

Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...

Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Механическое удерживание земляных масс: Механическое удерживание земляных масс на склоне обеспечивают контрфорсными сооружениями различных конструкций...
Индивидуальные и групповые автопоилки: для животных. Схемы и конструкции...
Топ:
Техника безопасности при работе на пароконвектомате: К обслуживанию пароконвектомата допускаются лица, прошедшие технический минимум по эксплуатации оборудования...
Оценка эффективности инструментов коммуникационной политики: Внешние коммуникации - обмен информацией между организацией и её внешней средой...
Установка замедленного коксования: Чем выше температура и ниже давление, тем место разрыва углеродной цепи всё больше смещается к её концу и значительно возрастает...
Интересное:
Влияние предпринимательской среды на эффективное функционирование предприятия: Предпринимательская среда – это совокупность внешних и внутренних факторов, оказывающих влияние на функционирование фирмы...
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Мероприятия для защиты от морозного пучения грунтов: Инженерная защита от морозного (криогенного) пучения грунтов необходима для легких малоэтажных зданий и других сооружений...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Итак, задача построения пирамиды из массива успешно решена. Как видно из свойств пирамиды, в корне всегда находится максимальный элемент. Отсюда вытекает алгоритм фазы 2:
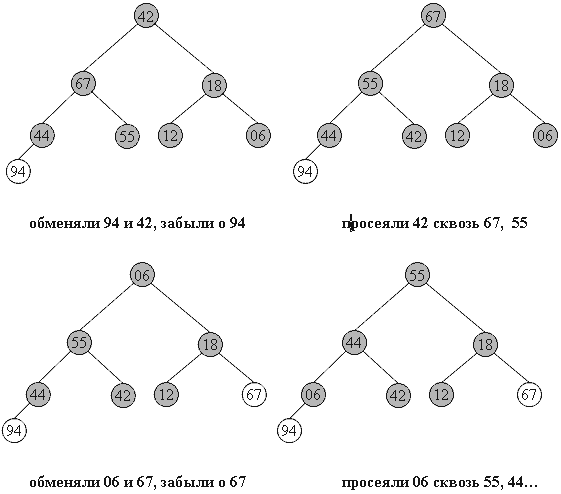
Очевидно, в конец массива каждый раз попадает максимальный элемент из текущей пирамиды, поэтому в правой части постепенно возникает упорядоченная последовательность.
94 67 18 44 55 12 06 42 // иллюстрация 2-й фазы сортировки
67 55 44 06 42 18 12 // 94 во внутреннем представлении пирамиды
55 42 44 06 12 18 // 67 94
44 42 18 06 12 // 55 67 94
42 12 18 06 // 44 55 67 94
18 12 06 // 42 44 55 67 94
12 06 // 18 42 44 55 67 94
06 // 12 18 42 44 55 67 94
Код внешней процедуры сортировки:
template<class T>
void heapSort(T a[], long size) {
long i;
T temp;
// строим пирамиду
for(i=size/2-1; i >= 0; i--) downHeap(a, i, size-1);
// теперь a[0]...a[size-1] пирамида
for(i=size-1; i > 0; i--) {
// меняем первый с последним
temp=a[i]; a[i]=a[0]; a[0]=temp;
// восстанавливаем пирамидальность a[0]...a[i-1]
downHeap(a, 0, i-1);
}
}
Каково быстродействие получившегося алгоритма?
Построение пирамиды занимает O(n log n) операций, причем более точная оценка дает даже O(n) за счет того, что реальное время выполнения downheap зависит от высоты уже созданной части пирамиды.
Вторая фаза занимает O(n log n) времени: O(n) раз берется максимум и происходит просеивание бывшего последнего элемента. Плюсом является стабильность метода: среднее число пересылок (n log n)/2, и отклонения от этого значения сравнительно малы.
|
|
Пирамидальная сортировка не использует дополнительной памяти.
Метод не является устойчивым: по ходу работы массив так "перетряхивается", что исходный порядок элементов может измениться случайным образом.
Поведение неестественно: частичная упорядоченность массива никак не учитывается.
Быстрая сортировка (quick)
"Быстрая сортировка", хоть и была разработана более 40 лет назад, является наиболее широко применяемым и одним их самых эффективных алгоритмов.
Метод основан на подходе "разделяй-и-властвуй". Общая схема такова:

В конце получится полностью отсортированная последовательность.
Рассмотрим алгоритм подробнее.
Разделение массива
На входе массив a[0]...a[N] и опорный элемент p, по которому будет производиться разделение.
Рассмотрим работу процедуры для массива a[0]...a[6] и опорного элемента p = a[3].

Теперь массив разделен на две части: все элементы левой меньше либо равны p, все элементы правой - больше, либо равны p. Разделение завершено.
Общий алгоритм
Псевдокод.
quickSort (массив a, верхняя граница N) { Выбрать опорный элемент p - середину массива Разделить массив по этому элементу Если подмассив слева от p содержит более одного элемента, вызвать quickSort для него. Если подмассив справа от p содержит более одного элемента, вызвать quickSort для него. }Реализация на Си.
|
|
Каждое разделение требует, очевидно, Theta(n) операций. Количество шагов деления(глубина рекурсии) составляет приблизительно log n, если массив делится на более-менее равные части. Таким образом, общее быстродействие: O(n log n), что и имеет место на практике.
Однако, возможен случай таких входных данных, на которых алгоритм будет работать за O(n2) операций. Такое происходит, если каждый раз в качестве центрального элемента выбирается максимум или минимум входной последовательности. Если данные взяты случайно, вероятность этого равна 2/n. И эта вероятность должна реализовываться на каждом шаге... Вообще говоря, малореальная ситуация.
Метод неустойчив. Поведение довольно естественно, если учесть, что при частичной упорядоченности повышаются шансы разделения массива на более равные части.
Сортировка использует дополнительную память, так как приблизительная глубина рекурсии составляет O(log n), а данные о рекурсивных подвызовах каждый раз добавляются в стек.
Модификации кода и метода
1. Из-за рекурсии и других "накладных расходов" Quicksort может оказаться не столь уж быстрой для коротких массивов. Поэтому, если в массиве меньше CUTOFF элементов (константа зависит от реализации, обычно равна от 3 до 40), вызывается сортировка вставками. Увеличение скорости может составлять до 15%.
Для проведения метода в жизнь можно модифицировать функцию quickSortR, заменив последние 2 строки на
if (j > CUTOFF) quickSortR(a, j); if (N > i + CUTOFF) quickSortR(a+i, N-i);Таким образом, массивы из CUTOFF элементов и меньше досортировываться не будут, и в конце работы quickSortR() массив разделится на последовательные части из <=CUTOFF элементов, отсортированные друг относительно друга. Близкие элементы имеют близкие позиции, поэтому, аналогично сортировке Шелла, вызывается insertSort(), которая доводит процесс до конца.
|
|
Рассмотрим наихудший случай, когда случайно выбираемые опорные элементы оказались очень плохими(близкими к экстремумам). Вероятность этого чрезвычайно мала, уже при n = 1024 она меньше 2-50, так что интерес скорее теоретический, нежели практический. Однако, поведение "быстрой сортировки" является "эталоном" для аналогично реализованных алгоритмов типа "разделяй-и-властвуй". Не везде можно свести вероятность худшего случая практически к нулю, поэтому такая ситуация заслуживает изучения.
Пусть, для определенности, каждый раз выбирается наименьший элемент amin. Тогда процедура разделения переместит этот элемент в начало массива и на следующий уровень рекурсии отправятся две части: одна из единственного элемента amin, другая содержит остальные n-1 элемента массива. Затем процесс повторится для части из (n-1) элементов.. И так далее..
При использовании рекурсивного кода, подобного написанному выше, это будет означать n вложенных рекурсивных вызовов функции quickSort.
Каждый рекурсивный вызов означает сохранение информации о текущем положении дел. Таким образом, сортировка требует O(n) дополнительной памяти.. И не где-нибудь, а в стеке. При достаточно большом n такое требование может привести к непредсказуемым последствиям.
|
|
Для исключения подобной ситуации можно заменить рекурсию на итерации, реализовав стек на основе массива. Процедура разделения будет выполняться в виде цикла.
Каждый раз, когда массив делится на две части, в стек будет направляться запрос на сортировку большей из них, а меньшая будет обрабатываться на следующей итерации. Запросы будут выбираться из стека по мере освобождения процедуры разделения от текущих задач. Сортировка заканчивает свою работу, когда запросы кончаются.
Псевдокод.
Итеративная QuickSort (массив a, размер size) {Положить в стек запрос на сортировку массива от 0 до size-1. do { Взять границы lb и ub текущего массива из стека. do { 1. Произвести операцию разделения над текущим массивом a[lb..ub]. 2. Отправить границы большей из получившихся частей в стек. 3. Передвинуть границы ub, lb чтобы они указывали на меньшую часть. } пока меньшая часть состоит из двух или более элементов } пока в стеке есть запросы}Реализация на Си.
#define MAXSTACK 2048 // максимальный размер стека template<class T>void qSortI(T a[], long size) { long i, j; // указатели, участвующие в разделении long lb, ub; // границы сортируемого в цикле фрагмента long lbstack[MAXSTACK], ubstack[MAXSTACK]; // стек запросов // каждый запрос задается парой значений, // а именно: левой(lbstack) и правой(ubstack) // границами промежутка long stackpos = 1; // текущая позиция стека long ppos; // середина массива T pivot; // опорный элемент T temp; lbstack[1] = 0; ubstack[1] = size-1; do { // Взять границы lb и ub текущего массива из стека. lb = lbstack[ stackpos ]; ub = ubstack[ stackpos ]; stackpos--; do { // Шаг 1. Разделение по элементу pivot ppos = (lb + ub) >> 1; i = lb; j = ub; pivot = a[ppos]; do { while (a[i] < pivot) i++; while (pivot < a[j]) j--; if (i <= j) { temp = a[i]; a[i] = a[j]; a[j] = temp; i++; j--; } } while (i <= j); // Сейчас указатель i указывает на начало правого подмассива, // j - на конец левого (см. иллюстрацию выше), lb? j? i? ub. // Возможен случай, когда указатель i или j выходит за границу массива // Шаги 2, 3. Отправляем большую часть в стек и двигаем lb,ub if (i < ppos) { // правая часть больше if (i < ub) { // если в ней больше 1 элемента - нужно stackpos++; // сортировать, запрос в стек lbstack[ stackpos ] = i; ubstack[ stackpos ] = ub; } ub = j; // следующая итерация разделения // будет работать с левой частью } else { // левая часть больше if (j > lb) { stackpos++; lbstack[ stackpos ] = lb; ubstack[ stackpos ] = j; } lb = i; } } while (lb < ub); // пока в меньшей части более 1 элемента } while (stackpos!= 0); // пока есть запросы в стеке}Размер стека при такой реализации всегда имеет порядок O(log n), так что указанного в MAXSTACK значения хватает с лихвой.
|
|
|

Опора деревянной одностоечной и способы укрепление угловых опор: Опоры ВЛ - конструкции, предназначенные для поддерживания проводов на необходимой высоте над землей, водой...

Состав сооружений: решетки и песколовки: Решетки – это первое устройство в схеме очистных сооружений. Они представляют...

Папиллярные узоры пальцев рук - маркер спортивных способностей: дерматоглифические признаки формируются на 3-5 месяце беременности, не изменяются в течение жизни...

История создания датчика движения: Первый прибор для обнаружения движения был изобретен немецким физиком Генрихом Герцем...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!