КОНСПЕКТ ЛЕКЦИЙ
по дисциплине «Базы данных»
Рекомендовано Советом факультета «Информатика и вычислительная техника» к использованию в качестве учебно-методических материалов для применения в учебном процессе для специальностей 230102.65 "Автоматизированные системы обработки информации и управления" и 230104.65 "Системы автоматизированного проектирования",
форма обучения очная и заочная по дисциплине «Базы данных» (протокол № 3 от 7.11.2013 г.)
Ижевск 2013
Рецензент: Мокроусов М.Н., канд. техн. наук, доцент кафедры «автоматизированные системы обработки информации и управления» ИжГТУ
Составители: Соболева Н.В.
Рекомендовано Советом факультета «Информатика и вычислительная техника» к использованию в качестве учебно-методических материалов для использования в учебном процессе для специальностей 230102.65 "Автоматизированные системы обработки информации и управления" и 230104.65 "Системы автоматизированного проектирования"
форма обучения очная и заочная по дисциплине «Базы данных» (протокол № 3 от 7.11.2013 г.)
|
| Конспект лекций по дисциплине «Базы данных»: учеб.-метод. пособие / сост. Н.В. Соболева. – Ижевск, 2013. – 68 с.
|
В методических указаниях приводятся требования к содержанию пояснительной записки к курсовой работе, определяются этапы выполнения работы, даются указания по выполнению основных видов работ и написанию разделов пояснительной записки, приводится образец задания на курсовую работу, и даётся список возможных тем.
Указания предназначены для студентов, обучающихся по специальностям 230102.65 "Автоматизированные системы обработки информации и управления" и 230104.65 "Системы автоматизированного проектирования" (очная и заочная форма обучения).
© Н.В. Соболева, составление, 2013
© ФГБОУ ВПО «ИжГТУ имени М.Т. Калашникова», 2013
СОДЕРЖАНИЕ
1 Введение. 6
Базы данных и информационные системы. Основные понятия. 6
Жизненный цикл баз данных. 6
2 Обзор СУБД.. 7
2.1 Функции СУБД.. 7
Состояние рынка СУБД.. 8
Современные подходы к проектированию архитектуры ИС.. 9
Локальные ИС.. 9
ИС в локальных сетях. 10
Двухзвенные модели. 13
Монитор транзакций. 15
ИС в Internet и intranet 16
3 Проектирование базы данных на концептуальном уровне. 18
Основные понятия. 18
Задачи моделирования данных. 18
Сущности. 18
Атрибуты.. 19
Ключи. 20
Связи. 20
Классы и подклассы.. 21
Источники данных для концептуального проектирования. 21
Построение концептуальной схемы.. 22
4 Проектирование базы данных на логическом уровне. 24
Исходные данные для проектирования. 24
Результаты проектирования. 24
Требования к эксплуатационным характеристикам.. 24
3.4 Особенности учета требований при проектировании БД.. 25
Модели данных логического уровня. 25
Иерархическая модель. 26
Сетевая модель. 26
5 Реляционная модель данных. 30
Основные понятия. 30
Целостность реляционной модели. 31
Математическое описание реляционной модели. 32
Реляционная алгебра. Теоретико-множественные операции. 33
Реляционная алгебра. Специальные реляционные операции. 33
Дополнительные реляционные операции. 34
Примеры записи запросов. 35
Реляционное исчисление. 36
6 Проектирование реляционной модели. 37
Нормализация модели. 37
Функциональная зависимость. 37
Теоремы о функциональных зависимостях. 38
Нормальные формы отношений. 38
Алгоритм нормализации отношений. Метод декомпозиции. 39
7 Проектирование реляционной модели на основе концептуальной модели 42
Реализация бинарной связи 1:1. 42
Связь всюду определённая. 42
Связь частичная для одной из сущностей. 42
Связь частичная для обеих сущностей. 43
Реализация бинарной связи 1:m.. 44
Связь всюду определённая для m-связной сущности. 44
Связь частичная для m-связной сущности. 44
Бинарная связь n:m.. 45
Связи более высокого порядка. 45
Классы и подклассы.. 46
8 Физическая модель данных. 48
8.1 Исходные данные для физического проектирования. 48
8.2 Возможная методика перехода к физической модели на примере реляционной модели 48
8.2.1 Преобразование отношений в таблицы.. 48
8.2.2 Преобразование атрибутов в поля (столбцы) таблиц. 48
8.2.3 Преобразование доменов в типы данных. 49
Первичные ключи. 49
Порядок расположения столбцов. 50
Создание ссылочных ограничений. 50
Факторы, влияющие на производительность БД.. 50
Индексы.. 50
Денормализация. 52
Проблемы, требующие решения. 53
Запросы.. 53
Представления. 54
Курсоры.. 54
Хранимые процедуры.. 55
Триггеры.. 55
Функции, определяемые пользователем.. 55
Транзакции. 55
10 Введение в SQL.. 56
Стандарты.. 56
Возможности SQL.. 56
Примеры запросов. 57
11.Рекомендуемая литература. 68
Введение
Базы данных и информационные системы. Основные понятия
Информационная система (ИС)- система, реализующая автоматизированный сбор, обработку и манипулирование данными и включающая технические средства обработки данных, программное обеспечение и соответствующий персонал.
Вычислительная система – это совокупность взаимосвязанных и согласованно действующих компьютеров и других устройств, обеспечивающих функционирование ИС.
Банк данных – это разновидность ИС, которая обеспечивает централизованное накопление и коллективное использование данных.
База данных (БД) – именованная совокупность данных, отражающая состояние объектов рассматриваемой проблемной области (ПО) и отношения объектов между собой и хранящаяся на машинных носителях.
СУБД – совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования баз данных. СУБД обеспечивает независимость данных и программ.
Жизненный цикл баз данных
Этап 1. Проектирование.
1.1.Анализ проблемной области и запросов к БД (концептуальный уровень проектирования).
Выбор средств реализации и построение логической модели данных (логический уровень проектирования).
Физическое проектирование (физический уровень проектирования).
Этап 2. Эксплуатация баз данных.
Генерация физической модели данных.
Подготовка среды хранения.
Ввод и контроль данных.
Этап3. Эксплуатация баз данных.
3.1. Поддержка работы приложений.
3.2. Генерация отчетов.
3.3. Администрирование баз данных.
3.3.1. Разграничение доступа.
3.3.2. Поддержка целостности БД.
3.3.3. Копирование и восстановление БД.
3.3.4. Реорганизация БД и т.д.
Обзор СУБД
Функции СУБД
Поддержка модели данных.
СУБД различаются по моделям данных, на которых они базируются.
Модель данных – это набор понятий, использующихся для описания данных. Модель определяет способ хранения данных и способ манипулирования данными.
Наиболее известны следующие модели данных:
иерархическая;
сетевая или CODASIL;
реляционная;
объектно-ориентированная.
Обеспечение независимости данных и программ.
Любая СУБД предоставляет программистам API (Application Programming Interface) для работы с БД, что позволяет избегать изменения программ из-за изменения баз данных.
Основным API для реляционных БД является язык SQL. При внесении изменений в базу большинство операторов в SQL-программе изменять не требуется.
Обеспечение безопасности данных.
Запрет неавторизованным пользователям просматривать и обновлять базу данных и др.
4. Управление параллельным доступом.
Предоставление доступа множеству параллельно выполняющихся пользовательских программ.
5. Ведение журнала регистрации баз данных (журнал транзакций).
6. Поддержка целостности баз данных.
Обеспечение хранения правильных данных в базе данных.
7. Обеспечение доступа к данным.
СУБД предоставляют стандартный язык запросов, позволяющий интерактивно запрашивать базу данных и анализировать данные.
Для реляционных баз данных этим стандартным языком является SQL – язык структурированных запросов.
Кроме SQL СУБД может предоставлять еще более простые инструменты доступа к данным.
Более подробно о функциях СУБД можно прочитать, например, в книгах Дейта.
Состояние рынка СУБД
Условно, компании, присутствующие на рынке СУБД, можно разбить на ряд групп.
1. Лидеры.
Наибольшее количество установленных СУБД и наибольшее число продаж приходится на три компании:
- Oracle Corporation (СУБД Oracle);
- IBM Corporation (СУБД DB2);
- Microsoft (СУБД MS SQL Server).
СУБД Oracle: наибольшее количество проданных копий для всех платформ. СУБД DB2: монопольно используется на рынке мейнфреймов; растет объем продаж для UNIX и Windows; последнее обновление под кодовым названием Stinger обладает лучшими возможностями по сравнению с СУБД MS SQL Server.
СУБД MS SQL Server работает только под Windows; для этой платформы является лидером.
2. Поставщики второго уровня.
В эту группу входят крупные поставщики СУБД со стабильными продуктами, но уступающими лидерам по функциональным возможностям и количеству пользователей. Эти компании были лидерами на рынке СУБД в 80-ых годах прошлого века.
Компания Sybase была новатором в технологии баз данных, ввела такие понятия, как принцип клиент/сервер, хранимые процедуры и др. СУБД MS SQL Server во многом основывается на технологиях Sybase.
Компания Informix: все преимущества СУБД Informix были переняты IBM в своих разработках.
3. Другие крупные поставщики.
СУБД Ingres (Computer Associates). Много пользователей, особенно в Европе. В 2003 г. объявлено о плане возврата СУБД в "общественное пользование" для применения совместно с сервером Java-приложений.
СУБД Adabas, СУБД Tamino (Software AG).
СУБД Adabas ведет свое происхождение от СУБД инвертированных списков, которая была усовершенствована до реляционной.
СУБД Tamino является новой, основанной на XML, СУБД.
СУБД Interbase (Borland). С 2000 г. СУБД Interbase 6.0 перешла в разряд продуктов с открытым исходным кодом.
4. Поставщики СУБД с открытым исходным кодом.
Термин "открытый исходный код" означает программное обеспечение, которое пользователи могут бесплатно запускать, копировать, распространять, изучать, изменять и улучшать.
Можно выделить двух лидеров:
PostgreSQL и MySQL.
СУБД PostgreSQL распрстраняется вместе с Linux.
MySQL является многопользовательским, многопроцессным SQL-сервером баз данных. Он доступен для свободной загрузки на сайте http://www.mysql.com, но технически он не является СУБД с открытым исходным кодом. Необходимо заплатить за лицензию при продаже MySQL или при включении его в качестве компонента в других продуктах. Таким образом, MySQL бесплатен только под Unix и OS/2. Для платформы Windows требуется лицензия.
5. Поставщики объектно-ориентированных СУБД.
В конце 80-ых начале 90-ых годов начали активно развиваться объектно-ориентированные СУБД (ODBS). По многим причинам (трудно запрашивать, нет надежной модели данных и др.) эта технология не стала широко распрстраненной.
Известны следующие СУБД:
UniQSL, Poet, Object Store, Ontos, Jasmine и др.
6. Поставщики СУБД, предназначенные для ПК.
Access, Visual Foxpro (Microsoft).
Paradox (Corel).
dBase и др.
Локальные ИС
Рассмотрим вариант построения ИС на одном ПК.
Возможны следующие способы использования программных средств:
1) СУБД в полном объеме;
2) приложения и ядро СУБД;
3) независимое приложение.
По первому варианту пользователь непосредственно обращается к СУБД через ее интерфейс или через приложение. Приложение выполняется обычно в режиме интерпретации (рисунок 2.1).
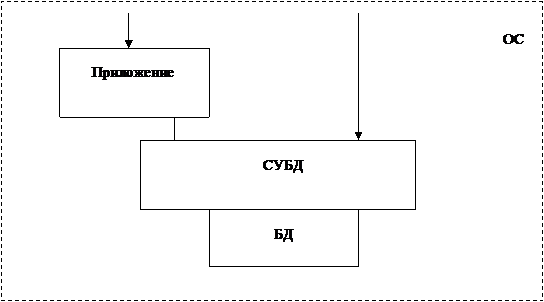
Рисунок 2.1 – СУБД в полном объёме
По второму варианту на ПК устанавливается ядро СУБД (run-time версия). Ядро не содержит средств, позволяющих модифицировать приложения, что обеспечивает их защиту. В ядре могут отсутствовать средства разработки баз данных. Приложение работает, как правило, в режиме интерпретации (рисунок 2.2).
По третьему варианту на ПК устанавливается независимое приложение (откомпилированный исходный код) (рисунок 2.3).
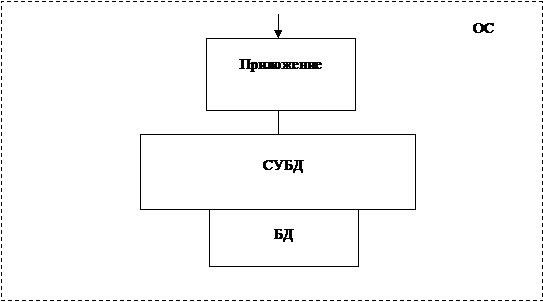
Рисунок 2.2 - Приложение и ядро СУБД

Рисунок 2.3 - Независимое приложение
ИС в локальных сетях
Возможны следующие варианты:
1) система типа файл-сервер с несетевой СУБД;
2) система типа файл-сервер с сетевой СУБД;
3) система типа клиент-сервер.
ИС по варианту 1 может быть построена, но такая архитектура обладает рядом недостатков, которые в большинстве случаев делают такую архитектуру нежизнеспособной.
Архитектура типа файл-сервер с использованием сетевой СУБД представлена на рисунке 2.4.
Типичное файл-серверное приложение работает следующим образом. Обработка данных ведётся рабочей станцией клиента, а сервер служит просто как дополнительное доступное всем пользователям, дисковое устройство. Это означает, что при выполнении задачи, например, при сборке отчёта, вся база данных или значительная её часть прокачивается по сети на рабочую станцию и там обрабатывается процессором рабочей станции.
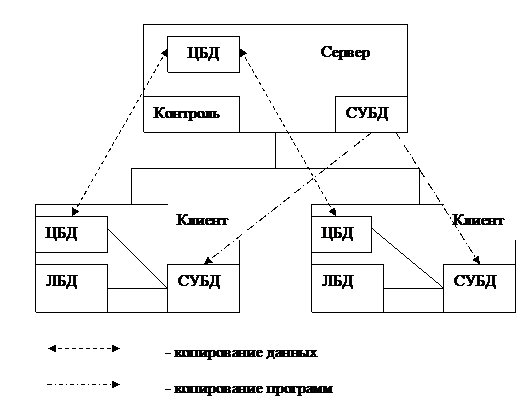
ЦБД – централизованная БД
ЛБД – локальная БД
Рисунок 2.4 - Файл-серверная архитектура
Быстродействие такой системы зависит от быстродействия диска сервера, скорости передачи данных по сети, мощности процессора рабочей станции, объёма её оперативного запоминающего устройства и некоторых других факторов. Центральный процессор сервера играет второстепенную роль и должен просто обеспечивать передачу потока данных с сетевого канала на диск и обратно.
Если несколько рабочих станций клиента одновременно выполняют сборку отчётов, то на все эти рабочие станции закачивается база данных, и система существенно замедляет работу из-за перегрузки сети.
Для решения задачи синхронизации доступа клиентов к данным в файл-серверной архитектуре используются различные файлы блокировок на диске файл-сервера. В эти файлы каждая рабочая станция клиента записывает информацию о данных, которые они модифицируют в данный момент, а при попытке считать данные проверяет, не заняты ли эти данные другой станцией. Такой способ управления блокировками вполне работоспособен, хотя и имеет ряд недостатков, например таких, как появление висячих блокировок при аварийном отключении питания или замедление работы свей системы при модификации большого числа записей.
Особенностью файл-серверной системы является необходимость проводить ежедневное архивирование, во время которого ни один из пользователей не может работать с базой данных.
Таким образом, производительность файл-серверной системы зависит от объёма обрабатываемой и передаваемой по сети базы с учётом трафика всех одновременно осуществляемых соединений.
ИС типа клиент – сервер представлена на рисунке 2.5.
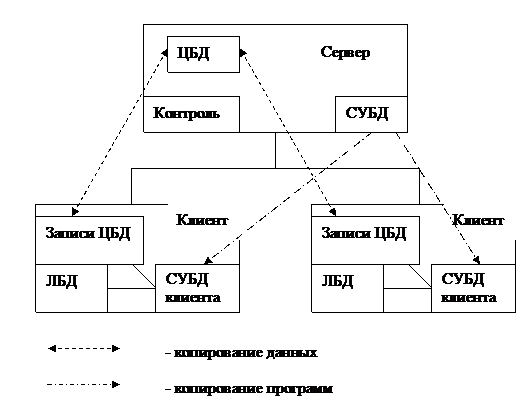
Рисунок 2.5 - Архитектура клиент – сервер
В клиент-серверной архитектуре клиент управляет пользовательским интерфейсом и логикой приложения, действуя как интеллектуальная рабочая станция, на которой выполняются приложения баз данных. Клиент принимает от пользователя запрос, проверяет его синтаксис и генерирует SQL-запрос к серверу на предоставление тех или иных данных. Сервер принимает и обрабатывает запрос, затем в зависимости от типа запроса либо передаёт полученные данные обратно клиенту, либо выполняет модификацию содержимого базы данных. Клиент принимает переданные сервером данные, форматирует их и предоставляет пользователю.
Обработка сервером запроса включает в себя проверку полномочий клиента, обеспечение требований целостности, собственно выполнение запроса и передачу клиенту необходимых результатов. При этом сервер занимается такими проблемами, как поддержка параллельной работы многих клиентов, которая включает, в первую очередь, согласование данных, одновременно предоставляемых и изменяемых различными клиентами.
Клиент-серверная архитектура обладает следующими преимуществами:
· обеспечивается более широкий доступ к существующим базам данных;
· повышается общая производительность системы. Так как клиенты и сервер находятся на разных компьютерах, их процессы способны выполнять приложения параллельно. При этом настройка производительности сервера упрощается, если на компьютере, выделенном под сервер, выполняется только работа с базой данных;
· сокращается нагрузка на компьютерную сеть. Это происходит за счёт того, что в ответ на запрос клиента сервер возвращает ему готовые результаты запроса, а не все данные, которые были использованы;
· высокие аппаратные требования предъявляются только к компьютеру, выделенному под сервер;
· появляется возможность использования специализированного аппаратного обеспечения для сервера, что повышает общую производительность системы;
· повышается уровень непротиворечивости данных, так как все проверки выполняются в одном месте, то есть на сервере.
Основное достоинство и преимущество клиент-серверных систем:
они будут работать с вполне приемлемой скоростью с базами данных такого объёма и с таким числом одновременных соединений, с которыми файл-серверная система работать не сможет, то есть её функциональность, в том числе и быстродействие, станут неприемлемыми для коммерческих приложений.
В клиент-серверных системах имеется мощный механизм работы с транзакциями. Он позволяет получить "слепок" базы данных на момент начала транзакции без блокировки базы данных. таких слепков может быть много: для каждой рабочей станции свой. В случае "зависания" рабочей станции, открывшей транзакцию, эта транзакция может быть просто откачена, а база данных будет восстановлена в том виде, в каком она была до инициации транзакции. Откат осуществляется либо по запросу рабочей станции (если она работоспособна), либо при перезагрузке рабочей станции, либо администратором клиент-серверной системы. Таким образом, выход из строя рабочей станции не столь опасен для целостности базы данных.
Кроме того, клиент-серверная система ведёт так называемый журнал транзакций. По сути база данных хранится в виде её начального содержимого и модификаций, записанных в журнал транзакций. Такой способ хранения позволяет производить архивирование базы данных во время работы всей системы практически в автоматическом режиме.
Двухзвенные модели
Файл-серверная и клиент-серверная архитектура относятся к двухзвенным моделям.
Рассмотрим основные функции СУБД, в зависимости от реализации которых определим разные варианты архитектуры ИС:
1) управление данными, находящимися в базе;
2) обработка данных с помощью прикладных программ;
3) представление информации в удобном для пользователя виде.
В двухзвенной модели эти функции распределены между двумя узлами сети: сервером и клиентом.
Возможны следующие варианты двухзвенных моделей:
1) распределенное представление;
2) удаленное представление;
3) распределенная функция;
4) удаленный доступ к данным;
5) распределенная БД.
На рисунке 2.6 показаны различия между вариантами.
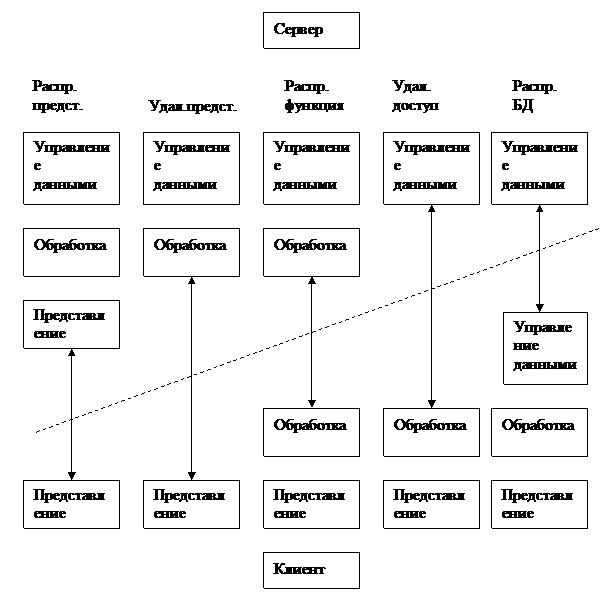
Рисунок 2.6 - Двухзвенные модели
Рассмотрим более подробно некоторые варианты.
Remote Data Access (RDA) – удаленный доступ к данным.
Обработка и представление осуществляются на компьютере-клиенте. Обращение к функциям управления осуществляется через сеть с помощью команд SQL или путем вызова функций библиотеки API.
Недостатки:
- высокая загрузка сети, когда передаются целые базы данных4
- проблемы модификации, т.к. в одном приложении реализованы функции обработки и представления.
DataBase Server (DBS) – сервер БД или удаленное представление.
Функции обработки и управления данными реализованы на сервере. Приложения имеют вид хранимых процедур, т.е. ссылки на них хранятся в словаре БД. Хранимые процедуры разделяются нескольким клиентами (см. СУБД Ingress, Sybase, Oracle и др.).
Недостатки:
- ограниченный набор средств разработки хранимых процедур;
- средства разработки привязаны к конкретной СУБД;
- низкая эффективность использования ресурсов сервера из-за сложности управления потоком запросов к программам сервера.
Трехзвенные модели
В трехзвенной модели каждая функция реализована на отдельном компьютере. Данную архитектуру иногда называют моделью сервера приложений или AS (Application Server). Простейший вариант модели приведен на рис. 2.7.
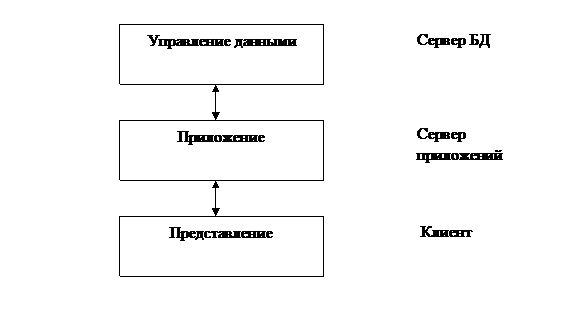
Рисунок 2.7 – Трёхзвенная модель
Между серверами каждого уровня могут быть достаточно сложные схемы взаимодействия, например, когда один объект является одновременно и сервером и клиентом для другого сервера.
Монитор транзакций
В сложных моделях, например, AS, требуется рационально организовать выполнение транзакций.
Под транзакцией будем понимать действия над данными в БД, передачу сообщений, запись информации в файл, опрос датчиков и т.д.
На рисунке 2.8 представлена модель обработки транзакций X/Open DTP (Distributed Transaction Processing) – обработка распределенных транзакций.
В качестве прикладной программы рассматривается любая программа.
Под ресурсом понимается ресурс любого вида. Если ресурсом является БД, то менеджер ресурса – это сервер БД.
Интерфейс ATMI (Application Transaction Monitor Interface – прикладной интерфейс монитора транзакций) используется для вызова функций TPM (Transaction Processing Monitor) на некотором языке программирования, например, на С.
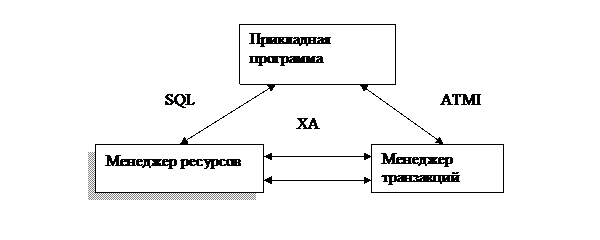
Рисунок 2.8 – Монитор транзакций
Связь между менеджерами ресурсов и транзакций осуществляется на основании протокола двухфазной фиксации транзакций (стандарт X/Open XA) (Oracle, Ingres, Informix).
Полезно знать следующее: транзакции, поддерживающие TPM, часто называются прикладными или бизнес-транзакциями.
Использование монитора транзакций имеет ряд достоинств по сравнению с другими технологиями:
- повышается пропускная способность сети;
- облегчается администрирование;
- ускоряется разработка приложений.
На рынке предлагается ряд мониторов транзакций, например, ACSM, CICS, TUXEDO System и др.
ИС в Internet и intranet
Рассмотрим модели доступа к Internet.
Модель доступа со стороны сервера (рисунок 2.9).

Рисунок 2.9 – Модель доступа со стороны сервера
Web – сервер вызывает внешние по отношению к программам Web – сервера программы в соответствии с одним из интерфейсов:
· CGI (Common Gateway Interface – общий шлюзовой интерфейс);
· Fast CGI;
· API (Application Program Interface).
Внешние программы взаимодействуют с сервером БД на языке SQL, непосредственно обращаясь к серверу или через ODBC (Open Database Connectivity - совместимость открытых баз данных – прикладной интерфейс для связи с базами данных).
Внешние программы могут быть написаны на разных языках, но, при этом, если они написаны в соответствии с интерфейсом CGI, то они называются CGI – сценариями или CGI – скриптами. При использовании этого интерфейса у клиента появляется возможность, например, на языке HTML включать в документ форму запроса к базе данных.
Модель доступа на стороне клиента (рисунок 2.10).
Модель доступа в Internet со стороны клиента
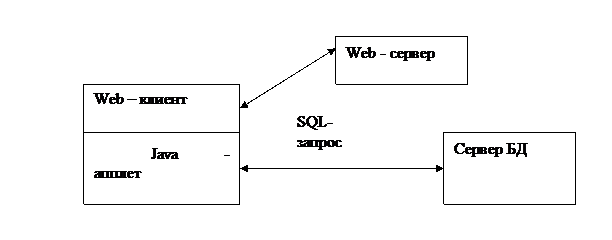
Рисунок 2.10 - Модель доступа в Internet со стороны клиента
Рассмотрим возможный вариант реализации такой модели.
Пусть в HTML – документе требуется получить данные из базы. Для этого:
1) на языке Java пишутся программы, называемые апплетами, которые затем компилируются;
2) в тексте HTML – документа в нужных местах ставятся ссылки на соответствующие апплеты; программы хранятся на сервере;
3) при обнаружении ссылки апплет автоматически пересылается с сервера в среду выполнения броузера и выполняется там, в том числе, запрашивая недостающую информацию у пользователя;
4) Java – апплет взаимодействует с сервером БД и полученную информацию предоставляет пользователю.
Основные понятия
Концептуальный уровень проектирования – выявление и описание взаимосвязей между элементами данных, вытекающее из взаимосвязей в реальном мире предметной области.
Сущности – личности, факты, объекты реального мира, имеющие отношение к некоторой проблемной области.
Атрибуты – данные, описывающие сущности.
Связи – взаимодействия между несколькими сущностями; связь может иметь атрибуты.
Концептуальная модель – модель данных концептуального уровня.
Концептуальная схема – графическое представление концептуальной модели.
Задачи моделирования данных
Цель построения модели: документирование требований к данным со стороны бизнес – процессов.
Назначение модели: основа для создания физической базы данных.
Преимущества правильно спроектированной базы:
1) минимальная избыточность данных;
2) максимальная целостность данных;
3) стабильность структуры БД;
4) эффективное совместное использование данных;
5) своевременность доступа к данным;
6) удобство и простота использования данных;
7) возможность разработки новых приложений без изменения структуры данных и др.
Альтернативный подход к проектированию базы данных можно назвать чисто "программистским", когда начинающий проектировщик базы данных быстро и приближенно проектирует базу под конкретную задачу аналогично разработке программ для работы с двумерными файлами. Однако, большинство разработчиков, использующих этот подход, быстро сталкивается с проблемами на этапе эксплуатации базы данных, в том числе: низкая производительность и нарушения целостности базы данных.
Можно утверждать, что правильный проект базы данных не может быть быстро составлен новичками. От проектировщика требуется знание формализованных подходов к сбору требований к данным, обнаружению и идентификации логических объектов и элементов данных. Приобретение мастерства и изучение всех нюансов может занять много времени.
Сущности
Сущность – это человек, место, предмет, понятие или событие, то есть то, что существует и что можно описать. Например: Студент, Преподаватель, Дисциплина, Заказчик, Товар и т.д.
Как выявить сущности?
Информация о сущностях используется в описании бизнес – процессов организации и представлена, как правило, именами существительными. Например: "обучение студентов", "продажа товаров" и т.п.
С чего начать?
С изучения основных видов деятельности в моделируемой проблемной области и способов их осуществления.
После выявления сущностей необходимо четко определить их название.
Требования к имени сущности: имена должны быть стандартными, хорошо определенными и постоянными.
Правило задания имени сущности: имя сущности должно быть существительным в единственном числе, допускается сочетание с прилагательным. Желательно записывать имя заглавными буквами, например, СТУДЕНТ.
Проблема выбора имени: наличие синонимов, используемых разными категориями пользователей, например, СТУДЕНТ, УЧАЩИЙСЯ, ОБУЧАЕМЫЙ.
Решение проблемы: выбрать наиболее популярное название или принять волевое решение по этому поводу. Выбранное название должно быть единственным в базе данных.
При проектировании базы данных необходимо различать понятия "Сущность" и "Экземпляр сущности". Так, сущность СТУДЕНТ – это абстрактное понятие, а Иванов – это экземпляр сущности СТУДЕНТ.
Атрибуты
Атрибут – это характеристика или свойство сущности.
Можно выделить следующие разновидности атрибутов:
1) идентифицирующие, то есть те, которые позволяют отличить один экземпляр сущности от другого, например, № студенческого билета; такие атрибуты являются потенциальными ключами сущности и должны быть неизменными;
2) связывающие, то есть те, которые позволяют создать связи между сущностями;
3) описывающие, то есть те, которые не относятся к первым двум разновидностям, например, Дата рождения.
Не существует точного правила, позволяющего отличить атрибут от сущности и наоборот.
Можно использовать следующие рекомендации:
1) на основании знания бизнес – процессов выявить роли атрибутов (идентификация, связывание, описание);
2) экземпляры атрибутов, как правило, элементарны по своей природе, то есть атрибут представляет собой единичный факт, который в бизнес – процессах не раскладывается на составные части; например, ФИО как атрибут сущности СТУДЕНТ является не лучшим решением, т.к. раскладывается на составные части, которые в бизнес – процессах могут рассматриваются отдельно, например, поздравление всех Татьян с Татьяниным днем.
Соглашения для имен атрибутов могут быть разными в разных организациях, например, ИмяСтудента или имя_студента и т.п.
Существуют общепринятые сокращения для имен атрибутов, например, ID - идентификатор или ADDR – адрес и т.д.
При задании имен атрибутам необходимо избегать использования омонимов (ключ, замок и т.п.) и синонимов.
После уточнения имен атрибутов необходимо определить множество допустимых значений каждого атрибута, используя для этих целей любые известные способы:
- указание типа данных;
- тип данных и диапазон;
- использование классификаторов и кодификаторов;
- список допустимых значений и т.д.
Для каждого атрибутанеобходимо оценить возможность принимать неизвестное значение (NULL - значение). Например, сущность СТУДЕНТ, атрибут ЦветВолос. Как задать значение этого атрибута для студентки с неизвестным цветом волос или для лысого студента?
Ключи
Ключ состоит из одного или более атрибутов, значения которых однозначно идентифицируют экземпляр сущности, например, №Паспорта – ключ личности, по нему один экземпляр сущности ЛИЧНОСТЬ отличается от другого экземпляра.
Каждая сущность может иметь несколько ключей, но должна иметь по крайней мере один ключ. Такие ключи называются потенциальными ключами.
У каждой сущности есть один и только один первичный ключ, который выбирается из потенциальных ключей.
Критерии выбора первичного ключа:
- ключ должен гарантировать уникальность каждого экземпляра сущности;
- атрибуты, входящие в первичный ключ, не могут принимать NULL – значения;
- ключ должен быть неизменным, то есть неспособным и невосприимчивым к изменениям;
- значения первичных ключей должны задаваться внутри организации и не должны зависеть от внешних структур.
Например, сущность СЛУЖАЩИЙ. Атрибут №Паспорта является плохим кандидатом на роль первичного ключа, так как его значение зависит от внешних организаций и может быть изменено ими. Его значения находятся вне зоны внутреннего контроля. Лучшим решением является ТабельныйНомер, т.к. его значение присваивается внутри организации.
Связи
Связи моделируют отношения сущностей, возникающие в результате взаимодействия сущностей в ходе реализации бизнес – процессов.
Типы связей:
1) унарные или рекурсивные – это связи между экземплярами одной и той же сущности, например, связь "подчиняться" моделирующая отношение "руководитель - подчиненный" на экземплярах сущности РАБОТАЮЩИЙ;
2) бинарные – это связи между двумя сущностями, например, связь "изучает" между сущностями СТУДЕНТ и ДИСЦИПЛИНА;
3) n – арные – это связи между более, чем двумя, сущностями, например, связь "обучает" между сущностями СТУДЕНТ, ПРЕПОДАВАТЕЛЬ и ДИСЦИПЛИНА.
Унарные и бинарные связи характеризуются мощностью и обязательностью. Характеристики задаются на каждом конце связи.
Мощность – это количество экземпляров сущности участвующих в каждом конкретном экземпляре связи.
В зависимости от мощности различают следующие виды связей:
1) " один – к - одному ", например, связь "имеет" между сущностями СТУДЕНТ и МЕДИЦИНСКАЯ_КАРТА при условии, что учитываются только карты в конкретной поликлинике;
2) " один – ко многим ", например, связь "состоит из" между сущностями СТУДЕНТ и ГРУППА при условии, что в базе будет храниться информация только об одной группе, в которой обучается студент;
3) "многие – ко многим", например, связь "изучает" между сущностями СТУДЕНТ и ДИСЦИПЛИНА.
Обязательность – определяет обязательность наличия связи для каждого экземпляра сущности. Если существуют экземпляры сущности, для которых связь не задается, то для данной сущности связь является частичной. В противном случае, связь называется обязательной или всюду определенной. Например, связь "состоит из" для сущности ГРУППА является обязательной, т.к. группа состоит хотя бы из одного студента и для каждой конкретной группы такая связь существует. Для сущности СТУДЕНТ данная связь является частичной, т.к. существуют студенты, которые находятся в академическом отпуске и не могут быть приписаны к какой – либо группе.
Для связей также существуют соглашения по присваиванию имен.
Имя связи обычно задается глаголом. Для связи "многие – ко - многим" рекомендуется указывать два имени, например, СТУДЕНТ "изучает" ДИСЦИПЛИНУ и ДИСЦИПЛИНА "изучается" СТУДЕНТОМ, то есть связь именуется "изучает / изучается".
Классы и подклассы
Сущности проблемной области могут образовывать иерархии, построенные на основании отношений "класс - подкласс". Сущности, входящие в иерархию, связаны между собой отношением "один – ко - многим", при этом первичный ключ сущности – подкласс






