

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
Типы сооружений для обработки осадков: Септиками называются сооружения, в которых одновременно происходят осветление сточной жидкости...
Топ:
Отражение на счетах бухгалтерского учета процесса приобретения: Процесс заготовления представляет систему экономических событий, включающих приобретение организацией у поставщиков сырья...
Когда производится ограждение поезда, остановившегося на перегоне: Во всех случаях немедленно должно быть ограждено место препятствия для движения поездов на смежном пути двухпутного...
Интересное:
Лечение прогрессирующих форм рака: Одним из наиболее важных достижений экспериментальной химиотерапии опухолей, начатой в 60-х и реализованной в 70-х годах, является...
Аура как энергетическое поле: многослойную ауру человека можно представить себе подобным...
Финансовый рынок и его значение в управлении денежными потоками на современном этапе: любому предприятию для расширения производства и увеличения прибыли нужны...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
В этом разделе мы представим несколько подходов, предназначенных для решения дилеммы исследования/эксплуатации (которая может быть связана с активным обучением). Первый – это хорошо известная E-жадная политика, она служит базовым уровенем. Другие подходы взяты из литературы и используют доступную информацию о неопределенности (см. раздел 3 для её расчёта). Соответствующие алгоритмы представляют собой комбинацию KTD- SARSA (алг.1 с 2м уравнением (1)) и политики (5-8).

Рис.5. Политики
E-жадная политика
Ипользуя E-жадную политику (Саттон и Барто, 1996), агент выбирает жадное действие, соответствующее оценённой Q-функции в текущий момент с
 (5)
(5)
Эта политика возможно наиболее простая и не использует никакую информацию о неопределённости. Произвольная Q-функция для данного состояния с 4мя разными действиями показаны на рис.6. Для каждого действия она даёт оценку Q-значения также, как политики, связанные с неопределённостью (т.е. ± оценённая стандартное отклонение (estimated standard deviation)). Например, действие 3 имеет наивысшую ценность и минимальную неопределённость, а действие 1 имеет наименьшую ценность и наибольшую неопределённость. Иллюстрация распределения вероятностей, ассоциированное с Е-жадной политикой, показана на рис.5. a. Наивысшая вероятность связана с действием 3, а остальные действия имеют одинаковую (низкую) вероятность, несмотря на их разные оценки ценности и стандартные отклонения.
Доверительно-жадная политика
Второй подход, который мы предлагаем, состоит в том, чтобы действовать жадно в соответствии с верхней границей предполагаемого доверительного интервала (estimated confidence interval). Подход не нов (Kaelbling, 1993), однако некоторые PAC (вероятностно приблизительно правильные) гарантии были даны недавно Strehl и Littman (2006) для табличного представления (для которого доверительный интервал пропорционален обратному квадратного корню от числа посещений рассматриваемой пары состояние-действие). В нашем случае мы постулируем, что ширина доверительного интервала пропорциональна оценённому стандартному отклонению (что верно, если распределение параметров предполагается гауссовским). Пусть α будет свободным положительным параметром, мы определяем доверительно-жадную политику как:
|
|
 (6)
(6)
Рассматриваются те же произвольные Q-значения (см. рис.6), доверительно-жадная политика показана на рис.5.b, которая представляет верхнюю границу доверительного интервала. Действие 1 выбрано потому, что оно имеет наивысшее значение (несмотря на то, что оно имеет наименьшую оценённую ценность). Обратите внимание, что действие 3, которое является жадным относительно оценённой Q-функции, имеет только третью величину.
Бонус-жадная политика
Третий подход вдохновлён методом Kolter and Ng (2009). Политика, которую они использовали является жадной относительно оценённой Q-функции плюс бонус, причём этот бонус пропорционален обратному числу посещений интересующей пары состояние-действие (которая может быть интерпретирована как дисперсия вместо квадратного корня этой величины для подходов, основанных на оценке интервалов, которые можно интерпретировать как стандартное отклонение).
Бонус-жадная политика использует дисперсию вместо стандартного отклонения и определятся, как (β0 и β являются двумя свободными параметрами):
 (7)
(7)
Бонус-жадная политика демонстрируется на рис.5 c, всё ещё используются произвольные Q-значения и соответствующие стандартные отклонения из рис.6. Действие 2 имеет наивысшую оценку, поэтому оно выбрано. Обратите внимание, что 3 других действия имеют примерно одинаковую оценку, несмотря на то, что они имеют совершенно разные Q-значения.
|
|
Политика Томпсона
Напомним, что алгоритм KTD поддерживает следующие параметры: вектор средних значений и матрица дисперсий. Предполагая, что распределение параметров является гауссовским, мы предлагаем выбрать набор параметров из этого распределения, а затем действовать жадно в соответствии с полученной выборочной (sampled) Q-функцией. Этот тип схемы впервые предложен у Thompson (1933) для задачи бандита, которая недавно была представлена сообществу обучения с подкреплением для случая табличного представления (Dearden et al., 1998; Strens, 2000). Пусть политика Томпсона является:
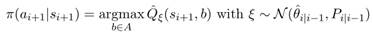 (8)
(8)
Политика демонстрируется на рис.5. d, показывая распределение жадного действия (напомним, что параметры случайные, и, следовательно, жадное действие тоже). Наибольшая вероятность связана с действием 3. Однако, обратите внимание, что вероятность, связанная с действием 1 больше, чем с действием 4: 1я имеет более низкое оценённое Q-значение, но она менее определена.


Рис.6. Q-значения и связанная неопределённость. Рис.7. Результаты задачи о бандите.
Эксперимент
Задача о многоруком бандите есть MDP с 1м состоянием и N действиями. Каждое действие a предполагает награду = 1 с вероятностью pa, и награду = 0 с вероятностью 1− pa. Для действия a ∗ (случайно выбранного в начале каждого эксперимента), вероятность установлена pa ∗=0.6. Для всех остальных действий, соответствующая вероятность случайно и равномерно выбирается между 0 и 0.5: pa ∼ U[0, 0.5], ∀ a≠ a ∗. Представлены результаты, усреднённые по 1000 экспериментам. Производительность метода измерена в процентах от времени, когда выбирается оптимальное действие, учитывая число взаимодействий между агентом и бандитом. Табличное представление адаптировано для KTD- SARSA, и следующие параметры были использованы[3]: N=10, P0|0=0.1 I, θ0|0= I, Pni=1, Е=0.1, α=0.3, β0=1 и β=10. Рассмотренный бандит имеет N=10 рук, случайная политика имеет производительность равную 0.1. Обратите внимание, чисто жадная политика будет систематически выбирать первое действие, в котором агент наблюдал награду.
Результаты, представленные на рис.7, сравнивают 4 схемы. Е-жадная политика служит базовым уровнем, и все предлагаемые схемы, использующие имеющуюся неопределенность, работают лучше. Политика Томпсона и доверительно-жадная политика работают примерно одинаково хорошо, а наилучшие результаты достигаются политикой бонус-жадности. Разумеется, эти довольно предварительные результаты не позволяют сделать вывод о гарантиях сходимости предложенных схем. Тем не менее, они, как правило, показывают, что вычисленная информация о неопределенности имеет смысл и может быть полезной для решения дилеммы исследования и эксплуатации.
|
|
Приложение управление диалогами
В этом разделе предложено приложение для задачи из реального мира: речевые диалоговые системы (spoken dialog system [4]) (SDS), направленные на предоставление информации пользователю посредством взаимодействия на естественном языке. SDS имеет примерно 3 модуля: компонент понимания речи (распознаватель речи и семантический анализатор), менеджер диалога и компонент генерации речи (генератор естественного языка и синтез речи). Управление диалогами – это задача последовательного принятия решений, при которой менеджер диалога должен выбрать, какую информацию следует запрашивать или предоставлять пользователю в данной ситуации. Таким образом, задача может быть преобразована в схему MDP (Levin et al., 2000; Singh et al., 1999; Pietquin and Dutoit, 2006). Набор действий, из которых менеджер диалогов может выбирать, определяется так называемыми диалоговыми действиями (dialog acts). Бывают разные диалоговые действия: приветствие пользователя, запрос части информации, предоставление части информации, запрос подтверждения части информации, завершение диалога и т.д. Состояние диалога обычно эффективно представляется парадигма Информационного Состояния (Larsson and Traum, 2000). В этой парадигме состояние диалога содержит компактное представление истории диалога в терминах диалоговых действий и ответов пользователя. Состояние обобщает информацию, которой обмениваются пользователь и система, пока не будет достигнуто рассматриваемое состояние. Следовательно, политика управления диалогом π является отображением между состояниями диалога и диалоговыми действиями. Согласно схеме MDP должна быть определена функция награды. Непосредственная награда обычно моделируется, как вклад каждого действия в удовлетворение пользователя (Singh et al., 1999). Это субъективная награда, которая обычно приближена линейной комбинацией объективных измерений.
|
|
Рассматриваемая система является речевой диалоговой системой с заполнением форм (form-filling). Она ориентирована на туристическую информацию, аналогично описанной Lemon et al. (2006). Её цель – предоставить информацию о ресторанах, основанную на специфичных предпочтениях пользователя. У данной задачи о диалоге 3 пункта, а именно расположение ресторана, тип кухни (cuisine) ресторана и его ценовой-диапазон. Учитывая прошлые взаимодействия с пользователем, агент спрашивает вопрос, чтобы предоставить лучший выбор, согласно предпочтениям пользователя. Цель предоставить корректную информацию пользователю за наименьшее число взаимодействий с ним, которое возможно.
Советующее состояние MDP имеет 3 непрерывные компоненты в диапазоне от 0 до 1, каждое из которых представляет усреднённую оценку достоверности заполненной и подтверждённой информации (представленные автоматической системой распознавания речи) в соответствующие места-пункты. Всего 13 возможных действий: попросить заполнить 1 пункт (3 действия), явное подтверждение 1 пункта формы (3 действия), неявное подтверждение 1 пункта формы и запрос на заполнение другого пункта (6 действий), наконец завершение диалога предложением ресторана (1 действие). Соответствующая награда всегда 0, кроме моментов, когда диалог завершён. В этом случае агент награждается 25 за 1 корректно заполненный пункт, -75 на 1 некорректно заполненный пункт формы, наконец -300 за 1 пустой пункт. Дисконтирующий множитель установлен γ=0.95. Хотя конечной целью является реализация RL в реальной задаче управления диалогом, в этом эксперименте для генерации данных использовалась техника имитации пользователя (Pietquin and Dutoit, 2006). Симулятор пользователя был подключен к системе управления диалогами (Lemon et al., 2006) для генерации примеров диалога. Q-функция представлена, как 1 RBF -нейросеть на 1 действие. Каждая RBF -нейросеть имеет 3 равномерно-распределённые (equispaced) функций Гаусса на 1 размерность, каждая со стандартным отклонением σ = 1/3 (переменные состояния в диапазоне от 0 до 1). Поэтому там 351 (т.е., 33×13) параметр.
KTD- SARSA с E-жадной и бонус-жадной политиками сравниваются на рис.2 (результаты усреднены на 8ми независимых попытках и каждая точка усреднена на 100 последних эпизодах: стабильная кривая означает нижнее стандартное отклонение). LSPI – это алгоритм вне-политики (off-policy) пакетного обучения методом приблизительной итерацией-политики (policy iteration) (Lagoudakis and Parr, 2003), служит базовым уровнем сравнения. Он был обучен вне-политики пакетным образом с использование случайных траекторий и предоставляет конкурентные результаты на текущее положение дел (Li et al., 2009a; Chandramohan et al., 2010). Оба алгоритма KTD представляют хорошие результаты (положительную совокупную награду, что значит, что пользователь в общем удовлетворяется после нескольких итераций). Однако, можно наблюдать, что бонус-жадная политика представляет более быструю сходимость, как и лучшую, и более стабильную политику, чем неинформированная Е-жадная политика. Более того, результаты для информированного KTD- SARSA очень близки к LSPI после немногих эпизодов обучения. Таким образом, KTD- SARSA является эффективным по выборке (sample efficient) (предоставляет хорошие политики, в то время, как неудовлетворительное число переходов препятствует использованию LSPI, из-за проблем с численной стабильностью), и предоставляет информацию о неопределённости, полезную для задачи управления диалогом.
|
|
Conclusion
В данной статьи мы показываем, как неопределённость информации о оценённых значения может быть извлечена из KTD. Мы имеем также представленную как активное обучение схему, нацеленную на улучшение скорости выбора движений согласно их относительной неопределённости, как адаптации существующих схем исследования/эксплуатации. 3 эксперимента предложены: первый показывает, что KTD- Q – алгоритм второго порядка итерации ценностей эффективен по образцам. Улучшения, полученные с использованием предложенной схемы активного обучения также демонстрированы. Над предложенными схемами исследования/эксплуатации были проведены успешные эксперименты на задаче бандита и задаче из реального мира с использованием политики бонус-жадной. Этот первый шаг в комбинировании дилеммы исследования и эксплуатации с аппроксимацией функции ценности.
Следующим шагом будет адаптация больше существующих подходов, работающих с дилеммой исследования/эксплуатации, разработанных для табличного представления функции ценности, к структуре KTD, а также предоставление некоторых теоретических гарантий для озвученных подходов. Эта статья сфокусирована на безмодельном обучении с подкреплением, мы планируем сравнить этот подход с RL, основанными на модели.
[1] https://habr.com/ru/post/121904/
https://ru.wikipedia.org/wiki/Фильтр_Калмана
http://ais.informatik.uni-freiburg.de/teaching/ws13/mapping/pdf/slam06-ukf-4.pdf
[2] https://en.wikipedia.org/wiki/Propagation_of_uncertainty
[3] Чтобы увидеть эмпирические данные о влиянии на производительность указанных политик, как функций от параметров, см Geist (2009).
[4] https://en.wikipedia.org/wiki/Spoken_dialog_systems
https://www.speech.kth.se/~gabriel/thesis/chapter2.pdf
|
|
|

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...

Двойное оплодотворение у цветковых растений: Оплодотворение - это процесс слияния мужской и женской половых клеток с образованием зиготы...

Своеобразие русской архитектуры: Основной материал – дерево – быстрота постройки, но недолговечность и необходимость деления...

Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ - конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!