Вероятность обучающей выборки
· Шкала оценки интеллектуальных задач (Шоиз)
0 < НЕУД < 0,6 ≤ УД < 0,75 ≤ ХОРОШО < 0,95 ≤ ОТЛИЧНО < 1 ближе к левому краю неравенство не строгое.
Если у вас получилось 1 (100%), то вы или решаете простую задачу или ОТКРЫЛИ ЗАКОН
· Лингвистическая переменная
это переменная, значения которой могут быть словами или словосочетаниями некоторого естественного языка. Набор (B,T,X,G,M)
B – название ЛП
T – множество значений (терм-множество)
X – множество числовых нечетких переменных
G – синтаксическая процедура, позволяющая оперировать элементами Т
M – процедура формирования нечеткого множ-ва.
· Комитет старшинства<=>2 полупространства полученных с помощью ломанной линии
· теорема Мазурова
для любой разумной обучающей выборки можно построить за конечное время разделяющею функцию с качеством разделения ρобучения=1 или однородный комитет
· Теорема Вапника размер макс. Информационного пространства
Размер максимально информативного пространства определяется по формуле –(количество векторов обучающей выборки)/3
Стандартная модель данных для
Задачи обучения с учителем
| Обучающая выборка
Образ 1
|
 Проверочная выборка
Образ 1 Проверочная выборка
Образ 1
|
| Обучающая выборка
Образ 2
|
| Проверочная выборка
Образ 2
|
| |
 Контрольная выборка
Образ 1 Контрольная выборка
Образ 1
|
| Образ 2
|
| Знает блок проверка и учителем к какому образу отклоняется объект
| |
Знает ПК и учитель к какому
образу
| Знает только учитель, к какому образу относятся объекты
| |
Относятся объекты?
. История искусственного интеллекта. Проект машин пятого поколения и его результаты. Шкала оценки задач ИИ.
Искусственный интеллект (ИИ) - это наука о концепциях, позволяющих вычислительной машине (ВМ) делать такие вещи, которые у людей выглядят разумными.
История:
В 50-х годах исследователи в области ИИ пытались строить разумные машины, имитируя мозг. Эти попытки оказались безуспешными по причине полной непригодности как аппаратных так и программных средств. В конце 50-х гг. родилась модель лабиринтного поиска.
Начало 60-х — это эпоха эвристического программирования. Предпринимались попытки отыскать общие методы решения широкого класса задач.
В 1963-70 гг. к решению задач стали подключать методы математической логики. Робинсон разработал метод резолюций, который позволяет автоматически доказывать теоремы при наличии набора исходных аксиом.
Конец 70-х годов - создание экспертных систем (ЭС). Япония объявляет о начале проекта машин V поколения, основанных на знаниях.
В 80-х годах появились первые коммерческие программные продукты. В это время стала развиваться область машинного обучения.
Проект машин пятого поколения и его результаты.
Создан в 80-е годы. Япония объявила о начале проекта машин V поколения, основанных на знаниях. Проект был рассчитан на десять лет и объединял лучших молодых специалистов крупнейших японских компьютерных корпораций.
Вычислительная система нового поколения должна была быть ориентирована на обработку знаний и располагать весьма развитыми возможностями логического вывода. Важнейшее ее свойство должно было состоять в том, чтобы используемый интерфейс был непосредственно рассчитан на человека.
Предполагалось, что это будет не одна машина, а несколько модулей. На более поздних этапах развития проекта должна была быть создана параллельная машина.
Проект машин пятого поколения не достиг целей в прямой постановке. Например, нерешенными вопросами остались задачи интеллектуализации интерфейса, синтеза решений. Однако его роль в современном состоянии информатики представляется основополагающей. Выводы: задачи ИИ со 100% вероятностью не решает даже человек(распознавание изображения, понимание смысла); в то время не хватало специалистов по ИИ; недостаточное развитие компьютеров.
Шкала оценки задач ИИ: до 60% - неуд., 60 – 75% - уд., 75 – 95% -хор., от 95% - отл.
2. Основные направления исследования в области искусственного интеллекта. Задачи искусственного интеллекта и их характерные признаки.
Направления:
· Экспертные системы, базы знаний.
· Языки программирования систем ИИ.
· Машинный перевод.
· Интеллектуальные роботы.
· Распознавание образов.
· Игры и машинное творчество
· Анализ изображений, синтез речи
· Нечёткая логика
· Нейронные сети
задачи.
o Создание полного научного описания интеллекта человека.
o Задачи, алгоритм нахождения которых неизвестен. Любую задачу можно решить методами ИИ, но есть недостаток: некоторая % вероятность.
Характерные признаки.
3. Метод черного ящика. Его применение к задачам ИИ
В основу этого подхода положен принцип, согласно которому не имеет значения, как устроено «мыслящее» устройство. Главное, чтобы данному входу соответствовал заданный выход.
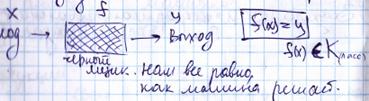
для распознавания образов:
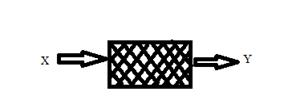
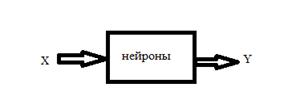
для нейронных сетей:
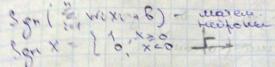
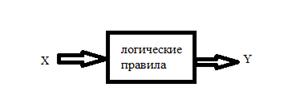
для экспертных систем:
4. Основные задачи РО. Образ, объект.
Распознавание образов – это раздел искусственного интеллекта, целью которого является классификация объектов по нескольким категориям или классам.
определения:
· Образ (класс) - это множество всех объектов (либо явлений, процессов, ситуаций), сходных между собой(сгруппированных) в некотором фиксированном отношении.
· Прецедент – это образ, правильная классификация которого известна, принимаемый как образец при решении задач классификации.
· Объект – n-мерный вектор. Координаты вектора – признаки. Признаки считаем независимыми.
задачи:
Задача распознавания образов состоит в том, чтобы отнести новый распознаваемый объект к какому-либо классу (образу).
1. Задача обучения без учителя(TA - таксономия)
2. Задача обучения с учителем(DA – дискриминантный анализ)
3. Задача информативности – поиск существенных признаков
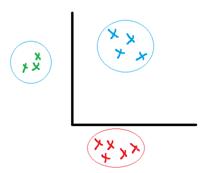 5. Задача обучения без учителя. Подготовка информации для задачи таксономии, определение образов таксономии.
5. Задача обучения без учителя. Подготовка информации для задачи таксономии, определение образов таксономии.
Испытуемая система спонтанно обучается выполнять поставленную задачу, без вмешательства со стороны экспериментатора. Это пригодно только для задач, в которых известны описания множества объектов (обучающей выборки), и требуется обнаружить внутренние взаимосвязи, зависимости, закономерности, существующие между объектами.
· Образ – сгущение(таксон).
Входные данные:
· Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
· Матрица расстояний. Каждый объект описывается расстояниями до всех остальных объектов.
Определение образов:
Ro – начальное расстояние
Если |Xi-Xj|<Ro => r<Ro => объекты одного образа.
6. Модели и алгоритмы таксономии. Таксон
Таксон (кластер) – образ таксономии. Образ является сгущением. Состоит из дискретных объектов, объединяемых на основании общих свойств и признаков.
Есть 2 основных метода таксономии(кластеризации): декомпозиция (разделение, k-кластеризация) и иерархическая кластеризация.
В основном, алгоритмы метода k - кластеризации берут на вход множество S и число k. И на выход отдают разделение множества S на подмножества S1, S2,..., Sk.
1)Выбираем k произвольных попарно несовпадающих векторов и назначаем их центрами кластеров (центроидами).
2) Поиск ближайших соседей. Для каждого вектора из обучающего множества находим ближайший центроид.
3. Уточнение положений центроидов.
4. Проверка условия окончания итераций.
Принцип работы иерархической кластеризации состоит в последовательном объединении групп элементов, сначала самых близких, а затем всё более отдалённых друг от друга.
Алгоритмы:
Алгоритм Forel: использование сферы для нахождения локальных сгущений точек.
Forel-2: эта модификация исходного алгоритма используется в случае, когда нужно получить в точности t-таксонов. Один из эвристических приемов для учета неустойчивых таксонов реализован в алгоритме SKAT. Алгоритм KOLLAPS применяется в задачах выделения локальных сгустков точек из фона.Алгоритм BIGFOR решает проблему работы с очень большими массивами точек.
7. Задача обучения с учителем. Стандартная модель данных РО для ДА. Обучающая, проверочная и контрольная выборка. Блок схема
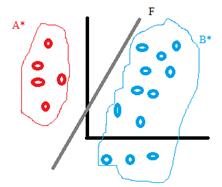
Задача распознавания на основе имеющегося множества прецедентов называется классификацией с обучением (или с учителем).
Известны A*, B*: A* принадлежит A, B* принадлежит B.
Задача заключается в построении такого решающего правила, чтобы распознавание проводилось с минимальным числом ошибок.
Предполагаем, что с одной стороны от F – множество A, с другой - множество B.
Распознавание неизвестных объектов z:
если F(z)>0, => z принадлежит A,
F(z)<0, => z принадлежит B.
Стандартная модель данных РО для ДА
Таблица, в строках – объекты.
 Обучающая выборка
Образ 1
ρ об=100% Обучающая выборка
Образ 1
ρ об=100%
|
| Проверочная выборка
Образ 1
ρ пр<100%
|
| Обучающая выборка
Образ 2
ρ об=100%
|
| Проверочная выборка
Образ 2
ρ пр<100%
|
| |
 Контрольная выборка ρ контр<100%
Образ 1 Контрольная выборка ρ контр<100%
Образ 1
|
| Образ 2
|
| |
| | | Построение решающего правила F(x)
ρ=100% об=100%
| |

 Знает ПК и учитель, к какому
Знает ПК и учитель, к какому

| F(x), вычисление ошибки ρ пр:
ρ пр>ρ0?
| |
| Знает только учитель, к какому образу относятся объекты
| |
образу относятся объекты-
обучающая выборка, знает
только учитель –проверочная
· Обучающая выборка – набор объектов с заранее известными классами. В процессе обучения классификатора строится решающее правило, определяющее границу между объектами указанных классов из обучающей выборки.
· Проверочная выборка представляет собой набор объектов, не участвующих в обучении. Диагностика объектов из проверочной выборки происходит путем последовательного применения найденного решающего правила. По количеству ошибок на проверочной выборке можно судить о применимости созданного решающего правила.
· Контрольная выборка – набор объектов с неизвестными классами(для ПК). Для оценки качества решающего правила.
8. Задача информативности. Оценка размера информативного пространства для данной выборки. Теорема Вапника. Блок схема СПА и информативность независимых признаков. Оценка качества.
Задача выбора информативной подсистемы признаков состоит в указании части признаков (из числа первоначально выбранных признаков для описания объектов), в пространстве которых заданные множества объектов, представляющие разные классы, разделяются достаточно просто и экономично.
Оценка размера информативного пространства для данной выборки – поиск количества существенных признаков (Найти миниум информативного пространства).
СПА - алгоритм выбора информативной подсистемы признаков на основе известного метода случайного поиска с адаптацией.
Критерий качества ρ0 задаём в начале решения задачи.
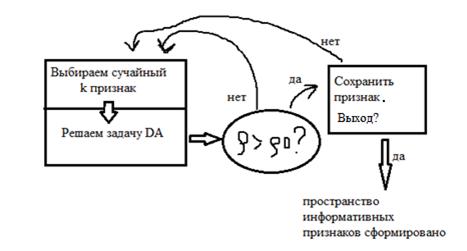
Вес признака – частота появления в подсистемах. Если вес >=0,5 - признак информативный(существенный).
Теорема Вапника(следствие).
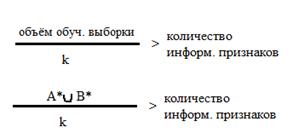
k – коэффициент, задаётся на входе(напр., k=3 для медицинских задач, k=10 для военных).
Если эта теорема не выполняется при решении задачи, результаты могут быть любыми.
Оценка качества:
Применяем 1 признак к проверочной выборке(для малого количества информации); сортируем объекты по классам; подсчитываем количество правильно распознанных объектов/ общее количество объектов - ρ к.
9. Задача информативности в РО. Информативные признаки
Задача выбора информативной подсистемы признаков состоит в указании части признаков (из числа первоначально выбранных признаков для описания объектов), в пространстве которых заданные множества объектов, представляющие разные классы, разделяются достаточно просто и экономично.
Оценка размера информативного пространства для данной выборки – поиск количества существенных признаков (Найти миниум информативного пространства).
СПА - алгоритм выбора информативной подсистемы признаков на основе известного метода случайного поиска с адаптацией.
Вес признака – частота появления в подсистемах. Если вес >=0,5 - признак информативный(существенный).
10. Математические модели задач распознавания образов.
Построение линейных решающих правил.
Теорема Новикова. Теорема Мазурова об однородных комитетах.
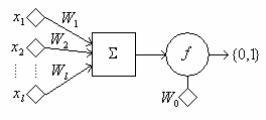 Математическая модель нейрона
Математическая модель нейрона
В алгоритме персептрона в основу положен принцип действия нейрона. Здесь х1,х2..хi – компоненты вектора признаков, Wi – веса, F – функция активации, W0 – порог. Значение функции активации вычисляется на основе определения знака суммы 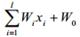
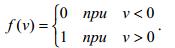
Таким образом, нейрон представляет собой линейный классификатор с дискриминантной
функцией 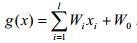 .
.
Тогда задача построения линейного классификатора для заданного множества
прецедентов сводится к задаче обучения нейрона, т.е. подбора соответствующих весов
и порога. Обучение состоит в коррекции весов и порога.
Алгоритм персептрона
Алгоритм персептрона представляет собой последовательную итерационную процедуру.
Каждый шаг состоит в предъявлении нейрону очередного вектора-прецедента и коррекции весов Wi по результатам классификации. Процесс обучения заканчивается, когда нейрон правильно классифицирует все прецеденты.
Задача построения линейной разделяющей гиперповерхности(линейного решающего правила)
Главным достоинством линейного классификатора является его простота и вычислительная эффективность. Рассмотрим линейную дискриминантную функцию:
· Определение. Множество, содержащее отрезок, соединяющий две произвольные
внутренние точки, называется выпуклым.
· Определение. Выпуклая оболочка – это минимальное выпуклое множество.
· Утверждение. Два множества на плоскости линейно разделимы тогда и только
тогда, когда их выпуклые оболочки не пересекаются.
Из этого утверждения получаем следующее правило проверки разделимости множеств
 на плоскости:
на плоскости:
1) Построить выпуклые оболочки.
2) Проверить пересечение выпуклых оболочек.
Если они не пересекаются, то множества разделимы.
3) Найти ближайшую пару точек в выпуклых оболочках обоих множеств.
4) Построить срединный перпендикуляр к отрезку, соединяющему эти точки. Этот перпендикуляр и будет разделяющей прямой.
Теорема Новикова: для любой обучающей непротиворечивой непересекающейся выборки(A* Ụ B*) можно построить линейную функцию(решающее правило) за конечное время с качеством распознавания 100%. A* и B* - выпуклые непустые множества, A* принадлежит A, B* принадлежит B.
Однородный комитет - нечетная (по количеству) совокупность параллельных n- мерных плоскостей.
Теорема Мазурова: для любой обучающей непротиворечивой выборки(A* Ụ B*) можно построить однородный комитет за конечное время, ρ об=ρ0 заданное. A* и B* - непустые множества, A* принадлежит A, B* принадлежит B.
11. Задача обучения с учителем. Модели и алгоритмы дискриминантного анализа. Метод потенциальных функций. Метод комитетов. Примеры. Основные теоремы.
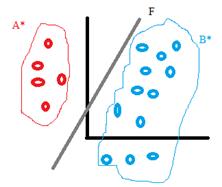
Задача распознавания на основе имеющегося множества прецедентов называется классификацией с обучением (или с учителем).
Известны A*, B*: A* принадлежит A, B* принадлежит B.
Задача заключается в построении такого решающего правила, чтобы распознавание проводилось с минимальным числом ошибок.
Предполагаем, что с одной стороны от F – множество A, с другой -множество B.
Распознавание неизвестных объектов z:
если F(z)>0, => z принадлежит A,
F(z)<0, => z принадлежит B.
Модели и алгоритмы дискриминантного анализа
Теорема Котельникова.
На входе аналоговый сигнал, превращается в дискретный, информация сохраняется, чтобы можно было вернуться назад.
Если сигнал таков, что его спектр ограничен частотой F сверху, то после дискретизации сигнала с частотой не менее 2F можно восстановить исходный непрерывный сигнал по полученному цифровому сигналу без потери точности.
Преобразование Фурье
Эквивалентность частотно-временных преобразований однозначно определяется через преобразование Фурье.
Преобразование Фурье рассматривается как обратимый переход от временно́го пространства в частотное пространство.
Если исходный сигнал задан функцией  , заданной на всей вещественной оси, то его преобразование Фурье задается формулой
, заданной на всей вещественной оси, то его преобразование Фурье задается формулой
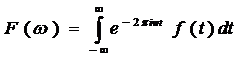

Функция  или ее модуль трактуется как интенсивность исходного сигнала на частоте
или ее модуль трактуется как интенсивность исходного сигнала на частоте 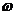 .
.
Выбор частоты преобразования
Так как звуки человеческой речи лежать в диапазоне частот 300-4000 Гц, то минимально необходимая частота преобразования составляет 8000 Гц. Однако многие компьютерные программы распознавания речи используют стандартную для обычных звуковых адаптеров частоту преобразования 44 000 Гц. С одной стороны, такая частота преобразования не приводит к чрезмерному увеличению потока цифровых данных, а другой — обеспечивает оцифровку речи с достаточным качеством.
Кодовая книга 
Записываются эталонные речевые фрагменты, разбиваются на элементарные составляющие (отрезки речи, в течении которых можно считать параметры речевого сигнала постоянными) и для каждого из них вычисляются значения характерных признаков. Они кластеризуются и записываются в кодовую книгу.
Алгоритм распознавания речи
· Алгоритмы динамического программирования.
Сравниваются эталонный элемент E и описание распознаваемого слова X. Задача сводится к поиску оптимальной траектории на плоскости, минимизирующей различие E и X.
Скрытая Марковская модель (СММ) — статистическая модель, задачей ставится разгадывание неизвестных параметров на основе наблюдаемых.
Алгоритм «прямого-обратного» хода —алгоритм, вычисляющий вероятность специфической последовательности наблюдений.
Алгоритм включает три шага:
o вычисление прямых вероятностей
o вычисление обратных вероятностей
o вычисление сглаженных значений
Сначала алгоритм продвигается, начиная с первого наблюдения в последовательности и идя в последнее, и затем возвращается назад к первому. При каждом наблюдении вычисляются вероятности последовательности, которые будут использоваться для вычислений при следующем наблюдении. Во время обратного прохода алгоритм одновременно выполняет шаг сглаживания. Сглаживание позволяет алгоритму принимать во внимание все прошлые наблюдения для того, чтобы вычислить более точные результаты.
14. База анализа изображений. По каким принципам она устроена?

В блоке предварительной обработки происходит бинаризация изображения, построение гистограмм и пороговых функций, фильтрация шумов, выделение границ, формирование линий, контуров объектов, выделение существенных признаков границ.
Описание объектов: список граничных пикселей, список линий, компактное описание контуров объектов, существенные признаки объектов.
Распознавание объектов на основе их существенных признаков с помощью базы знаний.
15. История и перспективы нейронных сетей. Персептрон. Нейрон. Следствие из теоремы Колмогорова. Принципы и алгоритмы построения нейронной сети.
В 1943 Мак-Каллок и Питтс разработали компьютерную модель нейронной сети на основе математических алгоритмов.
В 1957 Ф.Розенблатт разработал персептрон — математическую и компьютерную модель восприятия информации мозгом, на основе двухслойной обучающей компьютерной сети, использующей действия сложения и вычитания.
С 2006 было предложено несколько неконтролируемых процедур обучения нейронных сетей с одним или несколькими слоями с использованием так называемых алгоритмов глубокого обучения.
В последнее время предпринимаются активные попытки объединения искусственных нейронных сетей и экспертных систем. Нейросетевые прикладные пакеты, разрабатываемые рядом компаний, позволяют пользователям работать с разными видами нейронных сетей и с различными способами их обучения.
Области применения нейронных сетей весьма разнообразны — это распознавание текста и речи, семантический поиск, экспертные системы и системы поддержки принятия решений, предсказание курсов акций, системы безопасности, анализ текстов.
Эпоха настоящих параллельных нейровычислений начнется с появлением на рынке большого числа аппаратных реализаций.
Нейронная сеть – взвешенный орграф с входом и выходом.Серый ящик, определяющий класс функций.
 Нейрон представляет собой единицу обработки информации в нейронной сети. Это линейная функция от суммы, вес в графе(нейронной сети).
Нейрон представляет собой единицу обработки информации в нейронной сети. Это линейная функция от суммы, вес в графе(нейронной сети).
В этой модели нейрона можно выделить три основных элемента:
• синапсы, каждый из которых характеризуется своим весом или силой.
• сумматор, аналог тела клетки нейрона.
• функция активации, определяет окончательный выходной уровень нейрона.
персептрон — математическая и компьютерная модель восприятия информации мозгом, на основе двухслойной обучающей компьютерной сети, использующей действия сложения и вычитания.
Теорема Колмогорова:
Если рассматривать n-мерный куб и непрерывная функция заданая на вершинах, то любая точка внутри куба аппроксимируется его вершинами.
Следствие: любую функцию можно представить в виде нейронный сетей => любую задачу можно решить с помощью нейронных сетей.
Принципы нейронных сетей:
o Принцип коннекционизма означает, что каждый нейрон нейросети, как правило, связан со всеми нейронами предыдущего слоя обработки данных
o Нелинейность выходной функции активации
o Локальность и параллелизм вычислений
o Обучение, основанное на данных
o Универсальность обучающих алгоритмов
Для обучения нейронных сетей применяются алгоритмы двух типов: управляемое ("обучение с учителем") и не управляемое ("без учителя").
Общая схема обучения с учителем выглядит так:
1. Перед началом обучения весовые коэффициенты НС устанавливаются некоторым образом, на пример - случайно.
2. На первом этапе на вход НС в определенном порядке подаются учебные примеры. На каждой итерации вычисляется ошибка для учебного примера  (ошибка обучения) и по определенному алгоритму производится коррекция весов НС. Целью процедуры коррекции весов есть минимизация ошибки
(ошибка обучения) и по определенному алгоритму производится коррекция весов НС. Целью процедуры коррекции весов есть минимизация ошибки  .
.
3. На втором этапе обучения производится проверка правильности работы НС. На вход НС в определенном порядке подаются контрольные примеры. На каждой итерации вычисляется ошибка для контрольного примера  (ошибка обобщения). Если результат неудовлетворительный то, производится модификация множества учебных примеров и повторение цикла обучения НС.
(ошибка обобщения). Если результат неудовлетворительный то, производится модификация множества учебных примеров и повторение цикла обучения НС.
В алгоритме обратного распространения вычисляется вектор градиента поверхности ошибок. Алгоритм линейного поиска выбирает направление и ищет на ней миниум, затем повторяет действие. Алгоритм сопряжённых градиентов поскольку мы нашли точку минимума вдоль некоторой прямой, производная по этому направлению равна нулю. Сопряженное направление выбирается таким образом, чтобы эта производная и дальше оставалась нулевой.
Неуправляемое обучение. (Алгоритм Кохонена)
Алгоритм Кохонена дает возможность строить нейронную сеть для разделения векторов входных сигналов на подгруппы. Используется при заранее определённом количестве кластеров.
Шаг 1. Инициализация сети: весовым коэффициентам сети присваиваются малые случайные значения.
Шаг 2. Предъявление сети нового входного сигнала.
Шаг 3. Вычисление расстояния d до всех нейронов сети.
Шаг 4. Выбор нейрона с наименьшим расстоянием.
Шаг 5. Настройка весов нейрона j* и его соседей.
Шаг 6. Возвращение к шагу 2.
16. Основные подходы к построению нейронных сетей. Какие задачи необходимо решить при построении НС. Современные оболочки для моделирования нейронных сетей (МАТЛАБ).
Подходы:
Логический подход.
Основой служит Булева алгебра. Практически каждая система ИИ, построенная на логическом принципе, представляет собой машину доказательства теорем.
Под структурным подходом подразумеваются попытки построения ИИ путем моделирования структуры человеческого мозга.
Довольно большое распространение получил эволюционный подход. При построении систем ИИ по данному подходу основное внимание уделяется построению начальной модели, и правилам, по которым она может изменяться (эволюционировать).
Еще один широко используемый подход к построению систем ИИ — имитационный. Данный подход является классическим для кибернетики с одним из ее базовых понятий - "черным ящиком" (ЧЯ). Объект, поведение которого имитируется, представляет собой такой "черный ящик".
Задачи(этапы):
• Сбор данных для обучения;
• Подготовка и нормализация данных;
• Выбор топологии сети;
• Экспериментальный подбор характеристик сети;
• Экспериментальный подбор параметров обучения;
• Собственно обучение;
• Проверка адекватности обучения;
• Корректировка параметров, окончательное обучение;
• Вербализация сети с целью дальнейшего использования
Архитектура ЭС.
 База знаний - это совокупность единиц знаний.
База знаний - это совокупность единиц знаний.
В качестве методов представления знаний используются правила:
Если < условие >
То <заключение> CF (фактор определенности) <значение>
Интеллектуальный интерфейс воспринимает сообщения пользователя и преобразует их в форму представления базы знаний и, наоборот, переводит внутреннее представление результата обработки в формат пользователя и выдает сообщение на требуемый носитель.
Механизм вывода. Этот программный инструментарий получает от интеллектуального интерфейса запрос, формирует из базы знаний конкретный алгоритм решения задачи, выполняет алгоритм, а полученный результат предоставляется интеллектуальному интерфейсу для выдачи ответа на запрос пользователя.
Механизм объяснения.
Система всегда может выдать цепочку рассуждений до требуемой контрольной точки, сопровождая выдачу объяснения заранее подготовленными комментариями.
Механизм приобретения знаний.
В простейшем случае используется интеллектуальный редактор, который позволяет вводить единицы знаний в базу и проводить их синтаксический и семантический контроль, например, на непротиворечивость.
18. Нечеткое множество. Отличие нечеткой логики от теории вероятности. Операции над нечеткими множествами.
Нечёткое (или размытое, пушистое) множество — чёткое множество+ характеристическая функция, принимающая любые значения в интервале 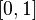 .
.
Множество – совокупность независимых, различных, неупорядоченных элементов.
| Критерий оценки
| Нечеткая логика
| Вероятностная логика
|
| Значения истинности
| Интервал [0,1]
Истинное значение – субъективная величина.
| Меры истинности: существование различных исходов событий с какой-то степенью вероятности. Вероятность определяется в статистическом смысле.
|
| Основные логические формулы
| Логические формулы такие же, как и в четкой, но принимают значения истины на интервале [0,1].
| Всем логическим формулам приписывается вероятность, с которой эта формула будет работать так, а не иначе. Логическая формула может вести себя по-разному с какой-то вероятностью.
|
| Правила вывода
| Верны всегда. Но интерпретация полученного результата субъективна.
| Правила вывода верны с какой-то степенью вероятности, которая является статистической величиной. Результат зависит от того, как сработает правило в конкретной ситуации.
|
| Расширяемость
| Все знания прописаны жестко.
Возможность добавления новых знаний отсутствует.
| Все знания прописаны жестко.
Возможность добавления новых знаний отсутствует.
|
Операции над нечёткими множествами:
· операции пересечения и объединения нечётких множеств, определяемые, соответственно, операциями минимум и максимум над значениями принадлежности.
· Произведением нечётких множеств 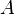 и
и 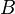 называется нечёткое подмножество с функцией принадлежности:
называется нечёткое подмножество с функцией принадлежности:
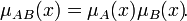
· Суммой нечётких множеств и называется нечёткое подмножество с функцией принадлежности:
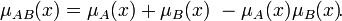
· Отрицанием множества 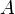 называется множество
называется множество 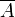 с функцией принадлежности:
с функцией принадлежности:
19. История и современное состояние систем нечеткой логики. Архитектура систем управления с нечеткой логикой.
История нечеткой логики
Впервые термин нечеткая логика был введен американским профессором азербайджанского происхождения Лотфи Заде в 1965 году.
В начале 1920-х годов польский математик Лукашевич трудился над принципами многозначной математической логики, в которой значениями предикатов могли быть не только «истина» или «ложь».
В 1937 г. еще один американский ученый Макс Блэк в своей статье в журнале «Философия науки» впервые применил многозначную логику Лукашевича к спискам как множествам объектов и назвал такие множества неопределенными. И только почти через 30 лет после этой работы Блэка Заде на основе логики Лукашевича построил полноценную алгебраическую систему. Мамдани в 1975 г. спроектировал первый функционирующий на основе алгебры Заде контроллер, управляющий паровой турбиной.
Фундаментальные математические операции нечеткой логики настолько четко определены, что они давно и успешно реализованы «в железе» (точнее, в системах команд) серийно выпускаемых микроконтроллеров.
В Японии это направление переживает настоящий бум. Здесь функционирует специально созданная организация – Laboratory forInternational Fuzzy Engineering Research (LIFE). Программой этой организации является создание более близких человеку вычислительных устройств.
НЕ ВЕРНО
Объект ó граф Объект ó n- вектор
Обработка изображений — любая форма обработки информации, для которой входные данные представлены изображением.
Распознавание образов — раздел кибернетики, развивающий теоретические основы и методы классификации и идентификации объектов, которые характеризуются конечным набором некоторых свойств и признаков.
5. Определение пикселя и его отличие от признака?
Признаки объекта (или факторы) – координаты n -мерного вектора.
Признак в математике, логике — то же, что и достаточное условие. В менее строгих науках слово «признак» употребляется, как описание фактов, позволяющих сделать вывод о наличии интересующего явления.
Пиксель ó 1кб*1кб, практически это точка на экране, которая входит в описание объекта с помощью внешних признаков (границы объекта, форма, контур и т.д.)
ПЛОХО
Сегментация изображений
26-Звук S(t)
Изображение f(x,y)
звук в компьютере (одномерный массив чисел)
изображение в компьютере (двумерный массив чисел)
20- постановка задачи анализа изображений. Вход и выход задачи.
Вход-изображение, выход-название объектов
21. Нейронная сеть -(сложная функция(функция от функций);) - суперпозиция функций f1(f1(f1(нейр.,нейр.))),аргументами которой являются нейроны
· НС=(G,нейрон),
где G-ориентированный взвешенный граф, который имеет несколько стоков и истоков, вес нейрон.
Нейрон= f( 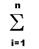 wixi+bi),
wixi+bi),
где wi- вес, xi -вход, bi -сигнал.
ИНС может рассматриваться как направленный граф со взвешенными связями, в котором искусственные нейроны являются узлами.
По архитектуре связей ИНС могут быть сгруппированы в два класса: сети прямого распространения, в которых графы не имеют петель, и рекуррентные сети, или сети с обратными связями.







