Структура управляющей информации, версия 2 (SMIv2) — компонент для управления сетью. Его функции:
1. Присвоить имена объектам.
2. Определить тип данных, которые могут быть сохранены в объекте.
3. Показывать, как кодировать данные для передачи по сети.
SMI выделяет три атрибута для того, чтобы обрабатывать объект: имя, тип данных и метод кодирования. (Рис 5.2.).

Рис. 5.2. Атрибуты объектов
Имя
SMI требует, чтобы каждый управляемый объект (такой как маршрутизатор, переменная в маршрутизаторе, значение и т. п.) имел уникальное имя. Чтобы присвоить глобальное имя объекту, SMI использует идентификатор объекта, который является иерархическим и основан на структуре дерева (Рис 5.3.).

Рис. 5.3. Идентификация объекта
Структура дерева начинается с корня, не имеющего имени. Каждый объект может быть определен, используя последовательность целых чисел, разделенных точками. Структура дерева может также определить объект с использованием текстуальных имен, отделенных точками. Представление в целых числах с точками применяется в SNMP. Обозначение имя-точка принято людьми. Например, ниже показаны одни и те же объекты в двух нотациях:
Объекты, которые используются в SNMP, расположены в адресе после объекта mib-2, поэтому их идентификатор всегда начинается с 1.3.6.1.2.1.
Тип
Второй атрибут объекта — тип сохраняемых в нем данных. Определяя тип данных, SMI пользуется фундаментальными ASN.1-определениями и дополняет некоторые их новыми определениями. Другими словами, SMI — и поднабор, и супернабор ASN.1.
SMI использует две широких категории типа данных: простые и структурированные. Мы сначала определим простые типы, а затем покажем, как структурированные типы могут быть построены из одних простых (Рис 5.4.).

Рис. 5.4. Тип данных
Простой тип
Простой тип – это частичка типа данных, некоторые из них прямо поступают в ASN.1, некоторые дополняются SMI. Большинство важных единиц даны в таблице 5.1. Первые 5 — из ASN.1; следующие семь определены SMI.
| Тип
| Размер
| Описание
|
| INTEGER
| 4 байта
| Целое со значением между 0 и 231-1
|
| Integer 32
| 4 байта
| То же самое, что и INTEGER
|
| Unsigned32
| 4 байта
| Значения без знака между 0 и 231
|
| OCTET STRING
| Переменный
| Строка байтов не более 65 535 байтов длины
|
| OBJECT IDENTIFIER
| Переменный
| Идентификатор объекта
|
| IPAdress
| 4 байта
| IP-адрес, состоящий из четырех байтов
|
| Counter32
| 4 байта
| Целое, значение которого может быть увеличено от 0 до 232; когда оно достигает максимального значения, оно свертывается назад в нуль
|
| Counter64
| 8 байтов
| 64-битовый счетчик
|
| Gauge32
| 4 байта
| Тот же самый 32-битовый счетчик (counter32), но он достигает максимального значения и не сворачивается в ноль; он остается там, пока не сбрасывается
|
| TimeTics
| 4 байта
| Считает значение, в котором записано время в 1/100 секунды
|
| BITS
|
| Строка бит
|
| Opaque
| Переменный
| Неинтерпретируемая строка
|
Структурированный тип
Комбинируя простой и структурированный типы данных, мы можем создать новые структурированные типы данных. SMI определяет два вида структурированных типов данных: sequence (последовательности) и sequence of (последовательности из).
Sequence (последовательность). Тип данных sequence (последовательности) – это комбинация простых типов данных, не обязательно одного типа. Это аналог понятий struct (структура) или record (комбинированный), используемых в языках программирования, таких как C.
Sequence of (последовательность из). Тип данных sequence of (последовательность из) — комбинация из простых типов данных одного типа или комбинации последовательного типа данных одного типа. Это аналог понятия массив, используемого в языках программирования, таких как C.
Рисунок 5.5. показывает концептуальный обзор типов данных.

Рис. 5.5. Концептуальные типы данных
Метод кодирования
SMI использует другой стандарт, основные правила кодирования (BER — Basic Encoding Rules), чтобы кодировать данные, которые будут переданы по сети. BER определяет, что каждая часть данных кодируется в формате тройки: тег, длина и значение, как проиллюстрировано на рисунке 5.6.

Рис. 5.6. Формат длины
Тег. Тег – однобайтовое поле, которое определяет тип данных. Оно составлено из трех подполей: класс (2 бита), формат (1 бит), и номер (5 битов). Подполе класса определяет область действия данных. Определены четыре класса: универсальный (00), прикладной (01), контекстно-определенный (10) и частный (11). Универсальные типы данных взяты из ASN.1 (INTEGER, OCTET STRING и ObjectIdentifeir). Прикладные типы данных — те, которые добавлены SMI (IPAddress, Counter, Gauge и TimeTicks). Пять контекстно-определенных типов данных имеют значения, которые могут измениться от одного протокола к другому. Частные типы данных определяются поставщиком.
Подполе "Формат" указывает, являются ли данные простыми (0) или структурированными (1). Далее подполе "номера" делит простые или структурированные данные на подгруппы. Например, в универсальном классе, с простым форматом, INETGER имеет значение 2, OCTET STRING имеет значение 4, и так далее. Таблица 5.2. показывает типы данных, которые мы используем в этой лекции, и их теги в двоичных и шестнадцатеричных числах.
| Тип данных
| Класс
| Формат
| Номер
| Тег (двоичный)
| Тег (шестнад.)
|
| INTEGER (Целый)
|
|
|
|
|
|
| OCTET STRING (октет последовательностей)
|
|
|
|
|
|
| OBJECT IDENTIFIER (ИДЕНТИФИКАТОР ОБЪЕКТА)
|
|
|
|
|
|
| NULL (ПУСТОЙ УКАЗАТЕЛЬ)
|
|
|
|
|
|
| Последовательность, последовательность из
|
|
|
|
|
|
| IPAddress (IP-адрес)
|
|
|
|
|
|
| Counter (Счетчик)
|
|
|
|
|
|
| Gauge (Шаблон)
|
|
|
|
|
|
| TimeTicks (Сигналы времени)
|
|
|
|
|
|
Длина. Поле длины – один или более байт. Если поле длины один байт, старший знаковый бит должен быть равен нулю. Другие 7 бит определяют данные. Если поле длины больше чем 1 байт, старший знаковый первого байта должен быть равным единице. Другие 7 бит первого байта определяет число байт, нужных для определения длины. Формат отображения поля длины (Рис 5.7.):

Рис. 5.7. Формат длины
Значение. Поле кодирует значение данных в соответствии с правилами, определенными в правилах кодирования (например, ANSI).
Для того чтобы показать, как эти три поля — тег, длина и значение – могут определить объект, мы приведем несколько примеров.
Пример 1
Рисунок 5.8. показывает, как определяется INTEGER 14:

Рис. 5.8. Пример 1 INTEGER 14
Пример 2
Рисунок 5.9. показывает, как определяется OCTET STRING "H1":

Рис. 5.9. Пример 2 OCTET STRING "H1"
Пример 3
Рисунок 5.10. показывает, как определяется OBJECT Identifier 1.3.6.1 (iso.dod.internet):

Рис. 5.10. Пример 3 ObjectIdentifier 1.3.6.1
Пример 4
Рисунок 5.11. показывает, как определить IPAddress 131.21.14.8:
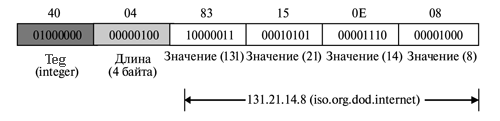
Рис. 5.11. Пример 4 IPAdress 131.21.14.8
trans и snmp. Эти группы в адресе находятся после обозначения объекта MIB2 в дереве объектов идентификации (Рисунок 5.12.).

Рис. 5.12. MIB-2






