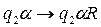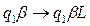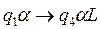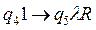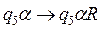Кратко: Неудовлетворённая потребность – анализ и постановка её цели, внешнее специфицирование, выпуск новых версий с исправлением багов, прекращение эксплуатации.
Жизненный цикл — это период времени, с момента принятия решения о создании ПП и заканчивается в момент его полного изъятия из эксплуатации. Этот цикл — процесс построения и развития ПО.
Модели Жизненного цикла программного обеспечения:
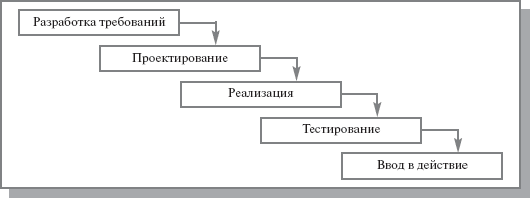
1) Каскадная модель (англ. waterfall model)
Каждый последующий шаг начинается после полного завершения выполнения предыдущего шага
Жизненный цикл традиционно разделяют на следующие основные этапы:
a) Анализ требований,
b) Проектирование,
c) Кодирование (программирование),
d) Тестирование и отладка,
e) Эксплуатация и сопровождение.
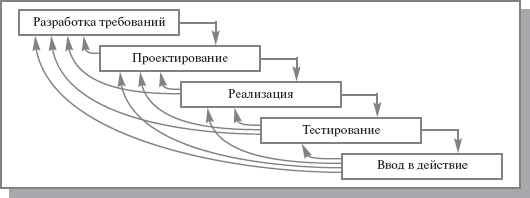
2) Инкрементная модель (англ. increment — увеличение, приращение)
Разработка ПО ведется итерациями с циклами обратной связи между этапами. Время жизни каждого из этапов растягивается на весь период разработки.
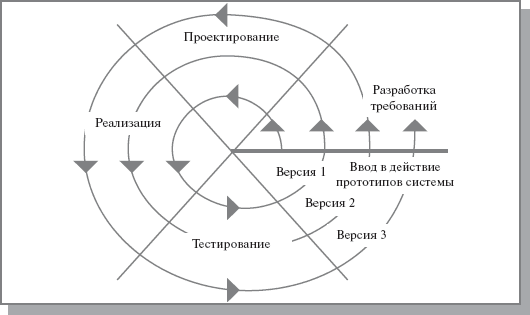
3) Спиральная модель.
На каждом витке спирали выполняется создание очередной версии продукта, уточняются требования проекта, определяется его качество и планируются работы следующего витка. Особое внимание уделяется начальным этапам разработки — анализу и проектированию.
Определение графов
Граф – это совокупность двух конечных множеств: точек и линий, попарно соединяющих некоторые из этих точек. Множество точек называется вершинами(узлами) графа. Множество линий, соединяющих вершины графа, называются ребрами(дугами) графа.
Ориентированный граф (орграф) – граф, у которого все ребра ориентированы, т.е. ребрам которого присвоено направление.
Неориентированный граф (неорграф) – граф, у которого все ребра не ориентированы, т.е. ребрам которого не задано направление.
Смешанный граф – граф, содержащий и ориентированные и неориентированные ребра.
Петлей называется ребро, соединяющее вершину саму с собой. Две вершины называются смежными, если существует соединяющее их ребро.
Простой граф – это граф, в котором нет ни петель, ни кратных ребер.
Мультиграф – это граф, у которого любые две вершины соединены более чем одним ребром.
Маршрутом в графе называется конечная чередующаяся последовательность смежных вершин и ребер, соединяющих эти вершины.
Маршрут называется открытым, если его начальная и конечная вершины различны, в противном случае он называется замкнутым.
Маршрут называется цепью, если все его ребра различны. Открытая цепь называется путем, если все ее вершины различны.
Замкнутая цепь называется циклом, если различны все ее вершины, за исключением концевых.
Граф называется связным, если для любой пары вершин существует соединяющий их путь.
Вес вершины – рациональное число, поставленное в соответствие данной вершине (интерпретируется как стоимость, пропускная способность и т. д.). Вес (длина) ребра – число или несколько чисел, которые интерпретируются по отношению к ребру как длина.
Взвешенный граф – граф, каждому ребру которого поставлено в соответствие некое значение (вес ребра).
4. Представление графов в компьютере: требования к представлению графов, матрица смежности, матрица инцидентности.
Известны различные способы представления графов в памяти компьютера, которые различаются объемом занимаемой памяти и скоростью выполнения операций над графами. Представление выбирается, исходя из потребностей конкретной задачи.
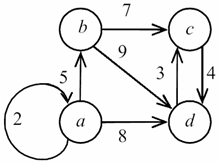
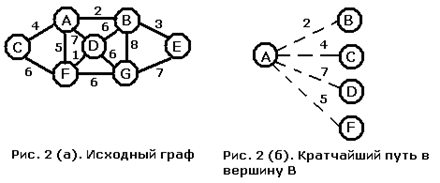
Рис. 2. Пример графа
1. Список ребер – это множество, образованное парами смежных вершин (рис. 2). Для его хранения обычно используют одномерный массив размером m, содержащий список пар вершин, смежных с одним ребром графа. Список ребер более удобен для реализации различных алгоритмов на графах по сравнению с другими способами.
Рис. 3. Список рёбер графа
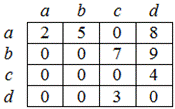
1. Матрица смежности – это двумерный массив размерности n x n, значения элементов которого характеризуются смежностью вершин графа (рис. 2). Значение элемента матрицы – вес ребра, которое соединяет соответствующие вершины. Данный способ действенен, когда надо проверять смежность или находить вес ребра по двум заданным вершинам.
Рис. 4. Матрица смежности графа
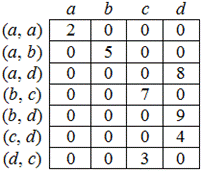
2. Матрица инцидентности – это двумерный массив размерности n x m, в котором указываются связи между инцидентными элементами графа (ребро и вершина). Столбцы матрицы соответствуют ребрам, строки – вершинам (рис. 5). Ненулевое значение в ячейке матрицы указывает связь между вершиной и ребром. Данный способ является самым емким для хранения, но облегчает нахождение циклов в графе.
Рис. 5. Матрица инцидентности графа
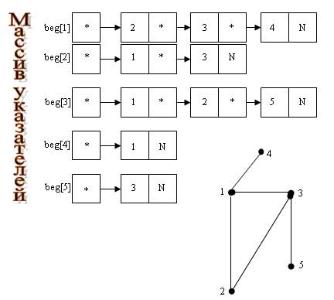
Списки смежности
Список смежности содержит для каждой вершины список смежных ей вершин.
Списочная структура отражает смежность вершин и состоит из массива указателей на списки смежных вершин, где элемент списка представлен структурой –
N = record x: 1 ... p, n: ↑ N end record.
Массив указателей также можно представить списком.
Больше подходит для разреженных графов (у которых количество рёбер гораздо меньше чем количество вершин в квадрате).
рис. Пример списка смежности.
Массив дуг
Представление графа с помощью массива структур (записей), отражающего список пар смежных вершин (или, для орграфов, узлов), называется массивом ребер (массивом дуг). Для массива ребер (или дуг) n (p, q) = O (2 q).
Представление графов с помощью массива ребер (дуг) выглядит следующим образом (для графа G слева, а для орграфа D справа):
b
v
b
v
1
2
1
2
1
4
2
3
2
3
2
4
2
4
4
1
3
4
4
3
Указанные представления пригодны для графов и орграфов.
Обход графов
Обход графа – некоторое перечисление его вершин (и/или ребер). Наибольший интерес представляют обходы, использующие локальную информацию (списки смежности). Среди всех обходов наиболее известны поиск в ширину и в глубину.
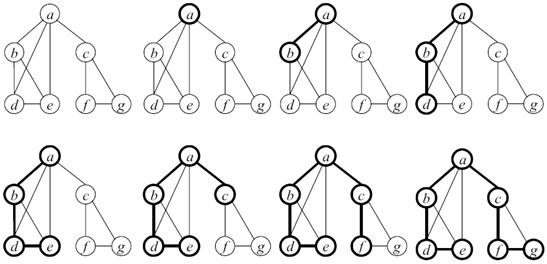
Поиск в глубину
При поиске в глубину посещается первая вершина, затем необходимо идти вдоль ребер графа, до попадания в тупик. Вершина графа является тупиком, если все смежные с ней вершины уже посещены. После попадания в тупик нужно возвращаться назад вдоль пройденного пути, пока не будет обнаружена вершина, у которой есть еще не посещенная вершина, а затем необходимо двигаться в этом новом направлении. Процесс оказывается завершенным при возвращении в начальную вершину, причем все смежные с ней вершины уже должны быть посещены.
Таким образом, основная идея поиска в глубину – когда возможные пути по ребрам, выходящим из вершин, разветвляются, нужно сначала полностью исследовать одну ветку и только потом переходить к другим веткам (если они останутся нерассмотренными).
Алгоритм поиска в глубину
Шаг 1. Всем вершинам графа присваивается значение не посещенная. Выбирается первая вершина и помечается как посещенная.
Шаг 2. Для последней помеченной как посещенная вершины выбирается смежная вершина, являющаяся первой помеченной как не посещенная, и ей присваивается значение посещенная. Если таких вершин нет, то берется предыдущая помеченная вершина.
Шаг 3. Повторить шаг 2 до тех пор, пока все вершины не будут помечены как посещенные (рис. 5).
Рис. 5. Демонстрация алгоритма поиска в глубину
Также часто используется нерекурсивный алгоритм поиска в глубину. В этом случае рекурсия заменяется на стек. Как только вершина просмотрена, она помещается в стек, а использованной она становится, когда больше нет новых вершин, смежных с ней.
Временная сложность зависит от представления графа. Если применена матрица смежности, то временная сложность равна O(n2), а если нематричное представление – O(n+m): рассматриваются все вершины и все ребра.
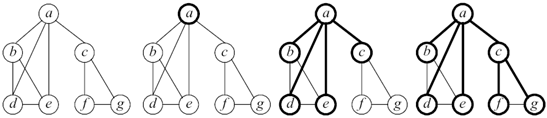
Поиск в ширину
При поиске в ширину, после посещения первой вершины, посещаются все соседние с ней вершины. Потом посещаются все вершины, находящиеся на расстоянии двух ребер от начальной. При каждом новом шаге посещаются вершины, расстояние от которых до начальной на единицу больше предыдущего. Чтобы предотвратить повторное посещение вершин, необходимо вести список посещенных вершин. Для хранения временных данных, необходимых для работы алгоритма, используется очередь – упорядоченная последовательность элементов, в которой новые элементы добавляются в конец, а старые удаляются из начала.
Таким образом, основная идея поиска в ширину заключается в том, что сначала исследуются все вершины, смежные с начальной вершиной (вершина с которой начинается обход). Эти вершины находятся на расстоянии 1 от начальной. Затем исследуются все вершины на расстоянии 2 от начальной, затем все на расстоянии 3 и т.д. Обратим внимание, что при этом для каждой вершины сразу находятся длина кратчайшего маршрута от начальной вершины.
Алгоритм поиска в ширину
Шаг 1. Всем вершинам графа присваивается значение не посещенная. Выбирается первая вершина и помечается как посещенная (и заносится в очередь).
Шаг 2. Посещается первая вершина из очереди (если она не помечена как посещенная). Все ее соседние вершины заносятся в очередь. После этого она удаляется из очереди.
Шаг 3. Повторяется шаг 2 до тех пор, пока очередь не пуста (рис. 6).
Рис. 6. Демонстрация алгоритма поиска в ширину
Алгоритм Дейкстры
Алгоритм находит кратчайшее расстояние от одной из вершин графа до всех остальных и работает только для графов без ребер отрицательного веса.
Каждой вершине приписывается вес – это вес пути от начальной вершины до данной. Также каждая вершина может быть выделена. Если вершина выделена, то путь от нее до начальной вершины кратчайший, если нет – то временный. Обходя граф, алгоритм считает для каждой вершины маршрут, и, если он оказывается кратчайшим, выделяет вершину. Весом данной вершины становится вес пути. Для всех соседей данной вершины алгоритм также рассчитывает вес, при этом ни при каких условиях не выделяя их. Алгоритм заканчивает свою работу, дойдя до конечной вершины, и весом кратчайшего пути становится вес конечной вершины.
Сам алгоритм прохождения
Шаг 1. Всем вершинам, за исключением первой, присваивается вес равный бесконечности, а первой вершине – 0.
Шаг 2. Все вершины не выделены.
Шаг 3. Первая вершина объявляется текущей.
Шаг 4. Вес всех невыделенных вершин пересчитывается по формуле: вес невыделенной вершины есть минимальное число из старого веса данной вершины, суммы веса текущей вершины и веса ребра, соединяющего текущую вершину с невыделенной.
Шаг 5. Среди невыделенных вершин ищется вершина с минимальным весом. Если таковая не найдена, то есть вес всех вершин равен бесконечности, то маршрут не существует. Следовательно, выход. Иначе, текущей становится найденная вершина. Она же выделяется.
Шаг 6. Если текущей вершиной оказывается конечная, то путь найден, и его вес есть вес конечной вершины.
Шаг 7. Переход на шаг 4.
Сложность алгоритма Дейкстры зависит от способа нахождения вершины, а также способа хранения множества не посещённых вершин и способа обновления длин.
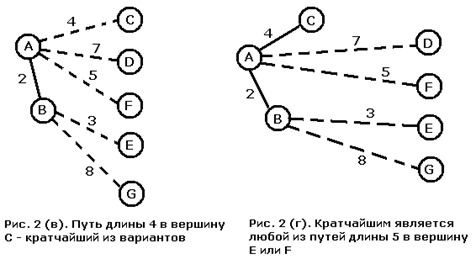
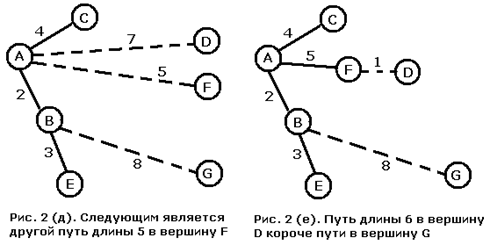
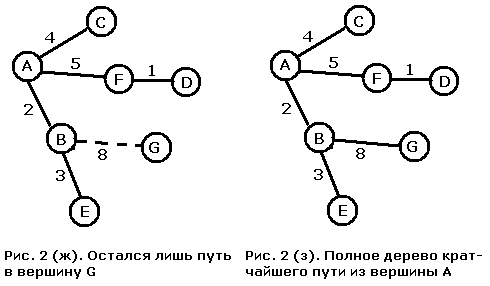
Дерево кратчайших путей.
http://www.algolib.narod.ru/Graph/Path.html
Алгоритм:
выбрать начальную вершину
создать начальную кайму из вершин, соединенных с начальной
while вершина назначения не достигнута do
выбрать вершину каймы с кратчайшим расстоянием до начальной
добавить эту вершину и ведущее в нее ребро к дереву
изменить кайму путем добавления к ней вершин,
соединенных с вновь добавленной
for всякой вершины каймы do
приписать к ней ребро, соединяющее ее с деревом и
завершающее кратчайший путь к начальной вершине
end for
end while
Конструкторы и деструкторы
Конструктор – функция, которая вызывается при создании объекта. Это специальная функция, которая является членом класса и имя которой совпадает с именем класса. Конструкторы не возвращают значений, следовательно, в указании типов нет смысла, нельзя указывать даже void.
Пример:
Конструктор объекта вызывается при создании объекта. Это значит, что он вызывается при выполнении инструкции объявления объекта. Конструкторы глобальных объектов вызываются в самом начале выполнения программы, еще до обращения к функции main(). Конструкторы локальных объектов вызываются каждый раз при объявлении такого объекта. В классе допустимо создавать несколько конструкторов, если это необходимо. Имена будут одинаковыми. Компилятор будет их различать по передаваемым параметрам (как при перегрузке функций). Если мы не передаем в конструктор параметры, он считается конструктором по умолчанию.
Деструктор – функция, которая вызывается при разрушении объекта. Во многих случаях при разрушении объекту необходимо выполнить некоторое действие или даже некоторую последовательность действий. Локальные объекты создаются при входе в блок, в котором они определены, и разрушаются при выходе из него. Глобальные объекты разрушаются при завершении программы. Существует множество факторов, обуславливающих необходимость деструктора. Например, объект должен освободить выделенную ранее память. Имя деструктора совпадает с именем конструктора, но перед ним стоит символ ~. Как и конструкторы, ничего не возвращают.
Пример: (класс берётся из конструктора, но в него надо дописать ~queue();)
В классе может быть объявлен только один деструктор.
Шаблоны классов
Шаблоны позволяют определить конструкции (функции, классы), который используют определенные типы, но на момент написания кода точно не известно, что это будут за типы. Иными словами, шаблоны позволяют определить универсальные конструкции, которые не зависят от определенного типа. Шаблон класса (class template) задаёт тип для объектов, используемых в классе.
Для применения шаблонов перед классом указывается ключевое слово template, после которого идут угловые скобки. В угловых скобках после слова typename идет параметр шаблона. Можно определить несколько параметров шаблона.
Параметр шаблона представляет произвольный идентификатор, в качестве которого, как правило, применяются заглавные буквы. Параметр будет представлять некоторый тип, который становится известным во время компиляции. Это может быть и тип int, и double, и string, и любой другой тип.
Общая форма объявления класса-шаблона:
template < class птип> class имя_класса {
/*...*/
}
Здесь птип является параметром-типом, который будет указан при создании экземпляра класса. При необходимости можно определить несколько типов-шаблонов, используя список и запятую в качестве разделителя.
После создания класса-шаблона можно создать конкретный экземпляр этого класса, используя следующую общую форму:
имя_класса <тип> объект;
Здесь тип является именем типа данных, с которыми будет оперировать данный класс.
Общее наследование
При общем наследовании порожденный класс имеет доступ к наследуемым членам базового класса с видимостью public и protected. Члены базового класса с видимостью private – недоступны.
Спецификация доступа
внутри класса
в порожденном классе
вне класса
private
+
-
-
protected
+
+
-
public
+
+
+
Таким образом, порожденный класс представляет собой модификацию базового класса, которая наследует общие и защищенные члены базового класса.
Частное наследование
Порожденный класс может быть базовым для следующего порождения. При порождении private наследуемые члены базового класса, объявленные как protected и public, становятся членами порожденного класса с видимостью private. При этом члены базового класса с видимостью public и protected становятся недоступными для дальнейших порождений. Цель такого порождения — скрыть классы или элементы классов от использования в дальнейших порождениях. При порождении private не выполняются предопределенные стандартные преобразования.
Однако порождение private позволяет отдельным элементам базового класса с видимостью public и protected сохранить свою видимость в порожденном классе. Для этого необходимо в части protected порожденного класса указать те наследуемые члены базового класса с видимостью protected, уточненные именем базового класса, для которых необходимо оставить видимость protected и в порожденном классе; в части public порожденного класса указать те наследуемые члены базового класса с видимостью public, уточненные именем базового класса, для которых необходимо оставить видимость public и в порожденном классе.
Возможен и третий вариант наследования – с использованием модификатора доступа protected.
Доступ к элементам базового класса из производного класса, в зависимости от модификатора наследования:
Модификатор наследования →
Public
Protected
Private
Модификатор доступа ↓
public
public
protected
private
protected
protected
protected
private
private
нет доступа
нет доступа
нет доступа
Виртуальные деструкторы
В языке программирования C++ деструктор полиморфного базового класса должен объявляться виртуальным. Только так обеспечивается корректное разрушение объекта производного класса через указатель на соответствующий базовый класс.
Уничтожение объекта производного класса через указатель на базовый класс с невиртуальным деструктором дает неопределенный результат. На практике это выражается в том, что будет разрушена только часть объекта, соответствующая базовому классу.
Когда же следует объявлять деструктор виртуальным? Cуществует правило - если базовый класс предназначен для полиморфного использования, то его деструктор должен объявляться виртуальным. Для реализации механизма виртуальных функций каждый объект класса хранит указатель на таблицу виртуальных функций vptr, что увеличивает его общий размер. Обычно, при объявлении виртуального деструктора такой класс уже имеет виртуальные функции, и увеличения размера соответствующего объекта не происходит.
Если же базовый класс не предназначен для полиморфного использования (не содержит виртуальных функций), то его деструктор не должен объявляться виртуальным.
Абстрактные методы и классы
Абстрактный метод (или чистый виртуальный метод (pure virtual method - часто неверно переводится как чисто виртуальный метод)) — в объектно-ориентированном программировании, метод класса, реализация для которого отсутствует.
Класс, содержащий абстрактные методы, также принято называть абстрактным. Абстрактные методы зачастую путают с виртуальными. Абстрактный метод подлежит определению в классах-наследниках, поэтому его можно отнести к виртуальным, но не каждый виртуальный метод является абстрактным.
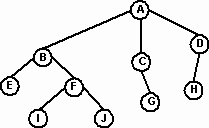
Терминология
Древовидная структура характеризуется множеством узлов (nodes), происходящих от единственного начального узла, называемого корнем (root). На Рис. 3 корнем является узел А. В терминах генеалогического дерева узел можно считать родителем (parent), указывающим на 0, 1 или более узлов, называемых сыновьями (children). Например, узел В является родителем сыновей E и F. Родитель узла H - узел D. Дерево может представлять несколько поколений семьи. Сыновья узла и сыновья их сыновей называются потомками (descendants), а родители и прародители – предками (ancestors) этого узла. Например, узлы E, F, I, J – потомки узла B. Каждый некорневой узел имеет только одного родителя, и каждый родитель имеет 0 или более сыновей. Узел, не имеющий детей (E, G, H, I, J), называется листом (leaf).
Каждый узел дерева является корнем поддерева (subtree), которое определяется данным узлом и всеми потомками этого узла. Узел F есть корень поддерева, содержащего узлы F, I и J. Узел G является корнем поддерева без потомков. Это определение позволяет говорить, что узел A есть корень поддерева, которое само оказывается деревом.
Рис.3.
Переход от родительского узла к дочернему и к другим потомкам осуществляется вдоль пути (path). Например, на Рис. 4 путь от корня A к узлу F проходит от A к B и от B к F. Тот факт, что каждый некорневой узел имеет единственного родителя, гарантирует, что существует единственный путь из любого узла к его потомкам. Длина пути от корня к этому узлу есть уровень узла. Уровень корня равен 0. Каждый сын корня является узлом 1-го уровня, следующее поколение – узлами 2-го уровня и т.д.
Глубина (depth) дерева есть его максимальный уровень. Понятие глубины также может быть описано в терминах пути. Глубина дерева есть длина самого длинного пути от корня до узла.
Дерево поиска – это двоичное дерево, в котором узлы упорядочены определенным образом по значению ключей: для любого узла x. значения ключей всех узлов его левого поддерева меньше значения ключа x, а значения ключей всех узлов его правого поддерева больше значения ключа x.
Удаление узла из АВЛ-дерева
Непосредственно удаление узла из АВЛ-дерева происходит так же, как и удаление узла из обычного двоичного дерева поиска. Если у узла менее двух сыновей, то удаляется сам узел, а если два сына, то удаляемым узлом становится его последователь, информация (ключ) из которого предварительно переписывается в удаляемый узел. Чтобы после удаления сохранились свойства АВЛ- дерева, возможно, понадобится выполнить балансировку. Для этого надо подниматься вверх по пути от удаленного узла к корню и проверять в этих узлах баланс. Если в узле баланс нарушен, то надо выполнить соответствующий поворот – одинарный или двойной. Остановить просмотр можно на том узле, в котором показатель баланса не поменялся. Это означает, что высота его поддерева, левого или правого, в котором производилось удаление, не изменилась. При балансировке после удаления используются те же виды поворотов, что и после вставки узла в дерево.
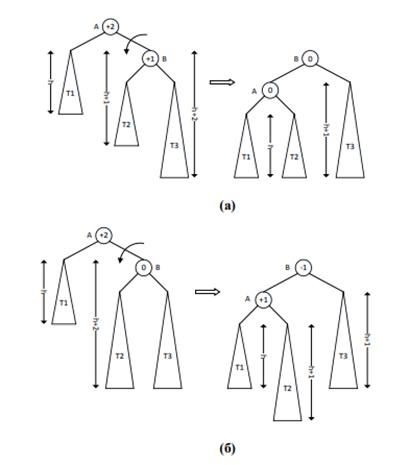
1. Левое поддерево стало ниже правого на 2 уровня.
a. У правого сына (B) высота правого поддерева больше, либо равна высоте левого поддерева (height(T3) ≥ height(T2)), необходимо произвести левый поворот (L): опорный узел (A) поворачивается налево относительно своего правого сына (B).
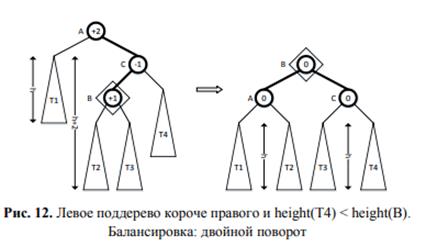
b. У правого сына (C) высота правого поддерева меньше вы- соты левого поддерева (height(T4) < height(B)). Необходимо произвести двойной поворот — направо, потом налево (RL): сначала правый сын опорного узла (C) поворачивается направо относительно своего левого сына (B), а затем опорный узел (A) поворачивается налево относительно своего нового правого сына (B).
Левое поддерево короче правого и (а) height(T3) > height(T2); (б) height(T3) = height(T2). Балансировка: левый поворот
2. Правое поддерево стало ниже левого на 2 уровня (случай, симметричный случаю 1).
a. У левого сына высота левого поддерева больше, либо равна высоте правого поддерева. Случай, симметричный случаю 1а.
b. У левого сына высота левого поддерева меньше высоты правого поддерева. Случай, симметричный случаю 1b
Правила удаления такие же, как при вставке: если самые глубокие узлы находятся справа или слева, то производится одинарный поворот опорного узла в противоположную сторону, а если они находятся посередине, то производится двойной поворот.
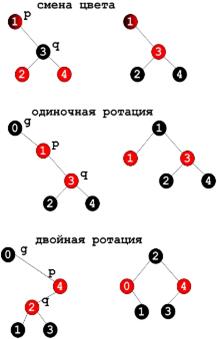
Варианты вставки узла в красно-чёрное дерево
При вставке нового узла в красно-черное дерево для него изначально устанавливается красный цвет. Затем для добавляемого элемента выполняется поиск родительского узла и проверка его цвета. Если цвет родителя черный, то основной критерий цветного дерева сохраняется. Если же родитель - красного цвета, то выполняется итеративная (нерекурсивная) балансировка дерева. В худшем случае время вставки может достичь значения логарифма от числа узлов в красном дереве.
Для упрощения алгоритма предполагается, что листья (узлы, не имеющие потомков) имеют черный цвет.
В общем случае при вставке нового узла возможны три варианта.
- происходит изменение цвета;
- требуется сделать один поворот;
- требуется сделать двойной поворот.
Для этого в памяти кроме текущего узла нужно хранить еще три уровня дерева: «родителя», «деда» и «прадеда» текущего узла.
Варианты удаления узла из красно-чёрного дерева
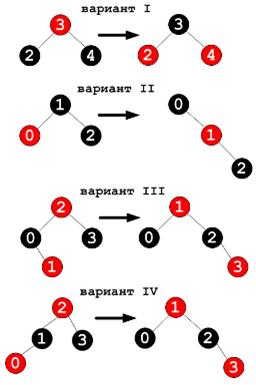
При удалении узла из цветного дерева цвет родительского узла не изменяется. Удаление красного узла не влечет никаких последствий, коллизию может вызвать только удаление узла черного цвета. Поэтому при удалении черного узла для обеспечения целостности дерева необходимо использовать различные операции: простую смену цвета (если это возможно) или одну или несколько ротаций. Ниже представлены 4 ситуации, возможных при удалении черного узла.
Если при удалении черного узла, его «брат» (узел, находящийся на том же уровне, что и удаляемый) и все их четыре потомка имеют черный цвет (это вариант I на рисунке 2), то выполняется изменение цвета.
Если «брат» удаляемого узла окрашен в красный цвет, то производится ротация, изображенная на варианте II.
Если удаляемый узел и его «брат» черного цвета, а правый потомок «брата» - красного, то выполняется двойная ротация, изображенная на варианте 4.
Если левый потомок «брата» красного, то выполняется одиночная ротация, как в пятом варианте.
Сравнение АВЛ с КЧ
По сложности реализации самые простые – АВЛ-дерево, самые сложные – КЧ-деревья, поскольку приходится рассматривать много нетривиальных случаев при вставке и удалении узла.
Восстановление свойств как АВЛ-дерева, так и КЧ- дерева после вставки требует не более двух поворотов. Но после удаления узла из КЧ-дерева потребуется не более трех поворотов, а в АВЛ-дереве после удаления узла может потребоваться количество поворотов до высоты дерева (от листа до корня). Поэтому операция удаления в КЧ-дереве эффективнее, в связи с чем они больше распространены.
Если входные данные полностью рандомизированы, то наилучшим вариантом оказываются деревья поиска общего вида – несбалансированные. Если входные данные в основном рандомизированные, но периодически встречаются упорядоченные наборы, то стоит выбрать КЧ-деревья. Если при вставке преобладают упорядоченные данные, то АВЛ-деревья оказываются лучше в случае, когда дальнейший доступ к элементам рандомизирован.
Структура машины.
Структура машины состоит из трех основных узлов: лента, разбитая на ячейки; управляющее устройство (УУ); устройство обращения к ленте (головка). Рассмотрим подробнее эти узлы.
Лента. Конечная лента справа, но не слева, разбитая на ячейки, в каждой из которых может быть записан один из символов конечного алфавита S = {S1, S2,…,Sm}.
Символами этого алфавита кодируются как сведения, подаваемые в машину, так и те сведения, которые в ней вырабатываются. Среди знаков имеется пустой символ (пробел) ë. Посылка этого символа в какую-либо ячейку ленты приводит к стиранию любого символа записанного в этой ячейке и оставляет ее пустой.
В начальный момент времени только конечное число ячеек заполнено, остальные ячейки пусты, т.е. содержат символ ë.
Управляющее устройство (УУ), которое настроено на выполнение одной из множества возможных операций или, как принято говорить, может находиться в одном из состояний, образующих конечное множество состояний Q={q1, q2,…,qn}. В состоянии q1 машина Тьюринга находится перед началом работы, а попав в состояние qz ∈ Q, она останавливается, вокруг обозреваемой ячейки пустые символы.
Устройство обращения к ленте представляет собой считывающую или записывающую головку, которая в каждый момент времени обозревает какую-либо ячейку ленты и в зависимости от символа в этой ячейке и состояния УУ выполняет следующие действия:
1. производит запись в ячейку нового символа (может быть совпадающего со старым символом), или стирает символ (запись пустого символа ë);
2. сдвигает головку вправо или влево, при этом УУ переходит в новое состояние;
Перечисленные действия являются элементарными действиями. Для любого внутреннего состояния q1 и символа алфавита Sj однозначно задана логическая функция, которая определяет следующее состояние , символ алфавита, который должен быть записан, направление сдвига головки L – сдвиг влево, R – сдвиг вправо, Е – отсутствие сдвига.
Работа машины Тьюринга.
Пусть задана МТ с алфавитом S = {1, á, â, ë} и состояниями Q = {q1, q2, q3, q4, q5}. Перед началом работы на ленту заносится начальная информация (например, пять 1) и фиксируется начальная обозреваемая ячейка (например,4). Работа описывается таблицей:
q1
q2
q3
q4
q5
ë
q4 áR
q3 áL
q1áR
q5 ëL
q5 ëE
1
q2 áE
q1âE
q11R
q5 ëR
q5 1E
á
q4 áL
q2 áR
q3 1L
q4ëR
q5 áE
â
q1âL
q2 âR
q3 áL
q4ëR
q5 âE
Определить:
- Информацию на ленте после останова.
- Записать систему Тьюринговых команд.
- Построить блок-схему работы МТ.
Изобразим на ленте начальную информацию и фиксированную ячейку:
Учитывая начальные условия, будем искать в таблице пересечение строки содержащей символ алфавита 1 и состояния q1. Это пересечение равно - q2 áE. Система Тьюринговых команд имеет вид - . Данная запись означает: машина переходит в состояние q2, записывает в 4 ячейку символ алфавита á и оставляет головку на ячейке с номером 4. Теперь будем искать в таблице пересечение строки содержащей символ алфавита á и состояния q2 . Это пересечение равно - q2 áR. Данная запись означает: машина переходит в состояние q2, записывает в 4 ячейку символ алфавита á и переводит головку на ячейке с номером 3 и т.д.
Информация на ленте
Система Тьюринговых команд
Состояние МТ не меняется, символ в ячейке не меняется, следовательно, состояние q5 является конечным состоянием. Работа машины Тьюринга останавливается.
Диаграмма переходов машины Тьюринга для заданных начальных условий и таблицы функционирования имеет вид:
Структура машины Поста.
Машина поста состоит из ленты и каретки (называемой так же считывающей и записывающей головкой).
Лента неограниченна и разделена на одинаковые секции (ячейки). Порядок, в котором расположены секции ленты, подобен порядку, в котором расположены все целые числа. Поэтому естественно ввести на ленте «целочисленную систему координат», пронумеровав секции целыми числами …, -3, -2, -1, 0, 1, 2, 3, … Будем считать, что система координат жестко сопоставлена с лентой, и таким образом, получим возможность указывать какую-либо секцию ленты, называя ее порядковый номер, или координату.
В каждой секции ленты может быть либо ничего не записано (такая секция называется пустой), либо записана метка V (тогда секция называется отмеченной).
Информация о том, какие секции пусты, а какие отмечены, образуют состояние ленты.
Каретка может передвигаться вдоль ленты влево и вправо. Когда она неподвижна, она стоит против одной секции ленты, говорят, что каретка обозревает эту секцию, или держит ее в поле зрения.
Информация о том, какие секции пусты, а какие отмечены и где стоит каретка, образует состояние машины Поста. За единицу времени (называемую шагом) каретка может поставить (напечатать) или уничтожить (стереть) метку в той секции, против которой она стоит, а так же распознать, стоит или нет метка в обозреваемой ею секции.
Работа машины Поста.
Работа машины Поста состоит в том, что каретка передвигается вдоль ленты и печатает или стирает метки. Эта работа происходит по инструкции, называемой программой. Для машины Поста возможно составление различных программ. Каждая программа машины Поста состоит из команд. Командой машины Поста называют выражение, имеющее структуру n K m, где n – порядковый номер команды, K – действие, выполняемое кареткой, m – номер следующей команды, подлежащей выполнению.
Существует всего шесть команд машины:
Команда машины Поста
Выполняемое действие
n ® m
Передвинуть каретку вдоль ленты на одну секцию вправо
n m
Передвинуть каретку вдоль ленты на одну секцию влево
n M m
Нанесение метки в секцию, над которой находится головка
n C m
Стирание метки из секции, над которой находится головка
Проверка наличия метки в секции, над которой находится каретка. Если метка отсутствует, то управление передается к
Архитектура электронного правительства: Единая архитектура – это методологический подход при создании системы управления государства, который строится...








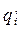 , символ алфавита,
, символ алфавита, 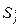 который должен быть записан, направление сдвига головки L – сдвиг влево, R – сдвиг вправо, Е – отсутствие сдвига.
который должен быть записан, направление сдвига головки L – сдвиг влево, R – сдвиг вправо, Е – отсутствие сдвига.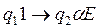 . Данная запись означает: машина переходит в состояние q2, записывает в 4 ячейку символ алфавита á и оставляет головку на ячейке с номером 4. Теперь будем искать в таблице пересечение строки содержащей символ алфавита á и состояния q2 . Это пересечение равно - q2 áR. Данная запись означает: машина переходит в состояние q2, записывает в 4 ячейку символ алфавита á и переводит головку на ячейке с номером 3 и т.д.
. Данная запись означает: машина переходит в состояние q2, записывает в 4 ячейку символ алфавита á и оставляет головку на ячейке с номером 4. Теперь будем искать в таблице пересечение строки содержащей символ алфавита á и состояния q2 . Это пересечение равно - q2 áR. Данная запись означает: машина переходит в состояние q2, записывает в 4 ячейку символ алфавита á и переводит головку на ячейке с номером 3 и т.д.