Сравнение двух групп
Случай независимых выборок
Одной из обычных задач в биологических исследованиях является сравнение арифметических средних двух групп (например, экспериментальной и контрольной). Классическим методом, позволяющим ее решать, является t-тест Стьюдента, или просто «t-тест». Нулевая гипотеза, проверяемая в ходе данного теста, заключается в том, что обе группы происходят из одной генеральной совокупности; другими словами, что наблюдаемые различия между средними значениями сравниваемых выборок случайны и не вызваны действием изучаемого фактора. Тест Стьюдента относится к группе параметрических методов анализа. Его корректное применение требует выполнения трех условий:
обе выборки должны быть независимыми, т.е. свойства одной из них никак не должны быть связаны со свойствами другой (известно, например, что женщины в среднем ниже мужчин, однако это не является результатом того, что мужчины оказывают какое-то особое влияние на рост женщин – дело здесь в генетических особенностях пола);
обе выборки должны подчиняться нормальному закону распределения;
между дисперсиями выборок не должно быть статистически значимой разницы (однородность дисперсий).
К сожалению, многие исследователи-биологи игнорируют перечисленные условия при выполнении теста Стьюдента, что часто приводит к ошибочным результатам. Наиболее «опасным» является несоблюдение требования о нормальности распределения значений признака в сравниваемых группах.
Рассмотрим, как тест Стьюдента можно выполнить при помощи программы STATISTICA. На рис. 4.1 приведены данные о содержании гемоглобина в крови (г/л) больных сахарным диабетом и здоровых людей. Выборки сопоставимы по полу, возрасту и т.п. Применим t-тест для сравнения средних значений этих двух независимых выборок. (Примечание: в учебных целях допустим, что обе выборки распределены нормально, и что их дисперсии различаются незначительно).

Рисунок 4.1. Пример оформления данных для выполнения t -теста для независимых выборок.
Обратите внимание на то, как оформлены данные на рис. 4.1. В таблице имеются две переменные. Одна из них – группирующая (Groupingvariable) («Группа») – содержит коды, указывающие принадлежность данных о содержании гемоглобина к конкретной группе. Другая – т.н. зависимая переменная (Dependentvariable) («Гемоглобин») – содержит собственно данные. Возможен и другой вариант оформления – данные для каждой группы («Больные» и «Здоровые») можно было бы просто внести в отдельные столбцы, не используя группирующую переменную.
Для выполнения t-теста для независимых выборок необходимо выполнить следующие действия:
Запустить соответствующий модуль (рис. 4.2) из меню Statistics>Basicstatistics/Tables> t-test, independent, bygroups (если в таблице с данными есть группирующая переменная) или t-test, independent, byvariables (если данные внесены в самостоятельные столбцы). (Примечание: мы рассмотрим вариант теста, при котором группирующая переменная присутствует; рис. 4.1).
В открывшемся окне нажать кнопку Variables и указать программе, какая из переменных является группирующей, а какая – зависимой (рис. 4.3).
Нажать на кнопку Summary: T-tests (рис. 4.2).

Рисунок 4.2. Модуль t-теста для независимых выборок.

Рисунок 4.3. Выбор переменных для включения в t-тест.
В итоге программа создаст рабочую книгу, содержащую таблицу с результатами t-теста. Эта таблица имеет несколько столбцов (рис. 4.4):
Mean (Больные): среднее значение содержания гемоглобина в группе «Больные»;
Mean (Здоровые): среднее значение содержания гемоглобина в группе «Здоровые»;
t-value: значение рассчитанного программой t-критерия Стьюдента;
df: число степеней свободы;
P: вероятность ошибочно отвергнуть нулевую гипотезу об отсутствии различий между средними (см. выше). Фактически, это самый главный интересующий нас результат анализа. В рассматриваемом примере P > 0,05, на основании чего можно сделать вывод об отсутствии статистически значимых различий между средними значениями содержания гемоглобина из разных групп наблюдения.
Valid N (Северная): объем выборки «Больные»;
Valid N (Южная): объем выборки «Здоровые»;
Std. dev. (Больные): стандартное отклонение выборки «Больные»;
Std. dev. (Здоровые): стандартное отклонение выборки «Здоровые»;
F-ratio, Variances: значение F-критерия Фишера, с помощью которого проверяется гипотеза о равенстве дисперсий в сравниваемых выборках (см. выше условия применения теста Стьюдента);
P, Variances: вероятность ошибки для F-теста Фишера. Поскольку в нашем случае Р > 0,05, можно заключить, что дисперсии сравниваемых выборок не различаются (т.е. условие однородности дисперсий выполняется).

Рисунок 4.4. Результаты выполнения t-теста для независимых выборок.
Если значения признака в двух сравниваемых группах распределены ненормально, применение параметрического t-теста для их сравнения будет часто приводить к искаженным результатам. В таких случаях следует воспользоваться соответствующим непараметрическим аналогом теста Стьюдента. Для сравнения двух независимых ненормально распределенных выборок используется U-тест Манна-Уитни (Mann-Whitney U-test). В программе STATISTICA этот тест выполняется следующим образом:
В меню Statistics выбрать Nonparametrics, а затем Comparingtwoindependentsamples (Сравнение двух независимых выборок).
В появившемся окне (рис. 4.5) нажать на кнопку Variables и выбрать зависимую и независимую переменные (для примера воспользуемся теми же данными по содержанию гемоглобина в кровилюдей из разных групп, см. рис. 4.1).

Рисунок 4.5. Окно Comparingtwogroups модуля Nonparametrics (при сравнении независимых выборок).
Нажать на кнопку Mann-Whitney U-test или M-W U test. Внешний вид появляющегося после этого окна представлен на рис. 4.6. Самое главное, на что следует обратить внимание в итоговой таблице теста – это величина вероятности ошибки Р. При большом числе наблюдений в выборках (20 и более) значение Р необходимо искать в 5-м столбце таблицы (вслед за «Z»), иначе – в 7-м (вслед за «Z-adjusted»). При Р < 0,05 делается вывод о наличии статистически значимой разницы между сравниваемыми выборками (Примечание: в отличие от t-теста, тест Манна-Уитни сравнивает не средние значения выборок, а суммы рангов по каждой из них. Ранг – положение определенного значения изучаемого признака в упорядоченном по убыванию или возрастанию ряду).

Рисунок 4.6. Результаты выполнения теста Манна-Уитни.
Случай зависимых выборок
Для проверки эффективности двух новых препаратов был выполнен следующий эксперимент. Былов каждую из 27 лунок планшета было добавлено 10000 клеток. Затем в9 из них добавили используемый в практике препарат, в следующие 9 – препарат с модификацией 1, а в оставшиеся 9 – препарат с модификацией 2. Через 3 дня было посчитано количество клеток в каждой лунке. Полученные данные приведены в таблице 5.1. Вопрос: различается ли средний прирост клеточной культуры в зависимости от типа препарата?
С зависимыми выборками исследователь имеет дело каждый раз, когда измерения значений изучаемого признака выполняются на одних и тех же объектах. Рассмотрим следующий пример. Для выяснения эффективности нового лекарствау пациентов измеряли САД до применения препарата и после. Необходимо выяснить, различается ли уровень АД в зависимости от применения лекарства (рис. 4.7).
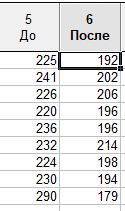
Рисунок 4.7. Пример оформления данных для выполнения t-теста для зависимых выборок.
Поскольку давление измерялось у одних и тех же людей, то выборки, полученные в результате двух описанных экспериментов, являются зависимыми. Чтобы сравнить средний уровень САД воспользуемся t-тестом для зависимых выборок. (Примечание: в учебных целях допустим, что условие о нормальности распределения данных выполняется). Для выполнения этого варианта t-теста необходимо:
ЗапуститьсоответствующиймодульизменюStatistics>Basicstatistics/Tables>t-test, dependentsamples.
В открывшемся окне нажать на кнопку Variables и указать программе первую (Firstvariable) и вторую (Secondvariable) переменные, участвующие в анализе.
Нажать на кнопку Summary: T-tests.
В результате появится таблица с результатами, очень похожая на ту, что мы уже видели при выполнении t-теста для независимых выборок. Она содержит следующие столбцы (рис. 4.8):
Mean – средние значения САД для каждой из сравниваемых групп;
Std. dv. – стандартные отклонения для каждой группы;
N – число наблюдений;
Diff. – средняя разница;
Std. dv. diff. – стандартное отклоение для средней разницы;
t – значение t-критерия;
df – число степеней свободы;
Р – вероятность ошибочно отвергнуть нулевую гипотезу о том, что средние величины САД в сравниваемых группах не различаются. Поскольку в нашем случае Р < 0,05, можно смело заключить, что средние значения САД при использовании нового лекарства значительно различаются (Примечание: при наличии различий, результаты анализа в STATISTICA обычно (но не во всех модулях!) выделяются красным цветом).
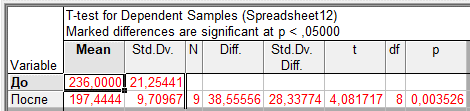
Рисунок 4.8. Результаты выполнения t-теста для зависимых выборок.
Если две зависимые выборки распределены ненормально, то для их сравнения следует применить тест Уилкоксона (Wilcoxonmatchedpairtest), который можно найти там же, где и тест Манна-Уитни (Statistics>Nonparametrics>Comparingdependentsamples.
Далее необходимо:
В появившемся окне (рис. 4.9) нажать кнопку Variables и задать переменные для анализа (для примера используем данные, представленные на рис. 4.7).
Нажатькнопку Wilcoxon matched pair test.
В итоговой таблице (рис. 4.10) найти величину Р. При Р < 0,05 можно сделать вывод о наличии статистически значимой разницы между сравниваемыми выборками.

Рисунок 4.9. Окно Comparingtwogroups модуля Nonparametrics (при сравнении зависимых выборок)

4.10. Результаты выполнения теста Уилкоксона.
Сравнение нескольких групп
Тест Стьюдента и его непараметрические аналоги предназначены для сравнения исключительно двух выборок. Однако очень часто исследователи допускают ошибку, используя t-тест для попарных сравнений более двух выборок. Во избежание данной ошибки необходимо использовать дисперсионный анализ (или «ANOVA» – от англ. analysisofvariance).
Апостериорный анализ
Важно помнить, что дисперсионный анализ позволяет проверить лишь гипотезу об отсутствии различий между сравниваемыми группами в целом. Однако с его помощью невозможно узнать, какие именно группы различаются между собой. Для выяснения этого необходимо воспользоваться методами множественных сравнений, являющихся частью т.н. апостериорного анализа (Post-hocanalysis). Механизм их работы заключается в проведении попарных сравнений средних значений всех групп, включенных в дисперсионный анализ.
Для выполнения множественных сравнений необходимо открыть закладку Posthoc (рис. 5.7) в окне дополнительных результатов дисперсионного анализа (Moreresults).

Рисунок 5.7. Окно дополнительных результатов дисперсионного анализа на закладке Post-hoc.
Программа STATISTICA предлагает ряд тестов для множественных сравнений, несколько различающихся по мощности: Fisher LSD, Bonferroni, Scheffe, Tukey HSD, Newman-Keuls, Duncan’s, Dunnet. Наиболее часто используемыми являются тесты Тьюки (Tukey HSD) и Ньюмена-Кейлса (Newman-Keuls). Нажатие на кнопку соответствующего теста приводит к появлению рабочей книги с матрицей значений Р. Из рис. 5.8, например, видно, что статистически значимая разница в количестве клеток существует между парами препаратов «Модификация 0 – Модификация 1» и«Модификация 0 – модификация 2» (Р < 0,05), тогда как оба новых препарата по эффективности не различаются (Р > 0,05) (выполнен тест Тьюки для выборок с одинаковыми объемами).

Рисунок 5.8. Результат выполнения теста Тьюки.
Сравнение двух групп
Случай независимых выборок
Одной из обычных задач в биологических исследованиях является сравнение арифметических средних двух групп (например, экспериментальной и контрольной). Классическим методом, позволяющим ее решать, является t-тест Стьюдента, или просто «t-тест». Нулевая гипотеза, проверяемая в ходе данного теста, заключается в том, что обе группы происходят из одной генеральной совокупности; другими словами, что наблюдаемые различия между средними значениями сравниваемых выборок случайны и не вызваны действием изучаемого фактора. Тест Стьюдента относится к группе параметрических методов анализа. Его корректное применение требует выполнения трех условий:
обе выборки должны быть независимыми, т.е. свойства одной из них никак не должны быть связаны со свойствами другой (известно, например, что женщины в среднем ниже мужчин, однако это не является результатом того, что мужчины оказывают какое-то особое влияние на рост женщин – дело здесь в генетических особенностях пола);
обе выборки должны подчиняться нормальному закону распределения;
между дисперсиями выборок не должно быть статистически значимой разницы (однородность дисперсий).
К сожалению, многие исследователи-биологи игнорируют перечисленные условия при выполнении теста Стьюдента, что часто приводит к ошибочным результатам. Наиболее «опасным» является несоблюдение требования о нормальности распределения значений признака в сравниваемых группах.
Рассмотрим, как тест Стьюдента можно выполнить при помощи программы STATISTICA. На рис. 4.1 приведены данные о содержании гемоглобина в крови (г/л) больных сахарным диабетом и здоровых людей. Выборки сопоставимы по полу, возрасту и т.п. Применим t-тест для сравнения средних значений этих двух независимых выборок. (Примечание: в учебных целях допустим, что обе выборки распределены нормально, и что их дисперсии различаются незначительно).
Рисунок 4.1. Пример оформления данных для выполнения t -теста для независимых выборок.
Обратите внимание на то, как оформлены данные на рис. 4.1. В таблице имеются две переменные. Одна из них – группирующая (Groupingvariable) («Группа») – содержит коды, указывающие принадлежность данных о содержании гемоглобина к конкретной группе. Другая – т.н. зависимая переменная (Dependentvariable) («Гемоглобин») – содержит собственно данные. Возможен и другой вариант оформления – данные для каждой группы («Больные» и «Здоровые») можно было бы просто внести в отдельные столбцы, не используя группирующую переменную.
Для выполнения t-теста для независимых выборок необходимо выполнить следующие действия:
Запустить соответствующий модуль (рис. 4.2) из меню Statistics>Basicstatistics/Tables> t-test, independent, bygroups (если в таблице с данными есть группирующая переменная) или t-test, independent, byvariables (если данные внесены в самостоятельные столбцы). (Примечание: мы рассмотрим вариант теста, при котором группирующая переменная присутствует; рис. 4.1).
В открывшемся окне нажать кнопку Variables и указать программе, какая из переменных является группирующей, а какая – зависимой (рис. 4.3).
Нажать на кнопку Summary: T-tests (рис. 4.2).
Рисунок 4.2. Модуль t-теста для независимых выборок.
Рисунок 4.3. Выбор переменных для включения в t-тест.
В итоге программа создаст рабочую книгу, содержащую таблицу с результатами t-теста. Эта таблица имеет несколько столбцов (рис. 4.4):
Mean (Больные): среднее значение содержания гемоглобина в группе «Больные»;
Mean (Здоровые): среднее значение содержания гемоглобина в группе «Здоровые»;
t-value: значение рассчитанного программой t-критерия Стьюдента;
df: число степеней свободы;
P: вероятность ошибочно отвергнуть нулевую гипотезу об отсутствии различий между средними (см. выше). Фактически, это самый главный интересующий нас результат анализа. В рассматриваемом примере P > 0,05, на основании чего можно сделать вывод об отсутствии статистически значимых различий между средними значениями содержания гемоглобина из разных групп наблюдения.
Valid N (Северная): объем выборки «Больные»;
Valid N (Южная): объем выборки «Здоровые»;
Std. dev. (Больные): стандартное отклонение выборки «Больные»;
Std. dev. (Здоровые): стандартное отклонение выборки «Здоровые»;
F-ratio, Variances: значение F-критерия Фишера, с помощью которого проверяется гипотеза о равенстве дисперсий в сравниваемых выборках (см. выше условия применения теста Стьюдента);
P, Variances: вероятность ошибки для F-теста Фишера. Поскольку в нашем случае Р > 0,05, можно заключить, что дисперсии сравниваемых выборок не различаются (т.е. условие однородности дисперсий выполняется).
Рисунок 4.4. Результаты выполнения t-теста для независимых выборок.
Если значения признака в двух сравниваемых группах распределены ненормально, применение параметрического t-теста для их сравнения будет часто приводить к искаженным результатам. В таких случаях следует воспользоваться соответствующим непараметрическим аналогом теста Стьюдента. Для сравнения двух независимых ненормально распределенных выборок используется U-тест Манна-Уитни (Mann-Whitney U-test). В программе STATISTICA этот тест выполняется следующим образом:
В меню Statistics выбрать Nonparametrics, а затем Comparingtwoindependentsamples (Сравнение двух независимых выборок).
В появившемся окне (рис. 4.5) нажать на кнопку Variables и выбрать зависимую и независимую переменные (для примера воспользуемся теми же данными по содержанию гемоглобина в кровилюдей из разных групп, см. рис. 4.1).
Рисунок 4.5. Окно Comparingtwogroups модуля Nonparametrics (при сравнении независимых выборок).
Нажать на кнопку Mann-Whitney U-test или M-W U test. Внешний вид появляющегося после этого окна представлен на рис. 4.6. Самое главное, на что следует обратить внимание в итоговой таблице теста – это величина вероятности ошибки Р. При большом числе наблюдений в выборках (20 и более) значение Р необходимо искать в 5-м столбце таблицы (вслед за «Z»), иначе – в 7-м (вслед за «Z-adjusted»). При Р < 0,05 делается вывод о наличии статистически значимой разницы между сравниваемыми выборками (Примечание: в отличие от t-теста, тест Манна-Уитни сравнивает не средние значения выборок, а суммы рангов по каждой из них. Ранг – положение определенного значения изучаемого признака в упорядоченном по убыванию или возрастанию ряду).
Рисунок 4.6. Результаты выполнения теста Манна-Уитни.
Случай зависимых выборок
Для проверки эффективности двух новых препаратов был выполнен следующий эксперимент. Былов каждую из 27 лунок планшета было добавлено 10000 клеток. Затем в9 из них добавили используемый в практике препарат, в следующие 9 – препарат с модификацией 1, а в оставшиеся 9 – препарат с модификацией 2. Через 3 дня было посчитано количество клеток в каждой лунке. Полученные данные приведены в таблице 5.1. Вопрос: различается ли средний прирост клеточной культуры в зависимости от типа препарата?
С зависимыми выборками исследователь имеет дело каждый раз, когда измерения значений изучаемого признака выполняются на одних и тех же объектах. Рассмотрим следующий пример. Для выяснения эффективности нового лекарствау пациентов измеряли САД до применения препарата и после. Необходимо выяснить, различается ли уровень АД в зависимости от применения лекарства (рис. 4.7).
Рисунок 4.7. Пример оформления данных для выполнения t-теста для зависимых выборок.
Поскольку давление измерялось у одних и тех же людей, то выборки, полученные в результате двух описанных экспериментов, являются зависимыми. Чтобы сравнить средний уровень САД воспользуемся t-тестом для зависимых выборок. (Примечание: в учебных целях допустим, что условие о нормальности распределения данных выполняется). Для выполнения этого варианта t-теста необходимо:
ЗапуститьсоответствующиймодульизменюStatistics>Basicstatistics/Tables>t-test, dependentsamples.
В открывшемся окне нажать на кнопку Variables и указать программе первую (Firstvariable) и вторую (Secondvariable) переменные, участвующие в анализе.
Нажать на кнопку Summary: T-tests.
В результате появится таблица с результатами, очень похожая на ту, что мы уже видели при выполнении t-теста для независимых выборок. Она содержит следующие столбцы (рис. 4.8):
Mean – средние значения САД для каждой из сравниваемых групп;
Std. dv. – стандартные отклонения для каждой группы;
N – число наблюдений;
Diff. – средняя разница;
Std. dv. diff. – стандартное отклоение для средней разницы;
t – значение t-критерия;
df – число степеней свободы;
Р – вероятность ошибочно отвергнуть нулевую гипотезу о том, что средние величины САД в сравниваемых группах не различаются. Поскольку в нашем случае Р < 0,05, можно смело заключить, что средние значения САД при использовании нового лекарства значительно различаются (Примечание: при наличии различий, результаты анализа в STATISTICA обычно (но не во всех модулях!) выделяются красным цветом).
Рисунок 4.8. Результаты выполнения t-теста для зависимых выборок.
Если две зависимые выборки распределены ненормально, то для их сравнения следует применить тест Уилкоксона (Wilcoxonmatchedpairtest), который можно найти там же, где и тест Манна-Уитни (Statistics>Nonparametrics>Comparingdependentsamples.
Далее необходимо:
В появившемся окне (рис. 4.9) нажать кнопку Variables и задать переменные для анализа (для примера используем данные, представленные на рис. 4.7).
Нажатькнопку Wilcoxon matched pair test.
В итоговой таблице (рис. 4.10) найти величину Р. При Р < 0,05 можно сделать вывод о наличии статистически значимой разницы между сравниваемыми выборками.
Рисунок 4.9. Окно Comparingtwogroups модуля Nonparametrics (при сравнении зависимых выборок)
4.10. Результаты выполнения теста Уилкоксона.
Cравнение выборочной средней с константой
В ряде случаев возникает необходимость сравнить выборочную среднюю не с другой выборочной средней, а с определенной константой. Допустим, что, согласногосударственному стандарту, ПДК некоторого загрязнителя составляет 100 единиц. При замерах содержания этого вещества в 10 пробах городской почвы получены следующие значения: 108, 99, 112, 100, 101, 98, 95, 105, 90, 102. Необходимо установить, превышает ли среднее содержание загрязнителя в исследованных образцах почвы предельно допустимую концентрацию?
Для ответа на поставленный вопрос необходимо воспользоваться анализом, который в программе STATISTICA называется t-testforsinglemeans (t-тест для средних, рассчитанных по одной выборке). ЕгоможнонайтивменюStatistics > Basic Statistics/Tables > t-test, single sample. В результате появится окно, внешний вид которого представлен на рис. 4.11.

Рисунок 4.11. Окно настройки t-теста для средних, рассчитанных по одной выборке
Нажав на кнопку Variables, необходимо выбрать столбец, который содержит анализируемые данные. Таких переменных можно ввести несколько (например, если бы аналогичные отборы проб почвы производились в разные месяцы, то в анализ можно было бы включить и эти данные). В таком случае программа сравнит все выборки с одним «контрольным» значением. Последнее задается в поле Referencevalues (Контрольные значения) (рис. 4.11). В нашем примере контролем является ПДК = 100 – его и следует внести напротив опции Testallmeansagainst... (Сравнить все средние с...). При необходимости, включенные в анализ переменные можно сравнить с несколькими контрольными значениями (это достигается путем активации опции Testmeansagainstuser-definedconstants (Сравнить средние с константами, заданными пользователем)).
После нажатия на кнопку Summary появится рабочая книга, содержащая таблицу с результатами анализа (рис. 4.12). В этой таблице имеются следующие столбцы:
Mean – среднее значение, рассчитанное на основе выборочных данных (в нашем случае – средняя концентрация загрязнителя в 10 пробах почвы);
Stddv. – стандартное отклонение;
N – объем выборки;
Std. err. – стандартная ошибка;
Referenceconstant – контрольное значение;
df – число степеней свободы;
Р – вероятность ошибочно отвергнуть нулевую гипотезу о том, что выборочная средняя не отличается от контрольной величины. В нашем случае Р > 0,05. Таким образом, несмотря на некоторое превышение средней концентрации загрязнителя в некоторых пробах, в целом это превышение это является незначительным.

Рисунок 4.12. Результаты сравнения выборочной средней с контрольным значением.
Задания для самостоятельного выполнения.
1. Измеряли диаметр коронарных сосудов после приема нифедипина и плацебо. Позволяют ли проводимые ниже данные утверждать, что нифедипин влияет на диаметр коронарных сосудов? Для начала проверьте обе выборки на нормальность распределения.
| Плацебо
| 2,2
| 2,2
| 2,6
| 2,0
| 2,1
| 1,8
| 2,4
| 2,3
| 2,7
| 2,7
| 1,9
|
| Нифедипин
| 2,5
| 1,7
| 1,5
| 2,5
| 1,4
| 1,9
| 2,3
| 2,0
| 2,6
| 2,3
| 2,2
|
2. При заболеваниях сетчатки может повышаться проницаемость сосудов. Измерили проницаемость сосудов сетчатки у здоровых людей и у больных с ее поражением. Необходимо проверить, значимы ли различия в проницаемости сосудов сетчатки. Для начала проверьте обе выборки на нормальность распределения.
| Здоровые
| 0,5
| 0,7
| 0,7
| 1,0
| 1,0
| 1,2
| 1,4
| 1,4
| 1,6
| 1,6
| 1,7
| 2,2
|
| Больные
| 1,2
| 1,4
| 1,6
| 1,7
| 1,7
| 1,8
| 2,2
| 2,3
| 2,4
| 6,4
| 19,0
| 23,6
|
Сравнение нескольких групп
Тест Стьюдента и его непараметрические аналоги предназначены для сравнения исключительно двух выборок. Однако очень часто исследователи допускают ошибку, используя t-тест для попарных сравнений более двух выборок. Во избежание данной ошибки необходимо использовать дисперсионный анализ (или «ANOVA» – от англ. analysisofvariance).






