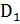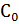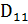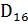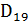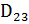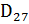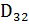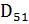При работе с полупроводниковой памятью не исключено возникновение различного рода отказов и сбоев. Причиной отказов могут быть производственные дефекты, повреждение микросхем или их физический износ. Проявляются отказы в том, что в отдельных разрядах одной или нескольких ячеек постоянно считывается 0 или 1, вне зависимости от реально записанной туда информации. Сбой — это случайное событие, выражающееся в неверном считывании или записи информации в отдельных разрядах одной или нескольких ячеек, не связанное с дефектами микросхемы. Сбои обычно обусловлены проблемами с источником питания или с воздействием альфа-частиц, возникающих в результате распада радиоактивных элементов, которые в небольших количествах присутствуют практически в любых материалах. Как отказы, так и сбои крайне нежелательны, поэтому в большинстве систем основной памяти содержатся схемы, служащие для обнаружения и исправления ошибок.
Вне зависимости от того, как именно реализуется контроль и исправление ошибок, в основе их всегда лежит введение избыточности. Это означает, что контролируемые разряды дополняются контрольными разрядами, благодаря которым и возможно детектирование ошибок, а в ряде методов — их коррекция. Общую схему обнаружения и исправления ошибок иллюстрирует рис. 4.6
Перед записью М -разрядных данных в память производится их обработка, обозначенная на схеме функцией ≪f≫, в результате которой формируется добавочный К -разрядный код. В память заносятся как данные, так и этот вычисленный код, то есть (М + К)-разрядная информация. При чтении информации повторно формируется К -разрядный код, который сравнивается с аналогичным кодом, считанным из ячейки. Сравнение приводит к одному из трех результатов:
· Не обнаружено. ни одной ошибки. Извлеченные из ячейки данные подаются на выход памяти.
· Обнаружена ошибка, и она может быть исправлена. Биты данных и добавочного кода подаются на схему коррекции. После исправления ошибки в М -разрядных данных они поступают на выход памяти.
· Обнаружена ошибка, и она не может быть исправлена. Выдается сообщение о неисправимой ошибке.

Рис. 4.6.Общая схема обнаружения и исправления ошибок
Коды, используемые для подобных операций, называют корректирующими кодами или кодами с исправлением ошибок.
Простейший вид такого кода основан на добавлении к каждому байту информации одного бита паритета. Бит паритета — это дополнительный бит, значение которого устанавливается таким, чтобы суммарное число единиц в данных, с учетом этого дополнительного разряда, было четным (или нечетным). В некоторых системах за основу берется четность, в иных — нечетность. Для 64-разрядного слова требуется восемь битов паритета, то есть ячейка памяти должна хранить 36 разрядов. При записи слова в память для каждого байта формируется бит паритета. Это может быть сделано с помощью схемы в виде дерева, составленного из схем сложения по модулю 2. При чтении из памяти выполняется аналогичная операция над считанными информационными битами, а ее результат сравнивается с битом паритета, вычисленным при записи и хранившимся в памяти. Метод позволяет обнаружить ошибку, если исказилось нечетное количество битов. При четном числе ошибок метод неработоспособен. К сожалению, фиксируя ошибку, данный способ кодирования не может указать на ее местоположение, что позволило бы внести исправления, в силу чего его называют кодом с обнаружением ошибки (EDC — ErrorDetectionCode).
В основе корректирующих кодов лежит достаточно простая идея [30]. Для контроля двоичного информационного кода длиной M битов добавим к ней K дополнительных контрольных разрядов так, что общая длина последовательности теперь будет равна M + K разрядам. В этом случае из возможных N = 2 M+K комбинаций интерес представляют только L = 2 M последовательностей, которые называют разрешенными. Оставшиеся N – L последовательностей назовем запрещенными. Если при обработке (записи в память, считывании или передаче) разрешенной кодовой последовательности произойдут ошибки и возникнет одна из запрещенных последовательностей, то тем самым эти ошибки обнаруживаются. Если же ошибки превратят одну разрешенную последовательность в другую, то такие ошибки не могут быть обнаружены. Для исправления ошибок необходимо произвести разбиение множества запрещенных последовательностей на L непересекающихся подмножеств и каждому подмножеству поставить в соответствие одну из разрешенных последовательностей. Тогда, если была принята некоторая запрещенная последовательность, входящая в одно из подмножеств, считается, что передана разрешенная последовательность, соответствующая этому подмножеству, производится замена, чем и исправляется возникшая ошибка.
Простейший вариант корректирующего кода также может быть построен на базе битов паритета. Для этого биты данных представляются в виде матрицы, к каждой строке и столбцу которой добавляется бит паритета. Для 64-разрядных данных этот подход иллюстрирует табл. 4.1. Здесь D — биты данных, C — столбец битов паритета строк, K — строка битов паритета столбцов, P — бит паритета, контролирующий столбец С и строку К. Таким образом, к 64 битам данных нужно добавить 17 битов паритета: по 8 битов на строки и столбцы и один дополнительный бит для контроля строки и столбца битов паритета. Если в одной строке и одном столбце обнаружено нарушение паритета, для исправления ошибки достаточно просто инвертировать бит на пересечении этих строки и столбца. Если ошибка паритета выявлена только в одной строке или только одном столбце либо одновременно в нескольких строках и столбцах, фиксируется многобитовая ошибка и формируется признак невозможности коррекции.
Таблица 4.1. Формирование корректирующего кода для 64-битовых данных
Вопрос 10. Стековая память.
Стековая память обеспечивает такой режим работы, когда информация записывается и считывается по принципу ≪ последним записан — первым считан ≫ (LIFO —LastInFirstOut). Память с подобной организацией широко применяется для запоминания и восстановления содержимого регистров процессора при обработке подпрограмм и прерываний. Работу стековой памяти поясняет рис. 4.8, а. Когда слово A заносится в стек, оно располагается в первой свободной ячейке.
Каждое следующее записываемое слово перемещает все содержимое стека на одну ячейку вверх и занимает освободившуюся ячейку. Запись очередного кода, после H, приводит к переполнению стека и потере кода A. Считывание кодов из стека осуществляется в обратном порядке, то есть начиная с кода H, который был записан последним. Отметим, что доступ к произвольному коду в стеке формально недопустим до извлечения всех кодов, записанных позже.

Наиболее распространенным в настоящее время является внешний или аппаратно-программный стек, в котором для хранения информации используется область ОП. Обычно для этих целей отводится участок памяти с наибольшими адресами, а стек расширяется в сторону уменьшения адресов. Так как программа обычно загружается, начиная с меньших адресов, такой прием во многих случаях позволяет избежать перекрытия областей программы и стека. Адресация стека обеспечивается специальным регистром — указателем стека (SP — stackpointer), в который предварительно помещается наибольший адрес области основной памяти, отведенной под стек (рис. 4.8, б). При занесении в стек очередного слова сначала производится уменьшение на единицу содержимого указателя стека (УС), которое затем используется как адрес ячейки, куда и производится запись, то есть указатель стека хранит адрес той ячейки, к которой было произведено последнее обращение. Это можно описать в виде: УС:= УС – 1; ОП[(УС)]:= ШД. При считывании слова из стека в качестве адреса этого слова берется текущее содержимое указателя стека, а после того как слово извлечено, содержимое УС увеличивается на единицу. Таким образом, при извлечении слова из стека реализуются следующие операции: ШД:= ОП[(УС)]; УС:= УС + 1.
Вопрос 11.Кэш-память.
В большинстве ВМ основная память строится на базе микросхем динамических ОЗУ, на порядок уступающих по быстродействию центральному процессору. Замена динамических запоминающих устройств на статические ведет к весьма существенному удорожанию ОП. Экономически приемлемое решение этой проблемы, предложенное М. Уилксом, заключается в том, что между ОП и процессором размещается небольшая, но быстродействующая буферная память, куда в процессе работы копируются те участки ОП, к которым производится обращение со стороны процессора. Выигрыш достигается за счет ранее рассмотренного свойства локальности – если скопировать содержимое участка ОП в более быстродействующую буферную память и переадресовать на нее все обращения в пределах скопированного участка, то можно существенно сократить среднее время доступа к информации. Упомянутая буферная память получила название кэш-память (от английского слова cache — убежище, тайник), поскольку она обычно скрыта от программиста в том смысле, что он не может ее адресовать и может даже вообще не знать о ее существовании.
В общем виде использование кэш-памяти (КП) поясним следующим образом. Когда ЦП пытается прочитать слово из основной памяти, сначала осуществляется поиск копии этого слова в КП. Если такая копия существует, обращение к ОП не производится, а в ЦП передается слово, извлеченное из кэш-памяти. Данную ситуацию принято называть успешным обращением или попаданием (hit). При отсутствии слова в кэш-памяти, то есть при неуспешном обращении (промахе miss), блок данных, содержащий это слово, сначала пересылается из ОП в кэш-память, а затем уже из КП затребованное слово передается в ЦП.

На рис. 4.14 приведена структура системы памяти, включающая как основную, так и кэш-память. ОП емкостью 2n слов при взаимодействии с кэш-памятью рассматривается как состоящее из M блоков фиксированной длины по K слов в каждом(M = 2n/ K). Кэш-память также условно разбивается на C блоков аналогичного размера, причем С << M. При обращении к какой-либо ячейке ОП блок, содержащий данную ячейку, копируется в какой-то из блоков кэш-памяти, и все последующие обращения к блоку переадресовываются на его копию в КП. Ввиду малой емкости в кэш-памяти в разное время могут находиться копии различных блоков ОП. По этой причине каждую копию необходимо снабдить так называемым тегом (признаком), указывающим на то, копия какого блока ОП в настоящий момент хранится в данном блоке КП. В результате кэш-память представляет собой совокупность двух ЗУ, одно из которых предназначено для хранения копий данных из ОП (память данных), а второе — для хранения тегов этих копий (память тегов). Каждому блоку в памяти данных соответствует одна ячейка в памяти тегов.
Эффективность применения кэш-памяти в иерархической системе памяти зависит от целого ряда факторов, к наиболее существенным из которых следует отнести:
- емкость кэш-памяти;
- размер блока;
- способ отображения основной памяти на кэш-память;
- алгоритм замещения информации в заполненной кэш-памяти;
- алгоритм согласования содержимого основной и кэш-памяти;
- число уровней кэш-памяти.
Емкость кэш-памяти. С одной стороны, кэш-память должна быть достаточно мала, чтобы ее стоимостные показатели были близки к величине, характерной для ОП. С другой — она должна быть достаточно большой, чтобы среднее время доступа в системе, состоящей из основной и кэш-памяти, определялось временем доступа к кэш-памяти.
Размер блока. Когда в кэш-память помещается блок, вместе с требуемым словом туда попадают и соседние слова. По мере увеличения размера блока вероятность промахов сначала падает, так как в кэш, согласно принципу локальности, попадает все больше данных, которые понадобятся в ближайшее время. Однако когда размер блока становится излишне большим, вероятность промахов начинает расти (рис. 4. 15). Объясняется это тем, что:
- большие размеры блока уменьшают общее количество блоков, которые можно загрузить в кэш-память, а малое число блоков приводит к необходимости частой их смены;
- по мере увеличения размера блока каждое дополнительное слово оказывается дальше от запрошенного, поэтому такое дополнительное слово менее вероятно понадобится в ближайшем будущем.
Способы отображения оперативной памяти на кэш-память. Сущность отображения блока основной памяти на кэш-память состоит в его копировании в какой-либо из блоков кэш-памяти, после чего все обращения к блоку в ОП должны переадресовываться на копию в кэш-памяти.
Прямое отображение. При прямом отображении множество блоков основной памяти условно представляется в виде матрицы, в которой количество строк равно числу блоков в кэш-памяти m (рис. 6.31). В блок кэш-памяти с номером i может быть помещен любой блок ОП, но только из i-й строки матрицы.
Номер строки (i) и столбца (k) матрицы, на пересечении которых располагается блок основной памяти с адресом j, определяются выражениями i = j mod m и k = j div m. В двоичной записи адреса блока основной памяти номер строки представлен log2 m младшими разрядами, а номер столбца — оставшимися старшими разрядами. Такая система позволяет по адресу блока основной памяти, поступившему из ЦП, сразу же однозначно определить адрес блока кэш-памяти, куда должен быть отображен данный блок ОП (если его копия в КП отсутствует) или где следует искать соответствующую копию (если она присутствует в КП).
В качестве указателя того, какой из блоков i-й строки отображен или должен быть отображен на i-й блок КП (тега), используется номер столбца матрицы, где расположен отображенный (отображаемый) блок ОП.
Прямое отображение — простой и недорогой в реализации способ отображения. К его достоинствам можно отнести малую разрядность тега (для нашего примера она равна 7 битам). Кроме того, при проверке наличия в КП нужной копии достаточно проверить лишь одну определенную ячейку памяти тегов.

Рис. 4.16. Организация кэш-памяти с прямым отображением
Основной его недостаток — жесткое закрепление за определенными блоками ОП одного блока в КП. Поэтому если программа поочередно обращается к словам из двух различных блоков, отображаемых на одну и тут же строку кэш-памяти, постоянно станет происходить обновление данной строки и вероятность попадания будет низкой.
Одноуровневая и многоуровневая кэш-память. Логично предположить, что с увеличением емкости кэш-памяти можно ожидать и соответствующего повышения быстродействия ВМ. Современные технологии позволяют разместить на общем с процессором кристалле кэш-память достаточно большой емкости. С другой стороны, попытки увеличения емкости обычно приводят к снижению быстродействия, главным образом из-за усложнения схем управления и дешифрации адреса. По этой причине общую емкость кэш-памяти ВМ увеличивают за счет иерархической организации, при которой кэш-память состоит из нескольких уровней запоминающих устройств, отличающихся емкостью и быстродействием. Каждый последующий уровень имеет большую емкость по сравнению с предыдущим, но и меньшее быстродействие. Первый уровень (L1) иерархии образует наиболее скоростная кэш-память сравнительно небольшой емкости (не более 128 Кбайт). На кристалле ее располагают по возможности ближе к процессору, чтобы минимизировать длину соединяющей их шины и тем самым способствовать ускорению обмена информацией. Этот уровень в перспективных микропроцессорах обычно строится по разделенной схеме. Так, в многоядерном процессоре Nehalem фирмы Intel каждому ядру (процессору) придается кэш-память команд емкостью 32 Кбайт (4-входовая, модульно-ассоциативная) и кэш-память данных емкостью 32 Кбайт (8-входовая, модульно-ассоциативная).
Вопрос 12.Понятие виртуальной памяти.