

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...
Топ:
Марксистская теория происхождения государства: По мнению Маркса и Энгельса, в основе развития общества, происходящих в нем изменений лежит...
Организация стока поверхностных вод: Наибольшее количество влаги на земном шаре испаряется с поверхности морей и океанов...
Интересное:
Аура как энергетическое поле: многослойную ауру человека можно представить себе подобным...
Искусственное повышение поверхности территории: Варианты искусственного повышения поверхности территории необходимо выбирать на основе анализа следующих характеристик защищаемой территории...
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Описание и разновидности датчиков звука, как сделать своими руками
Датчик, реагирующий на наличие звука — чудо техники, предназначенное для упрощения жизни и экономии ваших денег. Что это такое, и как его сделать, можно детально изучить в этом материале.
Содержание [Показать]
·1 Введение
·2 Описание и назначение
·3 Конструкция и принцип действия
·4 Разновидности
·5 Сферы применения
·6 Как изготовить своими руками
o6.1 Простейшая схема
§6.1.1 Акустическое реле
§6.1.2 Триггер для управления освещением
o6.2 Схема на трех транзисторах
o6.3 С использованием микросхем
§6.3.1 Что же нам это дает?
o6.4 Увеличение
o6.5 Использование датчиков звука в режиме шума
·7 Преимущества и недостатки
Введение
Датчики звука появились достаточно недавно, их основная функция – это включение света. В основном их используют в помещениях, где не всегда удобно или не стерильно искать выключатель. Это могут быть как больницы – где по правилам асептики небезопасно касаться сторонних предметов, так подъезды и жилые дома, тем самым экономя электроэнергию и время на поиски выключателя.
Описание и назначение
Датчики звука появились в начале 90-х годов и использовались в системах безопасности. Изначально они прославились низкой чувствительностью и ложными срабатываниями. Современные модели исправили эти недостатки и теперь они очень чувствительные и срабатывают только в подходящий момент.
Нынешние датчики владеют возможностью распознавать звук на основе записанного в него эталона, который записан в само устройство. Простые датчики не могут анализировать и реагируют на любой шум, чуть дороже – на хлопок, а лучшие образцы запрограммированы на огромное количество команд, поэтому стоят намного дороже.
|
|
Назначение это чудо техники получило в осветительных приборах, выполняя функцию включения и выключения света, когда приближается человек и образуется шум, то свет включается через 1-2 секунды, когда звук пропадает, проходит 15-0 секунду и происходит выключение света. Их используют в подъездах, жилых комплексах, больницах, туалетах. Они являются отличным выходом для семей, где есть дети. Очень часто, ребенок боится темноты, а такой датчик сможет решить проблему темных коридоров и страхов детей.

Разновидности
В наше время, датчики делятся на три типа:

Сферы применения
Звуковой датчик применяют в подъезд, что удобно в темное время суток, для людей которые возвращаются с работы. В больницах по причине стерильности, не очень удобно хирургу, который следует на операцию включать в коридоре или в любом другом месте свет. Последнее время, эти устройства широко используются в системах “умный дом”. В помещениях, жилых комплексах для людей с ограниченными возможностями.
Также на складах, где нет возможности включить сет, по причине занятости рук другими предметами и различных предприятиях, в последних принято использовать функцию “Хлопка”. И, конечно, в жилых домах, куда люди практически не заходят, к ним относятся кладовые, чердаки и подвалы, из-за их расположения и кромешной темноты, поиски выключателя могут закончится травмой.
|
|

Простейшая схема
Самая простая схема состоит из акустического реле в количестве двух штук и триггера.
Акустическое реле
Проще этой схемы вы не сможете найти, ведь это реле собрано на одном транзисторе.
<span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"></span>
Выбор пал на МП 39 – это довольно старый германиевый транзистор. Их, обычно, полно в древней технике прошлого века. Микрофон мы тоже берем со старого телефона – это обычный угольный микрофон. Их можно достать из старого телефона, где номера набираются диском. Этот радиомикрофон обладает повышенной очень чувствительный наделен минимальной частотой диапазанного пропуска. Последнее уменьшает вероятность срабатывания от обычных шумов.
Принципы работы данной схемы:
Схему можно собрать по разному, например на печатной или макетной плате и используют блок питания, вольтаж которого равняется 9-12 единицам.

Схема на трех транзисторах
Давайте посмотрим на схему посложнее. Которая может работать сама и включать свет по первому звуку, а по второму выключать.
Посмотрев на эту схему, мы видим транзисторы KT315 и KT818 – они продаются в любом спец магазине.
Чувствительность этого чуда техники, при питании 9B – является 2 метра. Соответственно, если увеличивать напряжение – то увеличиваем и восприимчивость, если уменьшать – ну, вы поняли.
|
|
Микрофон берем электродинамический. Вольтаж, которое должно выдержать реле равняется 220 единицам, не забываем и про проходимый ток.
Если хотите запитать акустическое реле нужно взять блок питания. В данном случае подойдет абсолютно любой с диапазоном 9-15B. Реле собирается на макетной или печатной плате.
С использованием микросхем
Более сложный, но очень интересный вариант. В нем используется микросхема. А чем именно он интересен – так это тем, что в не нужно дополнительно устанавливать блок для питания, так-как он уже есть в нем. И еще одно отличие – здесь стоит тиристор взамен электромагнитного реле.
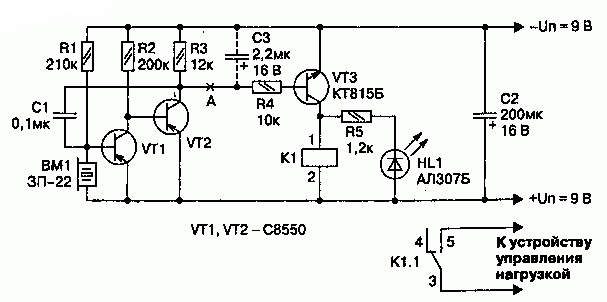
Что же нам это дает?
Реле имеет ограниченное количество срабатываний, а тиристор – нет. Так же тиристор уменьшает габариты устройства, что тоже идет нам на руку. Аппарат что представлен ниже, имеет чувствительность 6 метров и работает с лампами 60-70 Вт, и конечно – защиту от помех.
Увеличение
Как вы могли заметить выше, что реле рассчитано на ограниченную нагрузку в размере 60-70 Вт. Для обычного освещения в подъезде или туалете этого вполне достаточно. Но в некоторых случаях, этого будет мало, тогда диоды VD2-VD5 и тиристор VS1 – закрепляют на радиаторы, чтобы те уменьшали их нагрев.
Места, где соприкасаются радиатор с другими деталями, должны быть хорошо отшлифованными. Это позволит получить нужный контакт. В этом случае теплопроводная паста будет вашим спасением от перегрева.
Преимущества и недостатки
Все в нашем мире имеет свои плюсы и минусы, и датчики имеют свои преимущества и недостатки. К положительным качествам можно отнести:
Также свет выключается не сразу, а через определенный промежуток времени. Это позволяет пройти нужные комнаты и не оказаться в полной темноте.
Но и недостатки у этого устройства тоже есть. К ним относится невозможность монтажа в шумных местах и постоянные срабатывания дешевых моделей. Поэтому, китайские бюджетные датчики не рекомендуется использовать
|
|
Тема распознавания голоса микроконтроллером довольно интересна и нова, поэтому я решил представить вам схему устройства распознавания голоса на микроконтроллере, а точнее на Arduino. Распознавание голоса довольно непростая задача, а реализовать это на микроконтроллере еще сложнее, в силу ограниченности его ресурсов. В нашем случае реализация распознавания голоса будет на микроконтроллере ATmega328P, работающего на частоте 16МГц.
 <img class=" size-full wp- В данном устройстве была использована библиотека uSpeech, которая полностью автономна и не требует передачи голосовых команд на компьютер для дальнейшего распознавания, как того требуют другие библиотеки и модули, например, такие как BitVoicer.
<img class=" size-full wp- В данном устройстве была использована библиотека uSpeech, которая полностью автономна и не требует передачи голосовых команд на компьютер для дальнейшего распознавания, как того требуют другие библиотеки и модули, например, такие как BitVoicer.
В моей схеме распознавания голоса на микроконтроллере была использована uSpeech в силу своей автономности и малых размеров. Хотя у неё есть недостаток, такой как ограниченность распознавания. Эта библиотека позволяет распознавать только фонемы, т.е. отдельные звуки, но для многих схем и устройств этого более чем достаточно. Ниже приведен список используемых фонем (звуков):
| Фонема (звук) | Соответствующая ей буква (может быть несколько) |
| “е” | е |
| “х” | х, ш, щ, дж, ж, з |
| “в” | в, может срабатывать на з |
| “ф” | ф |
| “с” | с |
| “о” | о, а, ш, л, м, н, у, ю |
| ” “ | слишком тихий звук |
В качестве микрофона используется электретный микрофон (ссылка на статью на Wikipedia), обычно он выглядит так:
<img class=" size-full wp-image-566" src="https://radioded.ru/wp-content/uploads/2017/03/microphone.jpg" alt="Электретный микрофон" height="319" srcset="https://radioded.ru/wp-content/uploads/2017/03/microphone.jpg 425w, https://radioded.ru/wp-content/uploads/2017/03/microphone-300x225.jpg 300w" sizes="(max-width: 425px) 100vw, 425px" />
Сигнал с него достаточно слабый, поэтому его необходимо усилить. Усилитель для микрофона можно сделать из пары транзисторов, как было в схеме микрофонного усилителя на Радиодеде, так и на операционном усилителе, например, так:
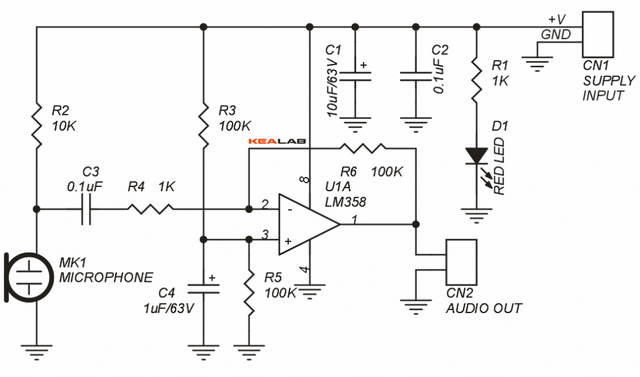 <img class=" size-full wp-image-567" src="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier_lm358.png" alt="Микрофонный усилитель на операционном усилителе (ОУ) LM358" height="377" srcset="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier_lm358.png 640w, https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier_lm358-300x177.png 300w" sizes="(max-width: 640px) 100vw, 640px" />
<img class=" size-full wp-image-567" src="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier_lm358.png" alt="Микрофонный усилитель на операционном усилителе (ОУ) LM358" height="377" srcset="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier_lm358.png 640w, https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier_lm358-300x177.png 300w" sizes="(max-width: 640px) 100vw, 640px" />
Либо можно купить готовый микрофон с усилителем на eBay или AliExpress, найти можно по запросу «Mic amplifier arduino» или «Микрофонный усилитель Arduino». Выглядит он так:
 <img class=" wp-image-568" src="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier.jpg" alt="Микрофонный усилитель (готовый модуль)" height="319" srcset="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier.jpg 538w, https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier-150x150.jpg 150w, https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier-300x300.jpg 300w" sizes="(max-width: 319px) 100vw, 319px" />
<img class=" wp-image-568" src="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier.jpg" alt="Микрофонный усилитель (готовый модуль)" height="319" srcset="https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier.jpg 538w, https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier-150x150.jpg 150w, https://radioded.ru/wp-content/uploads/2017/03/mic_amplifier-300x300.jpg 300w" sizes="(max-width: 319px) 100vw, 319px" />
|
|
Микрофон с микрофонным усилителем желательно подключить к микроконтроллеру через резистор 470…2К и разделительный конденсатор (он уже есть в самих схемах усилителей, а также на готовых платах), который убирает постоянную составляющую.
Схема подключения микрофона и усилителя к Arduino следующая: микрофон через усилитель подключается к аналоговому порту Ардуино A0, три светодиода через резисторы подключаются к цифровым выходам 5,6,7 (схему можно изменить, внеся соответствующие, небольшие правки в исходный код программы).
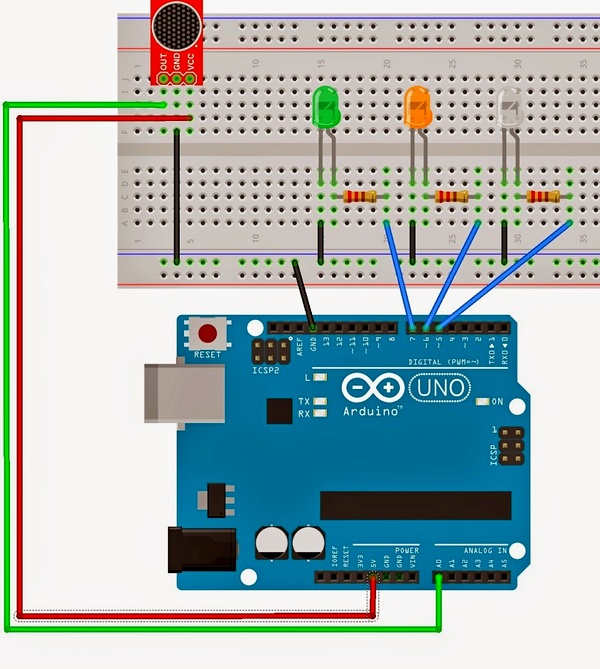 <img class=" size-full wp-image-569" src="https://radioded.ru/wp-content/uploads/2017/03/voice-recognition_arduino_scheme.jpg" alt="Схема подключения микрофона к Arduino для распознавания голоса" height="669" srcset="https://radioded.ru/wp-content/uploads/2017/03/voice-recognition_arduino_scheme.jpg 600w, https://radioded.ru/wp-content/uploads/2017/03/voice-recognition_arduino_scheme-269x300.jpg 269w" sizes="(max-width: 600px) 100vw, 600px" />
<img class=" size-full wp-image-569" src="https://radioded.ru/wp-content/uploads/2017/03/voice-recognition_arduino_scheme.jpg" alt="Схема подключения микрофона к Arduino для распознавания голоса" height="669" srcset="https://radioded.ru/wp-content/uploads/2017/03/voice-recognition_arduino_scheme.jpg 600w, https://radioded.ru/wp-content/uploads/2017/03/voice-recognition_arduino_scheme-269x300.jpg 269w" sizes="(max-width: 600px) 100vw, 600px" />
В качестве индикаторов распознанных команд были использованы три светодиода разных цветов.
В исходном примере библиотеки uSpeech сравнивались одиночные фонемы (звуки). Пример позволял распознать 6 фонем (звуков): «ф», «е», «о», «в», «с», «х» (f, e, o, v, s, h). Мной был использован массив байт, который содержал паттерны, распознаваемых слов, что позволило в конечном итоге распознавать не отдельные фонемы (звуки), а целые слова, состоящие из распознаваемых фонем. Массив полученных звуков сравнивается с заранее прописанным массивом байт (паттерном слова), и в случае совпадения, с учетом заданного порога чувствительности, делается вывод о том, какое слово было произнесено.
Например, заранее прописанные паттерны для английских слов green,orange и white были следующие “vvvoeeeeeeeofff”, “hhhhhvoovvvvf”, “hooooooffffffff”. Для нахождения наиболее ближайшего эквивалента произносимом слову необходимо находить минимальное редакционное расстояние (расстояние Левенштейна). Для повышения точности и игнорирования нерелевантных паттернов при распозновании использовалась константа LOWEST_COST_MAX_THREASHOLD, определяющая уровень достоверности. Подбирая её значение можно добиться высокой точности распознавания.
Скомпилированный скетч занимает около 20% FLASH-памяти микроконтроллера и около 500 байт, т.е. 25% ОЗУ. Библиотеку для распознавания голосовых команд на Ардуино – uSpeech можно скачать здесь (необходимо нажать зеленую кнопку “Clone or download”). Установка библиотеки стандартная – необходимо распаковать архив и поместить папку в “C:/Users/<Имя пользователя>/Documents/Arduino/libraries”
Было бы здорово просто включить вентиляторы и свет в доме, просто хлопнув в ладоши, вместо того, чтобы идти переключателю. Но такое устройство часто будет работать со сбоями, так как эта схема будет реагировать на любые громкие шумы в окружающей среде, такие как громкое радио или газонокосилка во дворе.

Но можно использовать более редкий вид звука, например, свист. Свист в отличие от других звуков будет иметь одинаковую частоту для определенной продолжительности и, следовательно, может отличаться от речи или музыки. Таким образом, в этом примере мы узнаем, как определять звук свистка, при этом связав датчик звука с Arduino, и, когда свист будет обнаружен, мы будем переключать лампу переменного тока через реле. Также мы также узнаем, как звуковые сигналы принимаются микрофоном и как измерять частоту с помощью Arduino. Звучит интересно, так что давайте начнем с основанного на Arduino проекта домашней автоматизации.
Прежде чем мы углубимся в аппаратное обеспечение и код для этого проекта домашней автоматизации, давайте взглянем на звуковой датчик. Звуковой датчик, используемый в этом модуле, показан далее. Принцип работы большинства доступных на рынке звуковых датчиков аналогичен этому, хотя внешний вид может немного отличаться.

Как известно, примитивным компонентом в звуковом датчике является микрофон. Микрофон – это тип преобразователя, который преобразует звуковые волны (акустическую энергию) в электрическую энергию. В основном диафрагма внутри микрофона вибрирует на звуковые волны в атмосфере, которая производит электрический сигнал на своем выходном выводе. Но эти сигналы будут иметь очень низкую величину (мВ) и, следовательно, не могут быть обработаны напрямую микроконтроллером, таким как Arduino. Также по умолчанию звуковые сигналы являются аналоговыми по природе, следовательно, выходной сигнал от микрофона будет синусоидальным с переменной частотой, но микроконтроллеры являются цифровыми устройствами и, следовательно, лучше работают с прямоугольными сигналами.
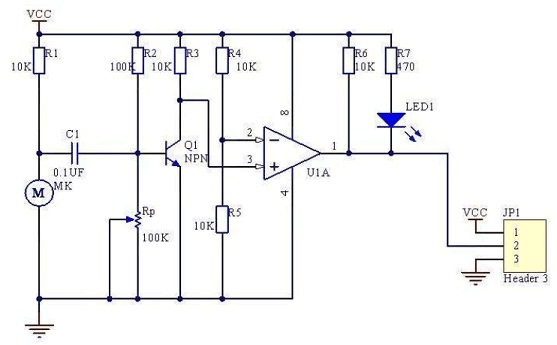
Для усиления этих синусоидальных сигналов с низким уровнем напряжения и преобразования их в прямоугольные сигналы модуль использует встроенный компаратор LM393, как показано выше. Выход низкого напряжения аудио от микрофона подается на один из контактов разъема компаратора через усилитель транзистор, а опорное напряжение устанавливается на другом выводе, используя схему делителя напряжения с участием потенциометра. Когда выходное напряжение звука с микрофона превышает заданное напряжение, напряжение компаратора поднимается до 5 В (рабочее напряжение), в противном случае напряжение компаратора остается низким при 0 В. Таким образом, синусоидальная волна низкого сигнала может быть преобразована в прямоугольный сигнал высокого напряжения (5 В). Осциллограмма ниже показывает то же самое, где желтая волна представляет синусоидальную волну слабого сигнала, а синяя – выходной прямоугольный сигнал. Чувствительность можно контролировать, изменяя сопротивление потенциометра на модуле.
Этот модуль звукового датчика преобразует звуковые волны в атмосфере в прямоугольные сигналы, частота которых будет равна частоте звуковых волн. Таким образом, измеряя частоту прямоугольного сигнала, мы можем найти частоту звуковых сигналов в атмосфере.
Полная принципиальная схема цепи переключателя на основе детектора свиста с Arduino с использованием звукового датчика показана ниже.
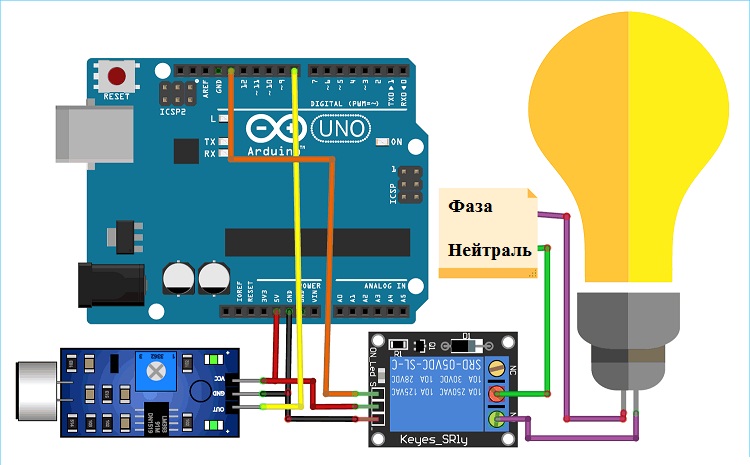
Датчик звука и релейный модуль питаются от 5-вольтового контакта Arduino. Выходной вывод датчика звука подключен к цифровому выводу 8 Arduino, это связано со свойством таймера этого вывода. Модуль реле запускается контактом 13, который также подключен к встроенному светодиоду на плате Arduino UNO.
На стороне источника переменного тока нейтральный провод напрямую подключен к общему (C) выводу модуля реле, а фаза подключена к нормально разомкнутому (NO) выводу реле через нагрузку переменного тока (лампочка). Таким образом, при срабатывании реле контакт NO будет соединен с контактом C и, таким образом, лампочка будет светиться. В противном случае лампа останется выключенной. Все это может выглядеть следующим образом.

Помните, что работа с цепью переменного тока может быть опасной, будьте осторожны при работе с проводами под напряжением и избегайте коротких замыканий. Людям, не имеющим опыта работы с электроникой, рекомендуется использовать автоматический выключатель или помощь других более опытных людей.
Подобно тому, как мы считываем частоту входящих прямоугольных сигналов, мы должны запрограммировать Arduino для вычисления частоты. В этом уроке мы будем использовать библиотеку Freqmeasure (https://github.com/PaulStoffregen/FreqMeasure/archive/master.zip) для измерения частоты, чтобы получить точные результаты. Эта библиотека использует прерывание внутреннего таймера на выводе 8, чтобы измерить, как долго импульс остается включенным. Как только время измерено, мы можем вычислить частоту, используя формулу F = 1 / T. Однако, поскольку мы используем библиотеку напрямую, нам не нужно вдаваться в подробности регистров и математических данных о том, как измеряется частота. Следует заметить, что использование библиотеки отключит функцию analogWrite на контактах 9 и 10 на Arduino UNO, поскольку таймер будет занят этой библиотекой.
Полный код программы коммутатора на основе детектора свиста довольно прост и представлен далее.
#include <FreqMeasure.h> //https://github.com/PaulStoffregen/FreqMeasure
void setup() {
Serial.begin(9600);
FreqMeasure.begin(); // Измерение на контакте 8 по умолчанию
pinMode(LED_BUILTIN, OUTPUT);
}
double sum=0;
int count=0;
bool state = false;
float frequency;
int continuity =0;
void loop() {
if (FreqMeasure.available()) {
// усреднение считываний
Сверхбыстрое распознавание речи без серверов на реальном примере
В этой статье я подробно расскажу и покажу, как правильно и быстро прикрутить распознавание русской речи на движке Pocketsphinx (для iOS порт OpenEars) на реальном Hello World примере управления домашней техникой.
Почему именно домашней техникой? Да потому что благодаря такому примеру можно оценить ту скорость и точность, которой можно добиться при использовании полностью локального распознавания речи без серверов типа Google ASR или Яндекс SpeechKit.
К статье я также прилагаю все исходники программы и саму сборку под Android.
С чего вдруг?
Наткнувшись недавно на статью о прикручивании Яндекс SpeechKit-а к iOS приложению, я задал вопрос автору, почему для своей программы он захотел использовать именно серверное распознавание речи (по моему мнению, это было излишним и приводило к некоторым проблемам). На что получил встречный вопрос о том, не мог бы я поподробней описать применение альтернативных способов для проектов, где нет необходимости распознавать что угодно, а словарь состоит из конечного набора слов. Да еще и с примером практического применения…
Примечание
Сразу оговорюсь, что эти преимущества можно считать преимуществами только для определенного класса проектов, где мы точно заранее знаем, каким словарем и какой грамматикой будет оперировать пользователь. То есть, когда нам не надо распознать произвольный текст (например, СМС сообщение, либо поисковый запрос). В обратном случае без облачного распознавания не обойтись.
Так Android же умеет распознавать речь без интернета!
Да-да… Только на JellyBean. И только с полуметра, не более. И это распознавание — это та же диктовка, только с использованием гораздо меньшей модели. Так что управлять ею и настраивать ее мы тоже не можем. И что она вернет нам в следующий раз — неизвестно. Хотя для СМС-ок в самый раз!
Что будем делать?

Будем реализовывать голосовой пульт управления домашней техникой, который будет работать точно и быстро, с нескольких метров и даже на дешевом тормозном хламе очень недорогих Android смартфонах, планшетах и часах.
Логика будет простой, но очень практичной. Активируем микрофон и произносим одно или несколько названий устройств. Приложение их распознает и включает-выключает их в зависимости от текущего состояния. Либо получает от них состояние и произносит его приятным женским голосом. Например, текущая температура в комнате.
Микрофон будем активировать или голосом, или нажатием на иконку микрофона, или даже просто положив руку на экран. Экран в свою очередь может быть и полностью выключенным.
Вариантов практического применения масса
Утром, не открывая глаз, хлопнули ладонью по экрану смартфона на тумбочке и командуем «Доброе утро!» — запускается скрипт, включается и жужжит кофеварка, раздается приятная музыка, раздвигаются шторы.
Повесим по дешевому (тысячи по 2, не более) смартфону в каждой комнате на стенке. Заходим домой после работы и командуем в пустоту «Умный дом! Свет, телевизор!» — что происходит дальше, думаю, говорить не надо.
На видео показано, что получилось в итоге. Далее же речь пойдет о технической реализации с выдержками из реально работающего кода и немного теории.
Что такое Pocketsphinx
Pocketsphinx — это движок распознавания с открытым исходным кодом под Android. У него также имеется порт под iOS, WindowsPhone, и даже JavaScript.
Он позволит нам запустить распознавание речи прямо на устройстве и при этом настроить его именно под наши задачи. Также он предлагает функцию голосовой активации «из коробки» (см далее).
Мы сможем «скормить» движку распознавания русскую языковую модель (вы можете найти ее в исходниках) и грамматику пользовательских запросов. Это именно то, что будет распознавать наше приложение. Ничего другого оно распознать не сможет. А следовательно, практически никогда не выдаст что-то, чего мы не ожидаем.
Грамматика JSGF
Формат грамматики JSGF используется Pocketsphinx, как и многими другими подобными проектами. В нем можно с достаточной гибкостью описать те варианты фраз, которые будет произносить пользователь. В нашем случае грамматика будет строиться из названий устройств, которые есть в нашей сети, примерно так:
<commands> = лапма | монитор | температура;
Pocketsphinx также может работать по статистической модели языка, что позволяет распознавать спонтанную речь, не описываемую контекстно-свободной грамматикой. Но для нашей задачи это как раз не нужно. Наша грамматика будет состоять только из названий устройств. После процесса распознавания Pocketsphinx вернет нам обычную строчку текста, где устройства будут идти один за другим.
#JSGF V1.0;grammar commands;public <command> = <commands>+;<commands> = лапма | монитор | температура;
Знак плюса обозначает, что пользователь может назвать не одно, а несколько устройств подряд.
Приложение получает список устройств от контроллера умного дома (см далее) и формирует такую грамматику в классе Grammar.
Транскрипции

Грамматика описывает то, что может говорить пользователь. Для того, чтобы Pocketsphinx знал, как он это будет произносить, необходимо для каждого слова из грамматики написать, как оно звучит в соответствующей языковой модели. То есть транскрипцию каждого слова. Это называется словарь.
Транскрипции описываются с помощью специального синтаксиса. Например:
умный uu m n ay jдом d oo m
В принципе, ничего сложного. Двойная гласная в транскрипции обозначает ударение. Двойная согласная — мягкую согласную, за которой идет гласная. Все возможные комбинации для всех звуков русского языка можно найти в самой языковой модели.
Понятно, что заранее описать все транскрипции в нашем приложении мы не можем, потому что мы не знаем заранее тех названий, которые пользователь даст своим устройствам. Поэтому мы будем гененрировать «на лету» такие транскрипции по некоторым правилам русской фонетики. Для этого можно реализовать вот такой класс PhonMapper, который сможет получать на вход строчку и генерировать для нее правильную транскрипцию.
Голосовая активация
Это возможность движка распознавания речи все время «слушать эфир» с целью реакции на заранее заданную фразу (или фразы). При этом все другие звуки и речь будут отбрасываться. Это не то же самое, что описать грамматику и просто включить микрофон. Приводить здесь теорию этой задачи и механику того, как это работает, я не буду. Скажу лишь только, что недавно программисты, работающие над Pocketsphinx, реализовали такую функцию, и теперь она доступна «из коробки» в API.
Одно стоит упомянуть обязательно. Для активационной фразы нужно не только указать транскрипцию, но и подобрать подходящее значение порога чувствительности. Слишком маленькое значение приведет к множеству ложных срабатываний (это когда вы не говорили активационную фразу, а система ее распознает). А слишком высокое — к невосприимчивости. Поэтому данная настройка имеет особую важность. Примерный диапазон значений — от 1e-1 до 1e-40 в зависимости от активационной фразы.
Запускаем распознование
Pocketsphinx предоставляет удобный API для конфигурирования и запуска процесса распознавания. Это классы SppechRecognizer и SpeechRecognizerSetup.
Вот как выглядит конфигурация и запуск распознавания:
Здесь мы сперва копируем все необходимые файлы на диск (Pocketpshinx требует наличия на диске аккустической модели, грамматики и словаря с транскрипциями). Затем конфигурируется сам движок распознавания. Указываются пути к файлам модели и словаря, а также некоторые параметры (порог чувствительности для активационной фразы). Далее конфигурируется путь к файлу с грамматикой, а также активационная фраза.
Как видно из этого кода, один движок конфигурируется сразу и для грамматики, и для распознавания активационной фразы. Зачем так делается? Для того, чтобы мы могли быстро переключаться между тем, что в данный момент нужно распознавать. Вот как выглядит запуск процесса распознавания активационной фразы:
mRecognizer.startListening(KWS_SEARCH);
А вот так — распозанвание речи по заданной грамматике:
Второй аргумент (необязательный) — количество миллисекунд, после которого распознавание будет автоматически завершаться, если никто ничего не говорит.
Как видите, можно использовать только один движок для решения обеих задач.
Как синтезировать речь
Синтез речи — это операция, обратная распознаванию. Здесь наоборот — нужно превратить строку текста в речь, чтобы ее услышал пользователь.
В случае с термостатом мы должны заставить наше Android устройство произнести текущую температуру. С помощью API TextToSpeech это сделать довольно просто (спасибо гуглу за прекрасный женский TTS для русского языка):
Скажу наверное банальность, но перед процессом синтеза нужно обязательно отключить распознавание. На некоторых устройствах (например, все самсунги) вообще невозсожно одновременно и слушать микрофон, и что-то синтезировать.
Окончание синтеза речи (то есть окончание процесса говорения текста синтезатором) можно отследить в слушателе:
В нем мы просто проверяем, нет ли еще чего-то в очереди на синтез, и включаем распозанвание активационной фразы, если ничего больше нет.
И это все?
Да! Как видите, быстро и качественно распознать речь прямо на устройстве совсем несложно, благодаря наличию таких замечательных проектов, как Pocketsphinx. Он предоставляет очень удобный API, который можно использовать в решении задач, связанных с распознаванием голосовых команд.
В данном примере мы прикрутили распознавание к вполне кокрентной задаче — голосовому управлению устройствами умного дома. За счет локального распознавания мы добились очень высокой скорости работы и минимизировали ошибки.
Понятно, что тот же код можно использовать и для других задач, связанных с голосом. Это не обязательно должен быть именно умный дом.
Все исходники, а также саму сборку приложения вы можете найти в репозитории на GitHub.
Также на моем канале в YouTube вы можете увидеть некоторые другие реализации голосового управления, и не только системами умных домов.
Теги:
Описание и разновидности датчиков звука, как сделать своими руками
Датчик, реагирующий на наличие звука — чудо техники, предназначенное для упрощения жизни и экономии ваших денег. Что это такое, и как его сделать, можно детально изучить в этом материале.
Содержание [Показать]
·1 Введение
·2 Описание и назначение
·3 Конструкция и принцип действия
·4 Разновидности
·5 Сферы применения
·6 Как изготовить своими руками
o6.1 Простейшая схема
§6.1.1 Акустическое реле
§6.1.2 Триггер для управления освещением
o6.2 Схема на трех транзисторах
o6.3 С использованием микросхем
§6.3.1 Что же нам это дает?
o6.4 Увеличение
o6.5 Использование датчиков звука в режиме шума
·7 Преимущества и недостатки
Введение
Датчики звука появились достаточно недавно, их основная функция – это включение света. В основном их используют в помещениях, где не всегда удобно или не стерильно искать выключатель. Это могут быть как больницы – где по правилам асептики небезопасно касаться сторонних предметов, так подъезды и жилые дома, тем самым экономя электроэнергию и время на поиски выключателя.
Описание и назначение
Датчики звука появились в начале 90-х годов и использовались в системах безопасности. Изначально они прославились низкой чувствительностью и ложными срабатываниями. Современные модели исправили эти недостатки и теперь они очень чувствительные и срабатывают только в подходящий момент.
Нынешние датчики владеют возможностью распознавать звук на основе записанного в него эталона, который записан в само устройство. Простые датчики не могут анализировать и реагируют на любой шум, чуть дороже – на хлопок, а лучшие образцы запрограммированы на огромное количество команд, поэтому стоят намного дороже.
Назначение это чудо техники получило в осветительных приборах, выполняя функцию включения и выключения света, когда приближается человек и образуется шум, то свет включается через 1-2 секунды, когда звук пропадает, проходит 15-0 секунду и происходит выключение света. Их используют в подъездах, жилых комплексах, больницах, туалетах. Они являются отличным выходом для семей, где есть дети. Очень часто, ребенок боится темноты, а такой датчик сможет решить проблему темных коридоров и страхов детей.
|
|
|

История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...

Автоматическое растормаживание колес: Тормозные устройства колес предназначены для уменьшения длины пробега и улучшения маневрирования ВС при...

Таксономические единицы (категории) растений: Каждая система классификации состоит из определённых соподчиненных друг другу...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!