Основные компоненты нейронных сетей. Обучение нейронной сети.
Основой нейронных сетей является искусственный нейрон:

Основные компоненты:
· Нейроны.
· Множество связей с весовыми коэффициентами wi (весовые коэффициенты определяют силу связи между нейронами).
· Правило вычисления входного сигнала. Входные сигналы хi - это данные, поступающие из окружающей среды или от других активных нейронов. Диапазон входных значений для различных моделей может отличаться. Обычно входные значения являются дискретными (бинарными) и определяются множ-ми {0,1}, {-1,1} или принимают любые вещ-ые значения.
· Правило вычисления выходного сигнала.
Обучение нейронной сети.
Суть процесса обучения состоит в изменение весовых коэффициентов.
- Контролируемое обучение (c учителем), его пример персептрон, где текущий выход постоянно сравнивается с желаемым выходом. Весы сначала устанавливаются случайно, но во время следующих итераций корректируются для достижения соответствия между желаемым и текущим выходом. Фаза обучения может быть длительной, учебные примеры могут прогоняться через нейросеть по нескольку раз. Обучение считается законченным при достижении нейросетью определенного уровня точности.
- Неконтролируемое обучение.
Его примеры сеть Кохонена, являющаяся самообучаемой, и сеть Хопфилда, весовые коэффициенты которой вычисляются при её настройке.
Персептрон -один из типов однослойной нейронной сети.
Входные значения персептрона биполярны (-1 или 1), а вес - вещественное число.
Правило вычисления входного сигнала:  , который определяется взвешенной суммой его входных сигналов.
, который определяется взвешенной суммой его входных сигналов.
Выходное значение персептрона вычисляется:
- Пороговая функция  .
.
- Тождественная функция  ,
,
- Сигмоидальная функция 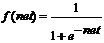 .
.
Для изменения весовых коэф используется следующее правило. Пусть с - постоянный коэффициент скорости обучения, a d - ожидаемое значение выхода, r – реальное. Настройка весового коэффициента для i-го компонента входного вектора выполняется по формуле
 - дельта-правило. При использовании такой процедуры получается вес, минимизирующий среднюю ошибку на всем обучающем множестве.
- дельта-правило. При использовании такой процедуры получается вес, минимизирующий среднюю ошибку на всем обучающем множестве.
Однако выявили ограниченность модели персептрона. Персептрон не решает целого класса достаточно сложных задач, в которых данные не являются линейно разделимыми.
Обучение по методу обратного распространения
Для каждого входного вектора и связанного с ним целевого выполнять:
1.Выполнить прямой проход и найти реальный выход.
2. Получить вектор ошибок как разность целевого и реального векторов.
3. Выполнить обратный проход для вектора ошибок.
4. Определить величины изменения значений весов.
5. Обновить значения весовых коэффициентов.
Сеть Кохонена
Сеть Кохонена, предназначенная для решения задачи кластеризации. Под кластеризацией понимается разбиение множества входных сигналов на классы, при том, что ни количество, ни признаки классов заранее не известны. После обучения такая сеть способна определять, к какому классу относится входной сигнал.


Сеть Кохонена имеет следующие характеристики:
- Входные сигналы – это вектор, который надо отнести нужному кластеру. Самообучение производиться на множестве векторов.
- Весовые коэф-ты – это координаты центров кластеров.
- Вычисление входного сигнала, производится по формуле netj =
 - это есть евклидово расстояние между центром кластера j и входным n-мерным вектором.
- это есть евклидово расстояние между центром кластера j и входным n-мерным вектором. - Нейрон победитель, евклидово расстояние которого наименьшее. После того как он определен, настраиваются его весовые коэф-ты, так чтобы выигравший кластер приблизился к входному вектору.
 , c – коэф-т скорости обучения.
, c – коэф-т скорости обучения.
В процессе работы алгоритма коэффициент скорости обучения постепенно уменьшается, чтобы каждый новый входной вектор оказывал все меньшее влияние на кластер.
Сеть Хопфилда
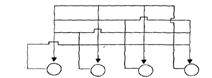

Сеть Хопфилда имеет следующие характеристики:
· Один слой элементов.
· Каждый элемент связывается со всеми другими эл-ми,но элемент не связывается с самим собой.
· За один шаг обновляется только один элемент.
· Элементы обновляются в случайном порядке, но в среднем каждый элемент должен обновляться в одной и той же мере.
· Вывод элемента ограничен биполярными значениями.
· Выбранный элемент получает взвешенные сигналы всех остальных элементов и изменяет своё состояние. Комбинированный вид элемента вычисляется по формуле: 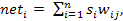 где
где  обозначает состояние элемента с номером i. Когда элемент обновляется, его состояние изменяется в соответствии с правилом
обозначает состояние элемента с номером i. Когда элемент обновляется, его состояние изменяется в соответствии с правилом
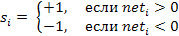
Если комбинированный ввод оказывается равным нулю, то элемент остаётся в состоянии, в котором он пребывал перед обновлением.
· Критерий остановки: Когда ни один из нейронов после обновления не поменяет своего состояния
Создаётся матрица, задающая весовые значения для сети Хопфилда, в которой все диагональные элементы должны быть установлены равными нулю (поскольку диагональные элементы задают автосвязи нейронов, а нейроны сами с собой не связаны). Таким образом, весовая матрица, соответствующая значению вектора x, задаётся формулой  .
.
Генетические алгоритмы.
Генетический алгоритм работает с популяцией особей, в хромосоме каждой из которых закодировано возможное решение задачи.
Для того чтобы оценить качество закодированных решений используют функцию приспособленности или фитнес-функцию.
В каждом поколении генетического алгоритма реализуется:
1. Формирование начальной популяции. Как правило, начальная популяция формируется случайным образом. При этом гены инициализируются случайными значениями.
2. Селекция. Селекция (отбор) необходима, чтобы выбрать более приспособленныхособей для скрещивания в репродуктивное множество. Существует множество вариантов селекции. Наиболее известные из них:
- Рулеточная селекция. В данном варианте селекции вероятность i -й особи принять участие в скрещивании  пропорциональна значению ее приспособленности
пропорциональна значению ее приспособленности  и равна
и равна  .Процесс отбора особей для скрещивания напоминает игру в «рулетку». Рулеточный круг делится на сектора, причем площадь i -го сектора пропорциональна значению . После этого n раз «вращается» рулетка, где n – размер популяции, и по сектору, на котором останавливается рулетка, определяется особь, выбранная для скрещивания.
.Процесс отбора особей для скрещивания напоминает игру в «рулетку». Рулеточный круг делится на сектора, причем площадь i -го сектора пропорциональна значению . После этого n раз «вращается» рулетка, где n – размер популяции, и по сектору, на котором останавливается рулетка, определяется особь, выбранная для скрещивания.
- Селекция усечением. При отборе усечением после вычисления значений приспособленности для скрещивания выбираются  лучших особей, где l – «порог отсечения», 0 < l < 1, n – размер популяции. Чем меньше значение l, тем сильнее давление селекции, т.е. меньше шансы на выживание у плохо приспособленных особей. Как правило, выбирают l в интервале от 0,3 до 0,7.
лучших особей, где l – «порог отсечения», 0 < l < 1, n – размер популяции. Чем меньше значение l, тем сильнее давление селекции, т.е. меньше шансы на выживание у плохо приспособленных особей. Как правило, выбирают l в интервале от 0,3 до 0,7.
- Турнирный отбор. В случае использования турнирного отбора для скрещивания отбираются n особей. Для этого из популяции случайно выбираются t особей, и самая приспособленная из них допускается к скрещиванию. Говорят, что формируется турнир из t особей, t размер турнира. Эта операция повторяется n раз. Чем больше значение t, тем больше давление селекции. Вариант турнирного отбора, когда t = 2, называют бинарным турниром. Типичные значения размера турнира t = 2, 3, 4, 5.
3. Скрещивание. Отобранные в результате селекции особи (называемые родительскими) скрещиваются и дают потомство. Хромосомы потомков формируется в результате обмена частями хромосом между родительскими особями.
4. Формирование нового поколения. В результате скрещивания создаются потомки, которые формируют популяцию следующего поколения. Отметим, что обновленная таким образом популяция не обязательно должна включать одних только особей-потомков. Можно включить в новую популяцию наиболее приспособленные родительские особи (элитные особи). Использование элитных особей позволяет увеличить скорость сходимости генетического алгоритма.
5. Мутация. Оператор мутации используется для внесения случайных изменений в хромосомы особей. Это позволяет «выбираться» из локальных экстремумови, тем самым, эффективнее исследовать пространство поиска. Вероятность применения мутации невысока.
Работа генетического алгоритма представляет итерационный процесс, который продолжается до тех пор, пока не выполнится заданное число пок-ий или любой другой критерий остановки.
Наиболее популярное применение генетических алгоритмов - оптимизация многопараметрических функций. Многие реальные задачи могут быть сформулированы как поиск оптимального значения, где значение - сложная функция, зависящая от некоторых входных параметров. В некоторых случаях, представляет интерес найти те значения параметров, при которых достигается наилучшее точное значение функции. В других случаях, точный оптимум не требуется - решением может считаться любое значение, которое лучше некоторой заданное величины. В этом случае, генетические алгоритмы - часто наиболее приемлемый метод для поиска "хороших" значений. Сила генетического алгоритма заключена в его способности манипулировать одновременно многими параметрами, эта особенность ГА использовалось в сотнях прикладных программ, включая проектирование самолетов, настройку параметров алгоритмов и поиску устойчивых состояний систем нелинейных дифференциальных уравнений.
Базы данных:
Теория нормализации.
Под нормализацией отношения подразумевается процесс приведения отношения к одной из так называемых нормальных форм (или в дальнейшем НФ).
При проектировании баз данных упор в первую очередь делается на достоверность и непротиворечивость хранимых данных, причем эти свойства не должны утрачиваться в процессе работы с данными, т.е. после многочисленных изменений, удалений и дополнений данных по отношению к первоначальному состоянию БД.
Для поддержания БД в устойчивом состоянии используется ряд механизмов, которые получили обобщенное название средств поддержки целостности. Эти механизмы применяются как статически (на этапе проектирования БД), так и динамически (в процессе работы с БД). Приведение структуры БД в соответствие ограничениям, которым она должна удовлетворять в процессе создания, независимо от наполнения ее данными - это и есть нормализация.
В целом суть этих ограничений весьма проста: каждый факт, хранимый в БД, должен храниться один-единственный раз, поскольку дублирование может привести (и на практике непременно приводит, как только проект приобретает реальную сложность) к несогласованности между копиями одной и той же информации. Следует избегать любых неоднозначностей, а также избыточности хранимой информации.
Следует заметить, что в процессе нормализации постоянно встречается ситуация, когда отношение приходится разложить на несколько других отношений. Поэтому более корректно было бы говорить о нормализации не отдельных отношений, а всей их совокупности в БД.
Процесс нормализации – последовательное преобразование исходной БД к НФ, при этом каждая следующая НФ обязательно включает в себя предыдущую (что, собственно, и позволяет разбить процесс на этапы и производить его однократно, не возвращаясь к предыдущим этапам).
Всего в реляционной теории насчитывается 6 НФ:
1. Первая нормальная форма (1NF):
- запрещает повторяющиеся столбцы (содержащие одинаковую по смыслу информацию);
- запрещает множественные столбцы (содержащие значения типа списка и т.п.);
- требует определить первичный ключ для таблицы, то есть тот столбец или комбинацию столбцов, которые однозначно определяют каждую строку.
2. Вторая нормальная форма (2NF):
Требует, чтобы неключевые столбцы таблиц зависели от первичного ключа в целом, но не от его части. Маленькая ремарочка: если таблица находится в первой нормальной форме и первичный ключ у нее состоит из одного столбца, то она автоматически находится и во второй нормальной форме.
3. Третья нормальная форма (3NF):
Необходимо, чтобы неключевые столбцы в ней не зависели от других неключевых столбцов, а зависели только от первичного ключа. Самая распространенная ситуация в данном контексте - это расчетные столбцы, значения которых можно получить путем каких-либо манипуляций с другими столбцами таблицы. Для приведения таблицы в третью нормальную форму такие столбцы из таблиц надо удалить.
4. Нормальная форма Бойса — Кодда (BCNF):
Требует, чтобы в таблице был только один потенциальный первичный ключ. Чаще всего у таблиц, находящихся в третьей нормальной форме, так и бывает, но не всегда. Если обнаружился второй столбец (комбинация столбцов), позволяющий однозначно идентифицировать строку, то для приведения к нормальной форме Бойса-Кодда такие данные надо вынести в отдельную таблицу.
5. Четвёртая нормальная форма (4NF):
Для приведения таблицы, находящейся в нормальной форме Бойса-Кодда, к четвертой нормальной форме необходимо устранить имеющиеся в ней многозначные зависимости. То есть обеспечить, чтобы вставка / удаление любой строки таблицы не требовала бы вставки / удаления / модификации других строк этой же таблицы.
6. Пятая нормальная форма (5NF):
Форма, в которой устранены зависимости соединения (таблицу разбивают еще на 3 и более). В большинстве случаев практической пользы от нормализации таблиц до пятой нормальной формы не наблюдается.
На практике, как правило, ограничиваются 3НФ, ее оказывается вполне достаточно для создания надежной схемы БД.
В теории баз данных говорится о том, что схема базы данных должна быть полностью нормализована. При работе с полностью нормализованными базами данных необходимо применять весьма сложные SQL-запросы, что приводит к обратному эффекту - замедлению работы базы данных. Поэтому иногда для упрощения запросов даже прибегают к обратной процедуре – денормализации.
SQL не зависит от конкретной СУБД. Несмотря на наличие диалектов и различий в синтаксисе, в большинстве своём тексты SQL-запросов, содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую.
Явное и неявное завершение
Выполняя предыдущие упражнения, вы ввели несколько команд COMMIT. Однако явный ввод команды—это лишь один из способов завершения изменений в базе данных. Некоторые команды выполняют завершение предыдущих команд, не дожидаясь ваших указаний, т.е. неявно. Говоря конкретнее, любые команды DDL (например, CREATE TABLE или DROP TABLE) неявно завершают изменение всех не сохраненных данных перед выполнением своих
функций. Выход из среды разработки к автоматическому завершению ваших изменений.
7) Двухфазный протокол блокирования и его корректность.
«Блокировка», в отличие от «взаимоблокировки», явление совершенно обычное, и означает лишь то, что транзакция получит некий ресурс в свое распоряжение не сразу, а чуть-чуть подождав, пока другая транзакция не снимет с этого ресурса блокировку, наложенную ранее.
Блокировка не может быть наложена на несколько объектов одновременно. Между наложением блокировок на два разных объекта, теоретически, может произойти что угодно, даже если эти объекты – две записи в одной и той же таблице, расположенные рядом. С помощью блокировок обеспечивается синхронизация доступа к ресурсам. Под ресурсами или объектами будет иметься в виду какой-нибудь объект БД – запись, страница данных или таблица. Синхронизация происходит благодаря тому, что прежде чем произвести с объектом какие-то действия (прочитать или изменить), на него накладывается блокировка. Она запрещает изменять или даже читать объект другим транзакциям до тех пор, пока транзакция, наложившая блокировку, не завершит работу с этим объектом. Синхронизация доступа нужна для того, чтобы не допустить воздействия одной транзакции на другую при одновременном выполнении. Иными словами, в идеальном случае, транзакция, даже если их одновременно выполняется множество, должна дать такой же результат, как если бы она выполнялась одна, а других транзакций не было вообще. Однако следует помнить, что в большинстве серверов такой идеальный режим работы параллельных транзакций «по умолчанию» не включен.
Типы блокировок
Поскольку запрос может быть как на чтение, так и на запись, то блокировки для этих случаев так же отличаются, вдобавок существует еще и промежуточный тип блокировки.
Read Lock – блокировка чтения, она же «коллективная», она же «разделяемая». Смысл этой блокировки в том, что она совместима с точно такими же блокировками. Иными словами, на один и тот же ресурс может быть наложено сколь угодно много коллективных блокировок. Обычно эта блокировка называется Shared.
Write Lock – блокировка записи, она же «монопольная», она же «эксклюзивная». Эта блокировка не совместима ни с Read Lock, ни сама с собой, ни с каким либо другим типом блокировок. То есть в один момент времени на один объект может быть наложена только одна монопольная блокировка. Обычно называется Exclusive.
Update Lock – это промежуточная блокировка, блокировка «обновления». Она совместима с Read Lock, но не совместима с Write Lock и сама с собой. Иными словами на один объект могут быть одновременно наложены одна блокировка обновления, ни одной монопольной блокировки и сколь угодно много коллективных блокировок. Этот тип блокировок введен как раз для снижения риска возникновения взаимоблокировки.
Для поддержания согласованного состояния данных необходимо обеспечить синхронизацию доступа. Синхронизация достигается путем применения алгоритмов управления одновременным доступом:
· свойство сериализуемости - если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций.
· свойство изолированности выполнения транзакций, заключающееся в том, что результат транзакции не может зависеть (т. е. изолирован) от других параллельно выполняемых транзакций.
Взаимоблокировка
Большинство способов обеспечения параллелизма, хотя бы отчасти основанных на блокировках, подвержено взаимоблокировкам (deadlock).
Взаимоблокировка, как можно понять из названия – это ситуация, когда транзакции блокируют друг друга таким образом, что дальнейшее выполнение невозможно. В силу протокола двухфазной блокировки ни одна из участвующих во взаимоблокировке транзакций не может отпустить уже захваченные ей ресурсы до того, как наложит блокировки на все, что ей необходимо. А получить все необходимые ресурсы мешают уже наложенные блокировки. Таким образом, получается замкнутый круг. Естественно, и транзакций, и объектов в общем случае может быть сколь угодно много. Разорвать такую блокировку без внешнего вмешательства невозможно, и если не предпринимать специальных усилий, то транзакции будут находиться в состоянии ожидания бесконечно долго. Разрешить подобную ситуацию можно лишь путем отмены хотя бы одной из транзакций.
Встроенные способы определения взаимоблокировок
Timeout based
Самый простой способ – это ввести некоторое фиксированное время ожидания (timeout), и если транзакция оказалась заблокированной больше этого времени, то считать, что она вошла в тупиковую ситуацию и отменять ее. Недостатки– нет гарантии, что отмененная транзакция была одной из участниц взаимоблокировки.
Wait-for graph based
Существуют и более удачный способ определения взаимоблокировок. Для этого менеджер блокировок строит направленный граф, который называется «графом ожидания». В вершинах этого графа находятся транзакции, а в ребрах – зависимости. Если в графе ожидания возникает цикл (T1->T2->…->Tn->T1), то T1 ждет сама себя, как и все остальные n транзакций в цикле, следовательно, транзакции заблокированы намертво. Сложность лишь в том, как часто менеджер блокировок должен проверять граф ожидания на наличие циклов. Но здесь, в отличие от предыдущего способа, гарантируется, что будет найдена именно мертвая блокировка, а также, что мы обнаружим все мертвые блокировки, а не только те, которые продержались достаточно долго.
Timestamp based
Существуют механизмы, позволяющие вообще не допускать тупиковых ситуаций при использовании протокола двухфазной блокировки, например, на основе временных меток Каждой транзакции присваивается временная метка, а далее возможно два варианта развития событий в зависимости от конкретной реализации.
1. «ожидание-гибель» (wait-die). Если транзакция T1 «старше» Т2, тогда транзакции Т1 разрешается пребывать в состоянии ожидания на блокировке. Если же Т1 «младше» T2, тогда Т1 откатывается.
2. «ранение-ожидание» (wound-wait). Если транзакция T1 «старше» T2, тогда T1 «ранит» T2; ранение обычно носит «смертельный» характер – транзакция Т2 откатывается, если только к моменту получения «ранения» T2 не оказывается уже завершенной. В этом случае Т2 «выживает» и отката не происходит. Если же Т1 «младше» Т2, тогда Т1 разрешается находиться в состоянии ожидания на блокировке.
Преимущества этого способа заключаются в первую очередь в том, что взаимоблокировки не допускаются в принципе. Этот способ несколько проще в реализации, нежели построение и отслеживание графа ожидания. И, наконец, отсутствует вероятность циклического рестарта отмененной транзакции, так как при откате временная метка сохраняется, и любая транзакция со временем гарантировано станет самой «старшей», а значит, ее не откатят.
Недостаток же этого способа заключается в том, что число откатов здесь гораздо больше, чем в реализации на основе графа ожидания.
Методы ведения журналов.
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя.
Бывают:
1. Мягкие сбои. Мягкие сбои можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания). Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя).
2. Жесткие сбои. Характеризуются потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. В этом случае требуется ликвидировать последствия только одной транзакции.
Для восстановления БД нужно располагать некоторой дополнительной информацией. Поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью, в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журналируются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода.
Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (протокола Write Ahead Log - WAL). Эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат транзакции. Для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу).
При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Архивная копия - это полная копия БД к моменту начала заполнения журнала. Восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя.
Файл журнала.
В файл журнала может помещаться следующая информация:
- Записи о транзакциях, включающие идентификатор транзакции;
- тип записи журнала (начало транзакции, операции вставки, обновления или удаления, отмена или фиксация транзакции);
- идентификатор элемента данных, вовлеченного в операцию обработки базы данных (операции вставки, удаления и обновления);
- копию элемента данных до операции, т.е. его значение до изменения (только операции обновления и удаления);
- копию элемента данных после операции, т.е. его значение после изменения (только для операций обновления и вставки);
- служебную информацию файла журнала, включающую указатели на предыдущую и следующую записи журнала для этой транзакции (все операции).
- Записи контрольных точек.
Очень часто файл журнала используется и для других целей, отличных от задач восстановления (например, для сбора сведений о текущей производительности, для аудита и т.д.). В этом случае в файл журнала может помещаться множество дополнительной информации (например, сведения об операциях чтения, о регистрации пользователей, завершении сеансов пользователей и т.д.).
Поскольку файл журнала транзакций имеет большое значение для процессов восстановления, он может создаваться в двух и даже в трех экземплярах, которые автоматически поддерживаются системой. В случае повреждения одной копии при восстановлении будет использоваться другая.
Один из подходов к автономной обработке файла журнала состоит в разделении оперативного файла журнала на две независимые части, организованные в виде файлов с произвольным доступом. Записи журнала помещаются в первый файл до тех пор, пока он не будет заполнен до установленного уровня (например, на 70%). Затем открывается второй файл, и все записи журнала для новых транзакций записываются уже в него. Сведения о старых транзакциях продолжают записывать в первый файл до тех пор, пока обработка всех старых транзакций не будет завершена. В этот момент первый файл закрывается и переводится в автономное состояние. Подобный подход упрощает восстановление отдельных транзакций, поскольку записи о каждой отдельной транзакции всегда содержатся в одном фрагменте файла журнала — либо в оперативном, либо в автономном. Следует отметить, что файл журнала потенциально является узким местом с точки зрения производительности любых систем, поэтому скорость записи информации в файл журнала может оказаться одним из важнейших факторов, определяющих общую производительность системы с базой данных.
Операционные системы:
Смежное размещение.
Простейший способ — хранить каждый файл как непрерывную последовательность блоков диска. При непрерывном расположении файл характеризуется адресом и длиной (в блоках). Файл, стартующий с блока b, занимает затем блоки b+1, b+2,... b+n-1.
Плюсы:
· Легко реализовать, так как выяснение местонахождения файла сводится к вопросу, где находится первый блок.
· Обеспечивает хорошую производительность, т.к. целый файл может быть считан за одну дисковую операцию.
Минусы:
· Не всегда имеется подходящий по размеру свободный фрагмент для нового файла.
· Непрерывное распределение внешней памяти неприменимо до тех пор, пока неизвестен максимальный размер файла. Иногда размер выходного файла оценить легко (при копировании). Чаще, однако, это трудно сделать, особенно в тех случаях, когда размер файла меняется.
Единственным приемлемым решением перечисленных проблем является периодическое уплотнение содержимого внешней памяти(дефрагментация, «сборка мусора»), цель кот. состоит в объединении свободных участков в один большой блок. Но это дорогостоящая операция, которую невозможно осуществлять слишком часто.
Т.о., когда содержимое диска постоянно изменяется, данный метод нерационален. Однако для стационарных ФС, например для ФС компакт-дисков, он вполне пригоден.
Связный список.
Внешняя фрагментация — основная проблема рассмотренного выше метода — м.б. устранена за счет представления файла в виде связного списка блоков диска. Запись в директории содержит указатель на первый и последний блоки файла (иногда в качестве варианта используется специальный знак конца файла — EOF). Каждый блок содержит указатель на следующий блок.

Плюсы:
· Любой свободный блок м.б. использован для удовлетворения запроса. Нет необходимости декларировать размер файла в момент создания. Файл может расти неограниченно.
Минусы:
· Во-первых, при прямом доступе к файлу для поиска i-го блока нужно осуществить несколько обращений к диску, последовательно считывая блоки от 1 до i-1, то есть выборка логически смежных записей, которые занимают физически несмежные секторы, может требовать много времени. Здесь мы теряем все преимущества прямого доступа к файлу.
· Во-вторых, данный способ не очень надежен. Наличие дефектного блока в списке приводит к потере информации в оставшейся части файла и потенциально к потере дискового пространства, отведенного под этот файл.
· Наконец, для указателя на следующий блок внутри блока нужно выделить место, что не всегда удобно. Емкость блока, традиционно являющаяся степенью двойки (многие программы читают и пишут блоками по степеням двойки), таким образом, перестает быть степенью двойки, так как указатель отбирает несколько байтов.
Таблица отображения файлов.
Одним из вариантов предыдущего способа является хранение указателей не в дисковых блоках, а в индексной таблице в памяти, которая называется таблицей отображения файлов (FAT — file allocation table)

По-прежнему существенно, что запись в директории содержит только ссылку на первый блок. Далее при помощи таблицы FAT можно локализовать блоки файла независимо от его размера. В тех строках таблицы, которые соответствуют последним блокам файлов, обычно записывается некоторое граничное значение, например EOF.
Главное достоинство данного подхода состоит в том, что по таблице отображения можно судить о физическом соседстве блоков, располагающихся на диске, и при выделении нового блока можно легко найти свободный блок диска, находящийся поблизости от других блоков данного файла.
Минусом данной схемы может быть необходимость хранения в памяти этой довольно большой таблицы.
Индексные узлы.
Наиболее распространенный метод выделения файлу блоков диска — связать с каждым файлом небольшую таблицу, называемую индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков файла. Запись в директории, относящаяся к файлу, содержит адрес индексного блока. По мере заполнения файла указатели на блоки диска в индексном узле принимают осмысленные значения.
Индексированное размещение широко распространено и поддерживает как последовательный, так и прямой доступ к файлу.
Обычно применяется комбинация одноуровневого и многоуровневых индексов. Первые несколько адресов блоков файла хранятся непосредственно в индексном узле, т.о., для маленьких файлов индексный узел хранит всю необходимую информацию об адресах блоков диска. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Данный блок содержит адреса дополнительных блоков диска. Если этого недостаточно, используется блок двойной (тройной) косвенной адресации, который содержит адреса блоков косвенной адресации.

Ссылки:
· Жесткую ссылку невозможно отличить от файла, на который она указывает — для системы они идентичны. При удалении файла, на который есть несколько жестких ссылок, система не освобождает блоки до тех пор, пока существует хоть одна ссылка.
· Мягкая ссылка (символьная ссылка, или symlink) полностью отличается от жесткой: она является маленьким спец. файлом, который содержит путь к файлу.
Каталоги (директории):
1. Самая простая форма системы каталогов состоит из одного каталога, содержащего все файлы. Иногда он называется корневым каталогом, но поскольку он один-единственный, то имя особого значения не имеет. Эта система была широко распространена на первых персональных компьютерах. Преимущества такой схемы заключаются в ее простоте и возможности быстрого нахождения файлов, поскольку поиск ведется всего в одном месте.
2. Дерево каталогов — Такой подход позволяет иметь столько каталогов, сколько необходимо для группировки файлов естественным образом.

|
|
|





