Курс «Информатика»
III семестр: «Базы данных»
Области применения, преимущества и недостатки иерархической, сетевой и реляционной моделей данных.
Иерархическая модель
Логическая модель данных в виде древовидной структуры, представляющая собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф). Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня. Узел — информационная модель элемента, находящегося на данном уровне иерархии.
1968 - Типичным представителем иерархических систем является Information Management System (IMS) фирмы IBM. Первая версия этого продукта вышла в свет в 1968 году.
Основные понятия
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи.
Операции над данными
- ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- УДАЛИТЬ некоторую запись и все подчиненные ей записи.
- ИЗВЛЕЧЬ:
- извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
- извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева) В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название "навигационного".
Ограничения целостности
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое под
Пример модели
Рассмотрим следующую модель данных предприятия (смотреть рисунок ниже): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры: заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b)).

Из этого примера видны недостатки иерархических БД:
- Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
- Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию.
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
СЕТЕВАЯ МОДЕЛЬ
Сетевая модель данных - это логическая модель данных, представляющая их сетевыми структурами типов записей и связанные отношениями мощности один-к-одному или один-ко-многим.
В отличие от реляционной модели, связи в ней моделируются наборами, которые реализуются с помощью указателей. Сетевые модели данных являются расширенной версией иерархической модели, однако основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Сетевую модель можно представить как граф узлами, которого является запись, а ребрами - набор. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД.
В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели был создан в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Типичным представителем систем, основанных на сетевой модели данных, является СУБД IDMS (Integrated Database Management System), разработанная компанией Cullinet Software, Inc. и изначально ориентированная на использования на мейнфреймах компании IBM. Архитектура системы основана на предложениях DBTG организации CODASYL.
Пример сетевой базы данных
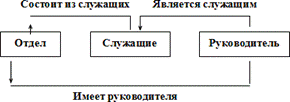
На рисунке показан простой пример схемы сетевой БД.
На этом рисунке показаны три типа записи: Отдел, Служащие и Руководитель и три типа связи: Состоит из служащих, Имеет руководителя и Является служащим.
В типе связи Состоит из служащих типом записи-предком является Отдел, а типом записи-потомком – Служащие (экземпляр этого типа связи связывает экземпляр типа записи Отдел со многими экземплярами типа записи Служащие, соответствующими всем служащим данного отдела).
В типе связи Имеет руководителя типом записи-предком является Отдел, а типом записи-потомком – Руководитель (экземпляр этого типа связи связывает экземпляр типа записи Отдел с одним экземпляром типа записи Руководитель, соответствующим руководителю данного отдела).
Наконец, в типе связи Является служащим типом записи-предком является Руководитель, а типом записи-потомком – Служащие (экземпляр этого типа связи связывает экземпляр типа записи Руководитель с одним экземпляром типа записи Служащие, соответствующим тому служащему, которым является данный руководитель).
Преимущества
- Стандартизация. Появление стандарта CODASYL, который определил базовые понятия модели и формальный язык описания.
- Быстродействие. Быстродействие сетевых баз данных сравнимо с быстродействием иерархических баз данных.
- Гибкость. Множественные отношения предок/потомок позволяют сетевой базе данных хранить данные, структура которых была сложнее простой иерархии.
- Универсальность. Выразительные возможности сетевой модели данных являются наиболее обширными в сравнении с остальными моделями.
- Возможность доступа к данным через значения нескольких отношений (например, через любые основные отношения).
Недостатки
- Жесткость. Наборы отношений и структуру записей необходимо задавать наперёд. Изменение структуры базы данных ведет за собой перестройку всей базы данных.. Связи закреплены в записях в виде указателей. При появлении новых аспектов использования этих же данных может возникнуть необходимость установления новых связей между ними. Это требует введения в записи новых указателей, т.е. изменения структуры БД, и, соответственно, переформирования всей базы данных.
- Сложность. Сложная структура памяти.
Реляционная модель
Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье "A Relational Model of Data for Large Shared Data Banks" (русский перевод статьи, в которой она впервые описана, опубликован в журнале "СУБД" N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В упомянутой статье Е.Ф. Кодда утверждается, что "реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления". Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation – "отношение").
В состав реляционной модели данных обычно включают теорию нормализации.
Основные понятия реляционной модели данных. Фундаментальные свойства отношений.
Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье "A Relational Model of Data for Large Shared Data Banks" (русский перевод статьи, в которой она впервые описана, опубликован в журнале "СУБД" N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД.
В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В упомянутой статье Е.Ф. Кодда утверждается, что "реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления". Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation – "отношение").
В состав реляционной модели данных обычно включают теорию нормализации.
Пример
Предположим, создаётся таблица бронирования для теннисных кортов на день: {Номер корта, Время начала, Время окончания, Тариф, Член клуба}. Тариф зависит от выбранного корта и членства в клубе, для каждого из кортов имеется тариф для членов теннисного клуба и для сторонних клиентов. Тарифы для кортов не повторяются.
Таким образом, возможны следующие составные первичные ключи: {Номер корта, Время начала}, {Номер корта, Время окончания}, {Тариф, Время начала}, {Тариф, Время окончания}.
Таблица соответствует второй и третьей нормальной форме. Требования второй нормальной формы (2NF) выполняются, так как все атрибуты входят в какой-то из потенциальных ключей, а неключевых атрибутов в отношении нет. Также нет и транзитивных зависимостей, что соответствует требованиям третьей нормальной формы. (3NF).
Тем не менее, существует функциональная зависимость тарифа от номера корта. То есть, по ошибке можно нарушить логическую целостность и, например, приписать тариф Premium для первого корта, хотя тариф Premium может относиться только ко второму корту.
Можно улучшить структуру, разбив таблицу на две: {Номер корта, Время начала, Время окончания, Член клуба} и {Тариф, Номер корта, Член клуба}. Данное отношение будет соответствовать BCNF.
Пример
Предположим, что рестораны производят разные виды пиццы, а службы доставки ресторанов работают только в определенных районах города. Составной первичный ключ соответствущей переменной отношения включает три атрибута: {Ресторан, Вид пиццы, Район доставки}.
Такая переменная отношения не соответствует 4НФ, так как существует следующая многозначная зависимость:
- {Ресторан}
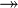 {Вид пиццы}
{Вид пиццы} - {Ресторан} {Район доставки}
То есть, например, при добавлении нового вида пиццы придется внести по одному новому кортежу для каждого района доставки. Возможна логическая аномалия, при которой определенному виду пиццы будут соответствовать лишь некоторые районы доставки из обслуживаемых рестораном районов.
Для предотвращения аномалии нужно декомпозировать отношение, разместив независимые факты в разных отношениях. В данном примере следует выполнить декомпозицию на {Ресторан, Вид пиццы} и {Ресторан, Район доставки}.
Однако если к исходной переменной отношения добавить атрибут, функционально зависящий от потенциального ключа, например цену с учётом стоимости доставки ({Ресторан, Вид пиццы, Район доставки} → Цена), то полученное отношение будет находиться в 4НФ и его уже нельзя подвергнуть декомпозиции без потерь. Указанные выше многозначные зависимости в данном случае называются внедрёнными зависимостями.
Определение
Переменная отношения находится в шестой нормальной форме тогда и только тогда, когда она удовлетворяет всем нетривиальным зависимостям соединения. Из определения следует, что переменная находится в 6НФ тогда и только тогда, когда она неприводима, то есть не может быть подвергнута дальнейшей декомпозиции без потерь. Каждая переменная отношения, которая находится в 6НФ, также находится и в 5НФ.
Пример
Идея «декомпозиции до конца» выдвигалась до начала исследований в области хронологических данных, но не нашла поддержки. Однако для хронологических баз данных максимально возможная декомпозиция позволяет бороться с избыточностью и упрощает поддержание целостности базы данных.
Для хронологических баз данных определены U_операторы, которые распаковывают отношения по указанным атрибутам, выполняют соответствующую операцию и упаковывают полученный результат. В данном примере соединение проекций отношения должно производится при помощи оператора U_JOIN.
| Работники
|
| Таб. №
| Время
| Должность
| Домашний адрес
|
|
| [01-01-2000:10-02-2003]
| слесарь
| ул. Ленина, 10
|
|
| [11-02-2003:15-06-2006]
| слесарь
| ул. Советская, 22
|
|
| [16-06-2006:05-03-2009]
| бригадир
| ул. Советская, 22
|
Переменная отношения «Работники» не находится в 6НФ и может быть подвергнута декомпозиции на переменные отношения «Должности работников» и «Домашние адреса работников».
| Должности работников
|
| Таб. №
| Время
| Должность
|
|
| [01-01-2000:15-06-2006]
| слесарь
|
|
| [16-06-2006:05-03-2009]
| бригадир
|
| Домашние адреса работников
|
| Таб. №
| Время
| Домашний адрес
|
|
| [01-01-2000:10-02-2003]
| ул. Ленина, 10
|
|
| [11-02-2003:05-03-2009]
| ул. Советская, 22
|
Физическое проектирование
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т.д.
Вопросы обеспечения целостности базы данных.
Одной из важнейших задач, решаемой СУБД, является поддержание в любой момент времени взаимной непротиворечивости, правильности и точности данных, хранящихся в БД. Этот процесс называется обеспечением целостности базы данных.
Следует различать проблемы обеспечения целостности базы данных и защиты базы данных от несанкционированного доступа (см. п. 6). Поддержание целостности базы данных может интерпретироваться как защита данных от неправильных действий пользователей или некоторых случайных внешних воздействий. В обеих ситуациях нарушения целостности базы данных имеют непреднамеренный характер.
Целостность базы данных может быть нарушена в результате сбоя оборудования; программной ошибки в СУБД, операционной системе или прикладной программе; неправильных действий пользователей. Эти ситуации могут возникать даже в хорошо проверенных и отлаженных системах, несмотря на применяемые системы контроля. Поэтому СУБД должна иметь средства обнаружения таких ситуаций и восстановления правильного состояния базы данных.
Целостность базы данных поддерживается с помощью набора специальных логических правил, накладываемых на данные, называемых ограничениями целостности. Ограничения целостности представляют собой утверждения о допустимых значениях отдельных информационных единиц и связях между ними. Ограничения целостности хранятся в словаре БД.
Ограничения целостности могут определяться(например):
· спецификой предметной области (возраст сотрудников организации может находиться в диапазоне от 16 до 80 лет);
· непосредственно информационными характеристиками (артикул товара должен быть целым числом).
В процессе работы пользователя с базой данных СУБД проверяет, соответствуют ли выполняемые действия установленным ограничениям целостности. Действия, нарушающие целостность базы данных, отменяются, при этом обычно выводится соответствующее информационное сообщение.
Рассмотрим проблемы поддержания целостности баз данных на примере реляционной СУБД. Следует отметить, что приводимые далее рассуждения в общем виде справедливы и для других моделей данных
Ограничения целостности в реляционной модели данных могут относиться к полям, записям, таблицам, связям между таблицами.
Значение SQL
Официальный стандарт языка SQL был опубликован Американским институтом национальных стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартам (International Standards Organization — ISO) в 1986 году и значительно расширен в 1992 году. Кроме того, SQL является федеральным стандартом США по обработке информации (FIPS — Federal Information Processing Standard) и, следовательно, соответствие ему является одним из основных требований, содержащихся в больших правительственных контрактах, относящихся к области вычислительной техники. В Европе стандарт X/OPEN для переносимой среды программирования на основе операционной системы UNIX включает в себя SQL в качестве стандарта для доступа к базам данных. SQL Access Group — консорциум поставщиков компьютерного оборудования и баз данных — определил для SQL стандартный интерфейс вызовов функций, который является основой протокола ODBC компании Microsoft и входит также в стандарт X/OPEN. Эти стандарты служат как бы официальной печатью, одобряющей SQL, и они ускорили завоевание им рынка.
Язык SQL
SQL является инструментом, предназначенным для обработки и чтения данных, содержащихся в компьютерной базе данных. SQL - это сокращенное название структурированного языка запросов (Structured Query Language). Как следует из названия, SQL является языком программирования, который применяется для организации взаимодействия пользователя с базой данных. На самом деле SQL работает только с базами данных одного определенного типа, называемых реляционными. На рис. 2.1 изображена схема работы SQL
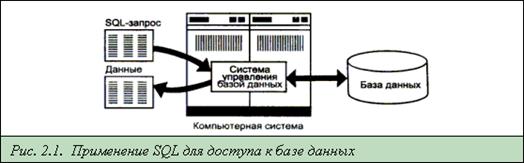
Согласно этой схеме, в вычислительной системе имеется база данных, в которой хранится важная информация. Если вычислительная система относится к сфере бизнеса, то в базе данных может храниться информация о материальных ценностях, выпускаемой продукции, объемах продаж и зарплате. В базе данных на персональном компьютере может храниться информация о выписанных чеках, телефонах и адресах или информация, извлеченная из более крупной вычислительной системы. Компьютерная программа, которая управляет базой данных, называется системой управления базой данных, или СУБД.
Если пользователю необходимо прочитать данные из базы данных, он запрашивает их у СУБД с помощью SQL. СУБД обрабатывает запрос, находит требуемые данные и посылает их пользователю. Процесс запрашивания данных и получения результата называется запросом к базе данных: отсюда и название — структурированный язык запросов.
Однако это название не совсем соответствует действительности. Во-первых, сегодня SQL представляет собой нечто гораздо большее, чем простой инструмент создания запросов, хотя именно для этого он и был первоначально предназначен. Несмотря на то, что чтение данных по-прежнему остается одной из наиболее важных функций SQL, сейчас этот язык используется для реализации всех функциональных возможностей, которые СУБД предоставляет пользователю, а именно:
- Организация данных. SQL дает пользователю возможность изменять структуру представления данных, а также устанавливать отношения между элементами базы данных.
- Чтение данных. SQL дает пользователю или приложению возможность читать из базы данных содержащиеся в ней данные и пользоваться ими.
- Обработка ванных. SQL дает пользователю или приложению возможность изменять базу данных, т.е. добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся в ней данные.
- Управление доступом. С помощью SQL можно ограничить возможности пользователя по чтению и изменению данных и защитить их от несанкционированного доступа.
- Совместное использование данных. SQL координирует совместное использование данных пользователями, работающими параллельно, чтобы они не мешали друг другу.
- Целостность данных. SQL позволяет обеспечить целостность базы данных, защищая ее от разрушения из-за несогласованных изменений или отказа системы.
Таким образом, SQL является достаточно мощным языком для взаимодействия с СУБД.
Во-вторых, SQL — это не полноценный компьютерный язык типа COBOL, FORTRAN или С. В SQL нет оператора IF для проверки условий, нет оператора GOTO для организации переходов и нет операторов DO или FOR для создания циклов. SQL является подъязыком баз данных, в который входит около тридцати операторов, предназначенных для управления базами данных. Операторы SQL встраиваются в базовый язык, например COBOL, FORTRAN или С, и дают возможность получать доступ к базам данных. Кроме того, из такого языка, как С, операторы SQL можно посылать СУБД в явном виде, используя интерфейс вызовов функций.
Наконец, SQL — это слабо структурированный язык, особенно по сравнению с такими сильно структурированными языками, как С или Pascal. Операторы SQL напоминают английские предложения и содержат "слова-пустышки", не влияющие на смысл оператора, но облегчающие его чтение. В SQL почти нет нелогичностей, к тому же имеется ряд специальных правил, предотвращающих создание операторов SQL, которые выглядят как абсолютно правильные, но не имеют смысла.
Несмотря на не совсем точное название, SQL на сегодняшний день является единственным стандартным языком для работы с реляционными базами данных. SQL — это достаточно мощный и в то же время относительно легкий для изучения язык.
Роль SQL
Сам по себе SQL не является ни системой управления базами данных, ни отдельным программным продуктом. Нельзя пойти в компьютерный магазин и "купить SQL". SQL — это неотъемлемая часть СУБД, инструмент, с помощью которого осуществляется связь пользователя с ней. На рис. 2.2. изображена структурная схема типичной СУБД, компоненты которой соединяются в единое целое с помощью SQL (своего рода "клея").

Ядро базы данных является сердцевиной СУБД; оно отвечает за физическое структурирование и запись данных на диск, а также за физическое чтение данных с диска. Кроме того, оно принимает SQL-запросы от других компонентов СУБД (таких как генератор форм, генератор отчетов или модуль формирования интерактивных запросов), от пользовательских приложений и даже от других вычислительных систем. Как видно из рисунка, SQL выполняет много различных функций:
- SQL — интерактивный язык запросов. Пользователи вводят команды SQL в интерактивные программы, предназначенные для чтения данных и отображения их на экране. Это удобный способ выполнения специальных запросов.
- SQL — язык программирования баз данных. Чтобы получить доступ к базе данных, программисты вставляют в свои программы команды SQL. Эта методика используется как в программах, написанных пользователями, так и в служебных программах баз данных (таких как генераторы отчетов и инструменты ввода данных).
- SQL — язык администрирования баз данных. Администратор базы данных, находящейся на мини-компьютере или на большой ЭВМ, использует SQL для определения структуры базы данных и управления доступом к данным.
- SQL — язык создания приложений клиент/сервер, и программах для персональных компьютеров SQL используется для организации связи через локальную сеть с сервером базы данных, в которой хранятся совместно используемые данные. В большинстве новых приложений используется архитектура клиент/сервер, которая позволяет свести к минимуму сетевой трафик и повысить быстродействие как персональных компьютеров, так и серверов баз данных.
- SQL — язык распределенных баз данных. В системах управления распределенными базами данных SQL помогает распределять данные среди нескольких взаимодействующих вычислительных систем. Программное обеспечение каждой системы посредством использования SQL связывается с другими системами, посылая им запросы на доступ к данным.
- SQL — язык шлюзов базы данных. В вычислительных сетях с различными СУБД SQL часто используется в шлюзовой программе, которая позволяет СУБД одного типа связываться с СУБД другого типа.
Таким образом, SQL превратился в полезный и мощный инструмент, обеспечивающий людям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Достоинства SQL
SQL — это легкий для понимания язык и в то же время универсальное программное средство управления данными.
Успех языку SQL принесли следующие его особенности:
• независимость от конкретных СУБД;
• переносимость с одной вычислительной системы на другую;
• наличие стандартов;
• одобрение компанией IBM (СУБД DB2);
• поддержка со стороны компании Microsoft (протокол ODBC);
• реляционная основа;
• высокоуровневая структура, напоминающая английский язык;
• возможность выполнения специальных интерактивных запросов:
• обеспечение программного доступа к базам данных;
• возможность различного представления данных;
• полноценность как языка, предназначенного для работы с базами данных;
• возможность динамического определения данных;
• поддержка архитектуры клиент/сервер.
Все перечисленные выше факторы явились причиной того, что SQL стал стандартным инструментом для управления данными на персональных компьютерах, мини-компьютерах и больших ЭВМ. Ниже эти факторы рассмотрены более подробно.
Однотабличные запросы SQL.
Если вы впервые встречаетесь с SQL, то необходимо ознакомиться с основными концепциями, которые нужно понять.
В общих терминах, «SQL база данных» является общим названием для реляционной системы управления базами данных (РСУБД). Для некоторых систем, «база данных» также относится к группе таблиц, данных, конфигурационной информации, которые являются неотъемлемо отдельной частью от других, подобных конструкций. В этом случае, каждая инсталляция SQL базы данных может состоять из нескольких баз данных. В других системах, они упомянуты как таблицы.
Таблица – конструкция базы данных, которая состоит из столбцов, содержащих строки данных. Обычно таблицы созданы для того, чтобы содержать связанную информацию. В пределах той же самой базы данных могут быть созданы несколько таблиц.
Каждый столбец представляет собой атрибут или совокупность атрибутов объектов, например идентификационные номера служащих, рост, цвет машин и т.п. Часто в отношении столбца используется термин поле с указанием имени, например «в поле Name». Поле строки является минимальным элементом таблицы. Каждый столбец в таблице имеет определенное имя, тип данных и размер. Имена столбцов должны быть уникальны в пределах таблицы.
Каждая строка (или запись) представляет собой совокупность атрибутов конкретного объекта, например, в строке может содержаться идентификационный номер служащего, размер его зарплаты, год его рождения и т.д. Строки таблиц не имеют названий. Чтобы обратиться к конкретной строке, пользователю необходимо указать какой-то атрибут (или набор атрибутов), уникально ее идентифицирующий.
Одной из важнейших операций, которые выполняются при работе с данными, является выборка хранящейся в базе данных информации. Для этого пользователь должен выполнить запрос (query).
Теперь давайте рассмотрим основные типы запросов к базе данных, которые сосредоточены на манипуляции данными в пределах базы. Для наших целей, все примеры приведены в стандартном SQL, дабы соответствовать любой среде.
Типы запросов данных
Есть четыре основных типа запросов данных в SQL, которые относятся к так называемому языку манипулирования данными (Data Manipulation Language или DML):
- SELECT – выбрать строки из таблиц;
- INSERT – добавить строки в таблицу;
- UPDATE – изменить строки в таблице;
- DELETE – удалить строки в таблице;
Каждый из этих запросов имеет различные операторы и функции, которые используются для того, чтобы произвести какие-то действия с данными. Запрос SELECT имеет самое большое количество опций. Существуют также дополнительные типы запросов, используемых вместе с SELECT, типа JOIN и UNION. Но пока, мы сосредоточимся только на основных запросах.
Логические операции
Логические операции в SQL задаются ключевыми словами, а не символами. Ниже мы рассмотрим следующие логические операции.
• IS NULL. EXISTS
• BETWEEN
• UNIQUE
• IN
• ALL И ANY
• LIKE
IS NULL
Ключевое слово is NULL используется для проверки равенства данного значения значению NULL. Например, если требуется узнать, кто из сотрудников не имеет пейджера, можно искать значения NULL в столбце PAGER таблицы EMPLOYEEJTBL.
Вот пример проверки равенства значения значению NULL.
Пример __________________________ Значение _____________
WHERE SALARY is NULL Для зарплаты не задано значение
Вот пример, в котором значение NULL не будет найдено.
Пример _________________________ Значение ______________
WHERE SALARY = NULL Зарплата имеет значение, равное
строке символов N-U-L-L
Ввод:
SELECT EMP_ID, LAST NAME, FXRST_NAME, PAGER
FROM EMPLOYEE_TBL
WHERE PAGER IS NULL;
Вывод:
EMP_ID LAST_NAME FIRST_NAME PAGER
311549902 STEPHENS TINA
442346889 PLEW LINDA
220984332 WALLACE MARIAH
443679012 SPURGEON TIFFANY
4 строки выбраны.
Вы должны понимать, что буквальная строка 'NULL' отличается от значения NULL. Посмотрите на следующий пример.
Ввод:
SELECT EMP_ID, LAST_NAME, FIRST_NAME, PAGER
FROM EMPLOYEE_TBL
WHERE PAGER = NULL;
Вывод:
О строк выбрано.
BETWEEN
Ключевое слово BETWEEN используется для поиска значений, попадающих в диапазон, заданный некоторыми минимальным и максимальным значениями. Эти минимальное и максимальное значения включаются в соответствующее условие.
Пример __________________________________ Значение ___________
WHERE SALARY BETWEEN '20000' Зарплата должна находиться в диапазоне
AND '30000' от 20000 до 30000, включая крайние значения диапазона
Ввод:
SELECT *
FROM PRODUCTS_TBL
WHERE BETWEEN 5.95 AND 14.5;
Вывод:
PROD_ID PROD_DESC COST
222 ПЛАСТИКОВЫЕ ТЫКВЫ 7.75
90 ФОНАРИ 14.5
15 КОСТЮМЫ В АССОРТИМЕНТЕ 10
1234 ЦЕПОЧКА ДЛЯ КЛЮЧЕЙ 5.95
4 строки выбраны.
Обратите внимание на то, что в вывод включены крайние значения 5. 95 и 14.5.
BETWEEN предполагает включение минимального и максимального значений диапазона в результаты запроса.
IN
Ключевое слово IN используется для сравнения значения с заданным списком буквальных значений. Чтобы возвратилось TRUE, сравниваемое значение должно совпадать хотя бы с одним значением из списка.
Пример __________________________________________ Значение ______
WHERE SALARY IN ('20000', Зарплата должна равняться 20000, 30000 или
'30000', '40000') 40000
Ввод:
SELECT *
FROM PRODUCTS_TBL
WHERE PROD_ID IN <'13','9','87','119');
Вывод:
PROD_ID PROD_DESC COST
13 ИСКУССТВЕННЫЕ ПАРАФИНОВЫЕ ЗУБЫ 1.1
9 СЛАДКАЯ КУКУРУЗА 1.35
87 ПЛАСТИКОВЫЕ ПАУКИ 1.05
119 МАСКИ В АССОРТИМЕНТЕ 4.95
4 строки выбраны.
То же самое можно получить, комбинируя условия с помощью ключевого слова OR, но с помощью IN результат получается быстрее.
LIKE
Ключевое слово LIKE используется для нахождения значений, похожих на заданное. В данном случае предполагается использование следующих двух знаков подстановки:
• знак процента (%);
• знак подчеркивания (_).
Знак процента представляет ноль, один или несколько символов. Знак подчеркивания представляет один символ или число. Знаки подстановки могут использоваться в комбинации.
Вот несколько примеров.
Пример _________________________ Значение _________________
WHERE SALARY LIKE '200%' Любое значение, начинающееся с 200
WHERE SALARY LIKE ' %200% ' Любое значение, имеющее 200 в любой позиции
WHERE SALARY LIKE '_00%' Любое значение, имеющее 00 во второй и третьей
позициях WHERE SALARY LIKE ' 2_%_%' Любое значение, начинающееся с 2 и состоящее
как минимум из трех символов
WHERE SALARY LIKE '%2' Любое значение, зак<





