Побуквенное кодирование пригодно для любых сообщений. Однако на практике часто доступна дополнительная информация о вероятностях символов исходного алфавита. С использованием этой информации решается задача оптимального побуквенного кодирования.
Пусть имеется дискретный вероятностный источник, порождающий символы алфавита А={a1,…,an} с вероятностями pi = p(ai), 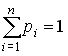 . Основной характеристикой источника является его энтропия, которая представляет собой среднее значение количества информации в сообщении источника и определяется выражением (для двоичного случая)
. Основной характеристикой источника является его энтропия, которая представляет собой среднее значение количества информации в сообщении источника и определяется выражением (для двоичного случая)  . Энтропия характеризует меру неопределенности выбора для данного источника. Например, если А={a1,a2}, p1=0, p2 =1, т.е. источник может породить только символ a2, то неопределенности нет, энтропия H(p1, p2)=0. Максимальная энтропия будет, если все символы равновероятны, например, А={a1,a2}, p1=1/2, p2 =1/2, тогда неопределенность максимальная, т.е. H(p1, p2)=1.
. Энтропия характеризует меру неопределенности выбора для данного источника. Например, если А={a1,a2}, p1=0, p2 =1, т.е. источник может породить только символ a2, то неопределенности нет, энтропия H(p1, p2)=0. Максимальная энтропия будет, если все символы равновероятны, например, А={a1,a2}, p1=1/2, p2 =1/2, тогда неопределенность максимальная, т.е. H(p1, p2)=1.
Для практических применений важно, чтобы коды сообщений имели по возможности наименьшую длину. Основной характеристикой неравномерного кода является количество символов, затрачиваемых на кодирование одного сообщения. Пусть имеется разделимый побуквенный код для источника, порождающего символы алфавита А={a1,…,an} с вероятностями pi = p(ai), , состоящий из n кодовых слов с длинами L1,…,Ln в алфавите {0,1}. Средней длиной кодового слова называется величина  или среднее число кодовых букв на одну букву источника.
или среднее число кодовых букв на одну букву источника.
Пример. Пусть для имеются два источника с одним и тем же алфавитом А={a1,a2,a3} и разными распределениями P1={1/3, 1/3, 1/3}, P2={1/4, 1/4, 1/2}, которые кодируются одним и тем же кодом φ = {a1→10, a2→ 000, a3→ 01}. Средняя длина кодового слова для разных распределений будет различной
Lφ(P1)=1/3.2 + 1/3.3 + 1/3.2=7/3 ≈2.33
Lφ(P2)=1/4.2 + 1/4.3 + 1/2.2= 9/4 =2.25
Побуквенный разделимый код называется оптимальным, если средняя длина кодового слова минимальна для данного разделения вероятностей символов. Избыточность кода является показателем качества кода. Избыточностью кода называется разность между средней длиной кодового слова и энтропией источника сообщений r=Lcp-H. Задача эффективного неискажающего сжатия заключается в построении кодов с наименьшей избыточностью, у которых средняя длина кодового слова близка к энтропии источника. К таким кодам относятся классические коды Хаффмана, Шеннона, Фано, Гильберта-Мура.
Приведем некоторые свойства, которыми обладает любой оптимальный побуквенный код.
Лемма 1. Для оптимального кода с длинами кодовых слов L1,…,Ln: верно соотношение L1≤L2≤…≤Ln (p1≥p2≥…≥pn).
Доказательство (от противного): Пусть есть i и j, что Li>Lj при pi>pj. Тогда
Lipi+Ljpj=Lipi+Ljpj+Lipj+Ljpi-Lipj-Ljpi=
=pi(Li-Lj)-pj(Li-Lj)+Ljpi+Lipj=(pi-pj)(Li-Lj) +Lipj+Ljpi>Lipj+Ljpi,
т.е. если поменяем местами Li и Lj, то получим код, имеющий меньшую среднюю длину кодового слова. Противоречие с оптимальностью.
Лемма 2 Пусть  схема оптимального префиксного кодирования для распределения вероятностей Р,
схема оптимального префиксного кодирования для распределения вероятностей Р,  . Тогда среди элементарных кодов, имеющих максимальную длину, существуют два, которые различаются только в последнем разряде.
. Тогда среди элементарных кодов, имеющих максимальную длину, существуют два, которые различаются только в последнем разряде.
Доказательство. Покажем, что в оптимальной схеме кодирования всегда найдется два кодовых слова максимальной длины. Предположим обратное. Пусть кодовое слово максимальной длины одно и имеет вид 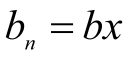 ,
,  . Тогда длина любого элементарного кода не больше длины b, т.е.
. Тогда длина любого элементарного кода не больше длины b, т.е.  ,
,  . Поскольку схема кодирования префиксная, то кодовые слова
. Поскольку схема кодирования префиксная, то кодовые слова  не являются префиксом b. С другой стороны, b не является префиксом кодовых слов . Таким образом, новая схема кодирования
не являются префиксом b. С другой стороны, b не является префиксом кодовых слов . Таким образом, новая схема кодирования 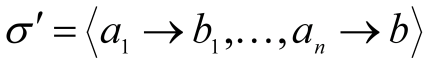 также является префиксной, причем с меньшей средней длиной кодового слова
также является префиксной, причем с меньшей средней длиной кодового слова  , что противоречит оптимальности исходной схемы кодирования. Пусть теперь два кодовых слова
, что противоречит оптимальности исходной схемы кодирования. Пусть теперь два кодовых слова  и
и  максимальной длины отличаются не в последнем разряде, т.е.
максимальной длины отличаются не в последнем разряде, т.е.  ,
,  ,
,  ,
,  . Причем
. Причем  ,
,  не являются префиксами для других кодовых слов
не являются префиксами для других кодовых слов  и наоборот. Тогда новая схема
и наоборот. Тогда новая схема  также является префиксной, причем
также является префиксной, причем  , что противоречит оптимальности исходной схемы кодирования.
, что противоречит оптимальности исходной схемы кодирования.
Рассмотрим алгоритм построения оптимального кода Хаффмана.
Упорядочим символы исходного алфавита А={a1,…,an} по убыванию их вероятностей p1≥p2≥…≥pn.
Если А={a1,a2}, то a1→0, a2→1.
Если А={a1,…,aj,…,an} и известны коды <aj → bj >, j = 1,…,n,то для {a1,…aj/,aj//…,an}, p(aj)=p(aj/)+ p(aj//), aj/ → bj0, aj// →bj1.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Будем складывать две наименьшие вероятности и включать суммарную вероятность на соответствующее место в упорядоченном списке вероятностей до тех пор, пока в списке не останется два символа. Тогда закодируем эти два символа 0 и 1. Далее кодовые слова достраиваются, как показано на рисунке 67.

Рисунок 4 – Процесс построения кода Хаффмена
Таблица 5. Код Хаффмана

Посчитаем среднюю длину, построенного кода Хаффмана
Lср(P)=1.0.36 + 3.0.18 + 3.0.18 + 3.0.12 + 4.0.09 + 4.0.07 =2.44,
при этом энтропия данного источника равна
H=-(0.36.log0.36+2.0.18.log0.18+0.12.log0.12+0.09.log0.09+0.07log0.07)=2.37
Код Хаффмана обычно строится и хранится в виде двоичного дерева, в листьях которого находятся символы алфавита, а на «ветвях» – 0 или 1. Тогда уникальным кодом символа является путь от корня дерева к этому символу, по которому все 0 и 1 собираются в одну уникальную последовательность.

Рисунок 5 – Кодовое дерево для кода Хаффмена
Алгоритм на псевдокоде.






