собеседования -> N_клиента
f3: N_комнаты, Дата_собеседования, Время_собеседования -> N_сотрудника, N_клиента
f4: N_сотрудника, Дата_собеседования -> N_комнаты
Декомнозиция: Исходное отношение разбивается на два отношения:
- Собеседование1
- Место собеседования
Собеседование1(N_клиента, Дата_собеседования, Время_собеседования, N_сотрудника)
Место собеседования (N_сотрудника, Дата_собеседования, N_комнаты)
Обзор процесса нормализации
Процесс нормализации отношения заключается в преобразовании ненормализованных отношений к требуемому уровню НФ. Рассмотрим последовательно весь процесс нормализации до НФ БК.
Результаты проверки объектов недвижимости
| N_объекта
| Адрес
| Дата
| Время
| Комментарий
| N_сотрудника
| ФИО_сотредника
| N_маш
|
| 01
| Ленина 6-31
| 8,01,03
22,11,03
15,04,04
| 10:00
20:00
12:00
| Требуется ремонт
| 37
311
312
| Лис
Крот
Кот
| 03-12
07-11
21-13
|
| 02
| ……
| ……
| ……
| ……
| ……
| ……
| ……
|
Первый этап НФ – приведем к НФ. Для этого добавим новые строки. Определим потенциальные клюю отношения:
(N_объекта, Дата)
(N_сотрудника, Дата, Время)
(N_маш, Дата, Время)
Второй этап – приведение отношения ко 2-ой НФ. Для этого выписываются функциональные зависимости и устраняются частичные функциональные зависимости.
f1: N_объекта, Дата -> Время, Комментарий, N_сотрудника, ФИО_сотрудника, N_маш
f2: N_объекта -> Адрес
f3: N_сотрудника -> ФИО_сотрудника (транзитивная зависимость)
f4: N_сотрудника, Дата -> N_маш (частичная зависимость)
f5: N_маш, Дата, Время -> N_объекта, Адрес (для потенциальных ключей)
f6: N_сотрудника, Дата, Время -> N_объекта, Адрес, Комментарий.
Что бы привести отношение ко 2-ой НФ его необходимо будет разбить на три отношения:
Объект (N_объекта, Адрес)
Сотрудник (N_сотрудника, ФИО_сотрудника)
Проверка (N_объекта, Дата, Время, Комментарий, N_сотрудника, N_маш)
Полученное отношение удовлетворяет не только 2-ой НФ, но и 3-ей НФ.
Третий этап – проверка принадлежности отношений к НФ БК. Отношение «Объект» и «Сотрудник» удовлетворяют НФ БК. Отношение «Проверка» не удовлетворяет НФ БК, поскольку детерминант (N_сотрудника, Дата), который не является потенциальным ключом. Потому отношение «Проверка» может страдать аномалией обновления, т.е. при изменение данных об автомобиле придется вносить изменения сразу же в нескольких отношениях. Для этого отношение «Проверка» необходимо разбить на отношения:
Сотрудник – Машина
(N_сотрудника, N_маш, Дата)
Проверка – Дата
(N_объекта, Время, Комментарий, N_сотрудника)
Четвертый этап – отношение многозначных зависимостей, которые позволяют избавиться от избыточности.
Многозначные зависимости
В ходе проектирования БД выявлен один тип зависимости - многозначная зависимость. Многозначные зависимости выявляет проблемы и избыточностью данных.
Отделение – Сотрудник – Клиент
| N_отдела
| ФИО_сотрудника
| ФИО_клиента
|
| 011
| Кот
| Чижик
|
| 012
| Крот
| Лебедев
|
| 011
| Кот
| Гусев
|
| 012
| Крот
| Тупик
|
В данном отношении имеются многозначные зависимости типа один ко многим (1:N).
N_отдела – ФИО_клиента
N_отдела – ФИО_сотрудника
Если для каждого атрибута A имеется набор атрибутов B и C. Хотя атрибут B и C не зависят друг от друга.
Многозначная зависимость A -> B A -> C.
Многозначная зависимость подразделяется на тривиальную и нетривиальную зависимости. Многозначная зависимость A и B, определенных на некотором отношении R, называется тривиальной, если атрибут B является подмножеством атрибут A. В противном случае тривиальная зависимость является не тривиальной.
Для ликвидации многозначной зависимости необходимо привести отношения к 4НФ.
НФ
Отношение находится в 4-ой НФ, если оно удовлетворяет НФ БК и не содержит многозначных нетривиальных зависимостей.
Отделение – Сотрудник (N_отделения, ФИО_сотрудника)
Отделение – Клиент (N_отделения, ФИО_клиента)
Бывают случаи, когда необходимо выполнять декомпозицию на более чем два отношения. В этом случае необходимо учитывать зависимость соединения. Зависимость соединения - это свойство декомпозиции, которая вызывает генерацию ложных строк при обратном соединении декомпозированных отношений. Что бы не возникало зависимостей соединения, необходимо отношение приводить к 5-ой НФ.
НФ
Отношение в 5-ой НФ – это отношение без зависимостей соединения.
Например: Объект – Мебель – Поставщик
| N_объекта
| Мебель
| N_поставщика
|
| 31
| Стол
| P1
|
| 31
| Стул
| P2
|
| 52
| Стул
| P3
|
| 52
| Кровать
| P1
|
Для того, что бы отношение удовлетворяло 5-ой НФ, необходимо его разбить на следующие отношения:
Объект – Мебель (N_объекта, Мебель)
Поставщик – Мебель (N_поставщика, Мебель)
Объекта - Поставщик (N_объекта, N_поставщика)
ВОПРОС:
Генерализация – объединение сущностей в одну. Этот процесс присутствует редко.
Специализация - в примере мы на этапе концептуального проектирования выделили сущность секретарь (из сущности работник).
Управление транзакциями
Транзакция – это серия действий, которые выполняются одним пользователем или прикладной программой, и осуществляет изменения содержимого БД или доступ к данным.
Транзакция может быть представлена отдельной программой, частью какого либо алгоритма, либо отдельной программой (Insert, Update).
Чтобы разобраться с механизмом управления транзакций, рассмотрим пример:
Staff – сотрудник
Property for Rent – объекты недвижимости
Staff (sno, fname, lname, Adr, tel №, Position, Dop, Sex, salary. Nin, Pn)
Property for Rent (pno, Street, Area, City, Pcode, Type, Rooms, Ono, Sno, bno).
Необходимо сотруднику увеличить заработную плату.
Вариант А:
Read (sno=x, Salary)
Salary = Salary*1.1
Write (sno=x, view_ Salary)
Вариант В: (удаляется информация о сотруднике с заданным номером)
Delete (sno=x)
For all Property for Rent
Begin
Read (Pno=Pno, sno)
If (sno = x) then
Begin
Sno=new_sno
Write (pno=pno, sno)
End
End.
Если для транзакции для варианта А при выполнении изменений не все будут выполнены до конца БД по прежнему будут находиться в согласованном состоянии.
При выполнении транзакции В, если все указанные изменения будут выполнены до конца БД перейдет в несогласованное состояние, т.е. за объект недвижимости будет отвечать не существующий работник. Поэтому любая транзакция завершается одним из следующих возможных способов:
1. В случае успешного завершения транзакции результаты фиксируются в БД, и БД переходит в новое согласованное состояние;
2. Если транзакция не завершена либо произошло аварийное завершение, она отменяется и БД переходит в прежнее состояние. Этот процесс называется откат.
Зафиксированную транзакцию не возможно отменить, тогда надо выполнить другую транзакцию, которая отменит действие предыдущей. Этот процесс называется компенсирующей транзакцией.
Ни одна СУБД не в состоянии оценить какие действия могут быть восприняты как единое целое и образуют единую логическую транзакцию. Поэтому в большинстве языков для манипулирования данных используются специальные операторы, которые позволяет установить границы транзакции:
- BEGIN TRANSACTION
- COMMIT
- ROLL BACK
Если эти операторы не использовались, то вся выполняемая программа расценивается как единая транзакция и СУБД автоматически выполняет команду COMMIT – при успешном завершении, ROLL BACK – при аварийном завершении транзакции.
Любая транзакция должна обладать следующими свойствами:
1. Атомарность – это неделимая единица, которая может быть либо выполнена полностью, либо не выполнена совсем.
2. Согласованность, каждая транзакция должна переводить БД из одного согласованного состояния в другое согласованное состояние.
3. Изолированность, все транзакции выполняются независимо друг от друга и результаты независимой транзакции не должны быть доступны другим пользователям.
4. Продолжительность, результаты успешного завершения транзакции должны быть постоянны и не должны быть утеряны в процессе сбоя.
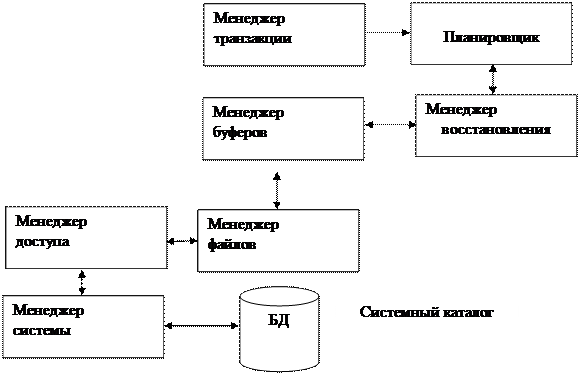
Рассмотрим подсистему обработки транзакции типичной СУБД.
Менеджер транзакций осуществляет координацию работы. Он взаимодействует с планировщиком, который отвечает за реализацию выбранной стратегии управления параллельностью, которая отвечает за реализацию выбранной стратегии. Его называют еще менеджер блокировок, если для управления параллельностью выбрана система блокировок.
Цель работы планировщика заключается в достижении максимальности управления параллельностью.
Задача менеджера восстановления является предоставления гарантий того, что БД будет возвращена в то состояние, в котором она находиться до начала транзакций.
Менеджер буфера отвечает за период данных между основной памятью компьютера и вторичной дисковой памятью.

Важный момент в управлении транзакций является управление параллельностью, т.е. управление процессом организации одновременно выполнение в БД различных операций и гарантии того, что будет исключаться их взаимное влияние друг на друга.
При параллельном выполнении транзакций могут возникнуть следющие проблемы:
1. Проблема потерянного обновления
2. Проблема обработки
3. Проблема зависимости от нефиксированных результатов.
Пример первой проблемы
| время
| Транзакция 1
| Транзакция 2
| Поле bals
|
| T1
|
| Begin transaction
| 100
|
| T2
| Begin transaction
| Read (bals)
| 100
|
| T3
| Read (bals)
| Bals=bals+100
| 100
|
| T4
| Bals=bals+100
| Write bals
| 200
|
| T5
| Write bals
| commit
| 90
|
| T6
| Commit
|
| 90
|
Пример второй проблемы
| время
| Транзакция 1
| Транзакция 2
| Поле bals
| Bals y
| Bals z
| sum
|
| T1
|
| Begin transaction
| 100
| 50
| 25
|
|
| T2
| Begin transaction
| Sum=0
| 100
| 50
| 25
|
|
| T3
| Read (bal x)
| Read (bals)
| 100
| 50
| 25
| 0
|
| T4
| Bals=bal x-10
| Sum=sum+ bal x
| 100
| 50
| 25
| 0
|
| T5
| Write bal x
| Read (bal y)
| 100
| 50
| 25
| 0
|
| T6
| Read (bal x)
| Sum=sum+ bal y
| 90
| 50
| 25
| 100
|
| T7
| Write bal y
|
| 90
| 50
| 25
| 150
|
| T8
| Balz=balz+10
|
| 90
| 50
| 25
| 150
|
| T9
| Write Balz
| Read (bal z)
| 90
| 50
| 25
| 150
|
| T10
| Commit
| Sum=sum+balz
| 90
| 50
| 25
| 185
|
| T11
|
| Commit
| 90
| 50
| 25
| 185
|
Пример третьей проблемы
| время
| Транзакция 1
| Транзакция 2
| Поле bal x
|
| T1
|
| Begin transaction
| 100
|
| T2
|
| Read bal x
| 100
|
| T3
|
| Bal x=bap x+100
| 100
|
| T4
| Begin transaction
| Write bal x
| 200
|
| T5
| Read bal x
|
|
|
| T6
| bal x= bal x-10
| Rall back
| 100
|
| T7
| Write bal x
|
| 190
|
| T8
| commit
|
| 190
|
Оптимизация запросов
Основные методы оптимизации основываются на статических показателях накапливаемых для БД (кардинальность отношений, степень отношений,наличие индексов, их число, размер блоков и др.)
Пример: необходимо определить имена всех менеджеров, которые работают в гродненском отделе компании.
SELECT *
FROM Staff, Branch b
WHERE s.bno=b.bno AND
(s.position= ‘Менеджер’ AND b.city= ‘Гродно’);
этот запрос можно представить в терминах реляционной алгебры в 3-х вариантах.
1. используем выборку:
σ(s.position=‘Менеджер’ Ù b.city= ‘Гродно’) ÙStaff.bno Branch.bno(Staff x Branch)
2. эквивалентный вариант:
σ position=‘Менеджер’ Ù b.city= ‘Гродно’
3. (Staff join Staff.bno=Branch.bno Branch);
(σ position=‘Менеджер’ (Staff)) join Staff.bno=Branch.bno
(σcity= ‘Гродно’ (Branch));
в таблице Staff – 1000 кортежей, в Branch – 50.
Предположим, что в таблице Staff 1000 кортежей, «Отделение» - 50.
5 из 50 менеджеров находятся в Гродно. Будем считать, что отношение не имеет индексов и никаких ключей сортировки. Сравнение будет производиться с точки зрения количества операции доступа к диску. Операция произведение потребуется 1000+50 операций для чтения исходных отношений. Затем потребуется 1000*50 операций, для того чтобы проверить заданное условие.
Общая стоимость этого захода будет:
(1000+50)+(1000+50)=1050+2*50000=101650
поэтому сколько операций понадобиться, чтобы считывать информацию с диска и результирующая таблица будет содержать 1000 кортежей.
1000+2*(1000+50)=3100
и 3-ий вариант идет вначале выборка 1000 операций. Результирующий набор будет состоять не более чем из 50 строк.
Branch – 50 операций.
Результирующая таблица будет состоять из 5 строк.
Для того чтобы сделать операцию соединения надо: 50+5 операций.
1000+2*50+5+50+5=1160 операций.
Наиболее оптимальный 3-ий вариант. Если будет больше число картежей, то будет больше разница между первым и третьим запросом.
При выполнения оптимизации запросов следует раньше всего выбирать унарные операции (проекция, выборка), которые сокращают число картежей, которые затем будет участвовать в бинарных операциях.
Общая схема оптимизации запроса можно представить следующим образом.

| Выражение реляционной алгебры
| |
| Фактическое
Выполнение
запроса
| |




Динамическая оптимизация выполнения при каждом вызове запроса статически предусматривает однократное выполнение.
Рассмотрим основные этапы выполнения запроса
48. Декомпозиция запросов.
Назначение: преобразование запроса на языки высокого уровня в выражение реляционной алгебры с последней проверкой его синтаксической и семантической корректности. Т.е. на этом этапе выполняется анализ, нормализация, семантический анализ, упрощение и реструктуризация запроса.
Анализ - проведение лексического и синтаксического анализа. Уточняется присутствуют ли все определения для указанных в запросе отношений и атрибутов.
Например:
SELECT Staff_no – такого поля нет
FROM Staff
WHERE position>10 – не соответствует тип
Затем строиться дерево запроса для каждого базового отношения создаются листовые узлы. Листовые создаются для каждого промежуточного отношения, которое является результатом выполнения некоторых операций реляционной алгебры. Корень дерева – результат. Результат выполняется от листовых узлов к корню дерева.
Пример:
SELECT *
FROM staff_s, branch_b
WHERE s.sno=b.bno
AND (s.position= ‘Менеджер’ AND b.city = ‘Гродно’)
Схема

Дерево запроса называется дерево реляционной алгебры.
Стадия нормализации выполняется с целью упрощения манипулирования данными. Здесь предикаты образуются в одну из 2-ух стандартных форм.
1. конъюнктивная. Это последовательность конъюнкции, связанных между собой операциями конъюнкции AND (Ù). Каждая конъюнкция может содержать один или более терма, соединенных операторами дизъюнкции OR (Ú). Например, (position = ‘инспектор’ Ú salary Ю 200000) Ù s.sno=b.bno
2. дизъюнкция. Это последовательность соединений, связанных между собой операциями дизъюнкции. Каждая дизъюнкция может содержать один или 2 терма, соединенных операторами конъюнкции. Пример, (position = ‘Менеджер’ Ù bno = BS) Ú (salary > 200000 bno=33).
Выборка, которая строиться на основе дизъюнктивных операторов будет содержать объединения тех картежей, которые удовлетворяют любым из входящих конъюнкций.
Семантический анализ проверяется нормализованные запросы, которые сформулированы не корректно, либо содержат противоречивые требования. Хапрос считается не корректным, если его выполнение не может привести к формированию набора результирующих данных. Например, условие:
Position = ‘ Инспектор’Ù Position = ‘Менеджер ’
Упрощение. Цель: выявление избыточной информации исключающая общие подвыражения и преобразования запроса в семантическую форму. Здесь рассматриваются вопросы существующих ограничений доступа, применяется во внимание требования поддержки целостности данных. И если пользователь не имеет необходимых прав доступа, то выполнение запроса отменяется.
Процедура упрощения использует правила эквивалентности реляционной алгебры.
Р Ù р = р
Р Ù false=false
P Ù (-p)=false
P Ù true =p
P Ú p=p
P Ú (-p)=true
P Ú false =p
P Ú true=true
Реструктуризация запроса запрос преобразуется в такую форму, которая позволяет обеспечить наиболее эффективное его выполение.
49. Правила преобразований операций реляционой алгебры
Для обеспечения наибольшей эффективности выполнения рестр запроса выполняется с помощью правил преобразования операций реляционной алгебры. Эти правила используются для реструктуризации дерева реляционной алгебры, которое строилось в процессе декомпозиции запроса. Правила:
1.Операция выборки с коньюктивным предикатом может быть преобразована в последовательносьт операций выборки по членам коньюнкции. Это каскадная выборка.
2.Правило коммутативности выбора
3.Правило коммутативности операций выборки и проекции
4.Правило коммутативности операций тетта – соединения и декартового произведения. Отношения могут меняться местами
5.Правило коммутативности операций выборки и тетта-соединения.
6.Правило коммутативности операций проекции и тетта-соед
7.Правило коммутативности операций объединение и пересечение
8.Правило коммутативности операций выборки и объединения, пересечения, разности.
9.Правило коммутативности операций проекции и объединения
10.Правило ассоциативности операций тетта соед и дек пр
11.Правило ассоциативности операций обединения и пересечения
12.В последовательности выполняются только опреции проекции
Основные стратегии эвристической обработки запроса
Во многих СУБД для выбора стратегии обработки запросов используются те
или иные эвристические правила.
1. Выполнение операций выборки на самых ранних этапах обработки. (Сокращается время обработки)
2. Объединение в одну операцию соединения операции декартова произведения и следующей за ней операции выборки, предикат которой представляет условие соединения.
3. Использование свойства ассоциативности бинарных операций для переупорядочения листовых узлов таким образом, что лист-узлы с наиболее ограничительными операциями выборки будут выполняться в первую очередь.
4. Как можно более раннее выполнение операций проекции.
5. Однократное вычисление общих выражений.
Концепция хранилищ данных
КХД базируется на усовершенствовании технологий БД и предусматривает специальные средства упрощенного процесса хранения хранения информации. Эта технология бази