Анализ речевых сигналов во временной области
При решении многих задач обработки речи интерес представляют временные характеристики речевых сигналов. Поскольку речь является нестационарным процессом, то ее принято анализировать на коротких участках (10 - 30 мс), где спектрально-корреляционные характеристики остаются примерно постоянными [14].
Одним из важных параметров речевого сигнала является его энергия

Энергия может служить хорошей мерой отличия вокализованных и невокализованных участков речи. Энергия невокализованных участков речи намного меньше, чем вокализованных.
Иной способ обнаружения вокализованных и невокализованных участков речи основан на измерении среднего числа переходов через ноль речевого сигнала. Это измерение является грубой оценкой частотного состава речевого сигнала. Известно, что энергия вокализованных звуков концентрируется в диапазоне ниже 3 кГц, тогда как энергия фрикативных звуков сосредоточена, в основном, на частотах выше 3 кГц. Поэтому, если среднее число переходов через ноль велико, то это свидетельствует о невокализованном характере речи, и наоборот.
Важной задачей анализа речевых сигналов во временной области является оценивание периода основного тона. Период основного тона может быть определен как временной интервал между соответствующими пиками вокализованного участка речевого сигнала. Однако главная трудность здесь состоит в том, что даже на коротких интервалах времени речевой сигнал не имеет строгой периодической структуры.
Иной способ определения периода основного тона во временной области основан на вычислении функции кратковременной автокорреляции 
где My - максимальная задержка сигнала. |
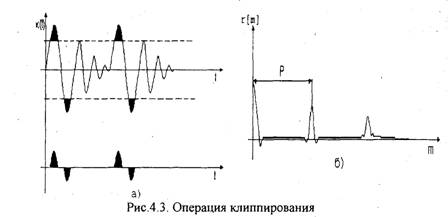
При выявлении периода основного тона Р по автокорреляционной j функции необходимо учитывать условие Му>Р. Для вокализованных | участков речи на графике г[т] прослеживаются пики с интервалом, равным | периоду основного тона. !'{
С целью обострения пиков на графике г[т] сигнал х[п] клиппируют [17]. Суть этой нелинейной операции показана на рис.4.3,а. На рис.4.3,6 1 представлена автокорреляционная функция клиппированного сигнала.
Недостатком рассматриваемого метода определения периода основного | тона является то, что для вычисления автокорреляционной функции ';
требуется выполнить большое число арифметических операций.
Гомоморфная обработка речи
В соответствии с рис.4.1 речевой сигнал является сверткой функции возбуждения (случайного шума либо квазипериодической последовательности импульсов) и импульсной характеристики голосового тракта. Гомоморфный анализ речи позволяет разделить эти компоненты. Поэтому, используя гомоморфный анализ, можно определить период основного тона и частотные свойства голосового тракта. Общая схема гомоморфной обработки приведена на рис.4.7.

В соответствии с этой схемой сначала выполняется нелинейное преобразование Д{ } сигналах, которое определяется соотношением


X(z}=X^z)-Xi(z). (4.16)
Подставив (4.16) в (4.15), получим

Линейная инвариантная система пропускает на выход только одну из компонент X\(z) или X:(z). Соответственно обратное преобразование Д"'{ } дает ^["]=-ci[/!] или ^[и]=-Т2[я]. Следовательно, гомоморфная обработка разделяет входные компоненты х\[п} и хг[п], содержащиеся во входном сигнале.

Гомоморфная система анализа речи показана на рис.4.8. Здесь на первом этапе вычисляется логарифм модуля кратковременного преобразования Фурье. Если предположить, что сигнал в точке А является сверткой функции возбуждения и импульсной характеристики голосового тракта, то в точке С мы получим сумму логарифмов спектра функций возбуждения и импульсной характеристики голосового тракта. Сигнал в точке D, полученный с помощью обратного дискретного преобразования Фурье, называется кепстром. Кепстр в точке D равен сумме кепстров функции возбуждения и импульсной характеристики голосового тракта. Покажем это.
В общем случае, комплексный кепстр сигнала х[п] определяется как обратное преобразование Фурье от логарифма комплексного спектра Х(ш).
Для модуля кратковременного спектра |^('У)|, который является четной и периодической функцией, можно использовать разложение в ряд Фурье

где с[п] - кепстральные коэффициенты и

Если речевой сигнал является сверткой функции возбуждения и[п] и импульсной характеристики h[n] голосового тракта

то модуль спектра |^(<у)| равен произведению модулей \U(a)}\ и \Н(а>)\:

Взяв логарифм от обеих частей (4.21), получим

Так как обратное преобразование Фурье является линейной операцией, то из(4.22) следует, что

где с„[и) и Сн[п] - кепстры последовательностей и[п\ и h[n].
В схеме обработке речи, изображенной на рис.4.8, вместо дискретно-непрерывного преобразования Фурье по непрерывной перемененной q) используется дискретное преобразование Фурье, определяемое на фиксированных частотах. Рис.4.9 иллюстрирует указанные преобразования для вокализованной речи.

Пульсирующая кривая С (рис.4.9) соответствует логарифму модуля кратковременного спектра. Она содержит медленно меняющуюся составляющую, соответствующую амплитудно-частотной характеристике голосового тракта, и быстро меняющуюся составляющую, обусловленную периодической функцией возбуждения. Выполнив ОДПФ логарифма спектра, получим кепстр, который является функцией времени. Медленно меняющаяся составляющая спектра соответствует области малых времен кепстра, а быстро меняющаяся периодическая составляющая спектра соответствует удаленному пику в кепстре (рис.4.9), возникающему через интервал времени, равный периоду основного тона. Для невокализованной речи указанный пик будет отсутствовать. Поэтому кепстр может использоваться для определения периода основного тона и характера речи (вокализованная или невокализованная).
Амплитудно-частотная характеристика голосового тракта получается низкочастотной фильтрацией сигнала, действующего в точке С (рис.4.8). В результате этого будут подавлены быстро меняющиеся элементы на кривой С (рис. 4.9). Фильтрация может быть выполнена по методу быстрой свертки. Для этого вычисляется ОДПФ сигнала С, полученный кепстр умножается на подходящую функцию окна, пропускающую лишь область;i малых времен кепстра, и затем выполняется ДПФ. В результате такой обработки получим сглаженный спектр (рис. 4.9, кривая Е). Резонансные пики на кривой Е позволяют определить формантные частоты. Используя оценки формантных частот голосового тракта и период основного тона, можно синтезировать речь на основе модели, изображенной на рис.4.1.
Сжатие речевых сигналов
Наиболее важными областями применения рассмотренных способов обработки речевых сигналов являются системы низкоскоростной передачи речи и компьютерные мультимедийные системы. Непосредственное кодирование речи по методу ИКМ требует значительных объемов памяти для хранения речевых сигналов. Поэтому при обработке речи в компьютерных системах не обойтись без сжатия речевых сигналов.
Многие методы сжатия речевых сигналов основаны на линейном предсказании речи. В частности, линейное предсказание используется при сжатии речи по методу АДИКМ. Стандарт G.726, определяющий алгоритмы АДИКМ, устанавливает для данного типа сжатия речевых сигналов нижнюю скорость передачи 16 Кбит/с.
Дальнейшее снижение скорости передачи возможно при использовании схем анализ-синтез речи, учитывающих особенности цифровой модели формирования речи (рис.4.1). Применяют два варианта таких схем - без обратной связи и с обратной связью [36].
На рис.4.13,а приведена схема сжатия речи без обратной связи, основанная на анализе по методу линейного предсказания и синтезе речевого сигнала в соответствии с моделью, представленной на рис.4.1. Здесь речевой сигнал s[n] разбивается на сегменты длительностью 20-30 мс. На каждом из сегментов с помощью устройства оценивания (УО) определяются коэффициенты линейного инверсного фильтра-анализа Ф1 10-го порядка. Кроме этого, на этапе сжатия с помощью выделителя основного тона (ВОТ) и анализатора тон-шум (Т-Ш) определяются соответствующие параметры функции возбуждения. В кодере выполняется кодирование коэффициентов фильтра и параметров функции возбуждения, которые затем передаются по каналу связи или сохраняются в памяти.
В восстанавливающем устройстве (рис.4.13,б) сначала происходит декодирование коэффициентов фильтра и параметров функции возбуждения, а затем выполняется синтез речевого сигнала s[n} в соответствии с моделью, изображенной на рис. 4.1. Для этого в зависимости от значения признака тон-шум (ТШ) на вход фильтра-синтеза Ф2 подается сигнал либо с выхода генератора тона (ГТ), либо с выхода генератора шума (ГШ). В технике связи устройство, выполняющее сжатие и восстановление речевых сигналов по приведенной схеме, называют вокодером. Для кодирования периода основного тона используют 6 бит, для коэффициента усиления - 5 бит, для признака тон/шум - 1 бит, для коэффициента усиления - 5 бит, для коэффициентов линейного предсказания - 8-10 бит. С учетом того, что для каждого сегмента речи оценивается десять коэффициентов предсказания, получим 97-117 бит на один сегмент. Скорость передачи при длительности сегмента 30 мс составит примерно 3000 бит/с.
В схеме, изображенной на рис. 4.13,6, параметры возбуждения (частота основного тона, признак тон/шум, форма сигнала возбуждения) формируются без учета их влияния на качество синтезированной речи. Поэтому восстановленная речь воспринимается как механическая и не обеспечивает узнаваемости голоса. 
Для повышения натуральности речи используется схема анализа-синтеза с обратной связью (рис.4.14). В этой схеме возбуждающая последовательность формируется путем минимизации ошибки восстановления речевого сигнала, т.е. разности между исходным речевым сигналом s[n] и восстановленным сигналом s[n]. Восстановленный речевой сигнал формируется с помощью фильтров Ф1 и Ф2, на вход которых подается сигнал с выхода генератора функции возбуждения (ФВ). Фильтр Ф1 учитывает квазипериодические свойства вокализованных участков речи, а фильтр Ф2 моделирует формантную структуру речи. Инверсный фильтр, соответствующий фильтру Ф1, является фильтром долговременного предсказания, а инверсный фильтр, соответствующий фильтру Ф2, называется фильтром кратковременного предсказания.Фильтр долговременного предсказания описывается передаточной функцией
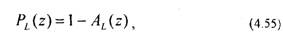
где A^(z)=az r и Г - задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания (/л-М, то в соответствии с (4.55) ошибка долговременного предсказания d;[п] будет равна


Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности s[n} ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рис. 4.14) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой (см. §4.8). Фильтр W(z), учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рис.4.14, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
Существует несколько различных способов формирования функции возбуждения: многоимпульсное, регулярно-импульсное и векторное (кодовое) возбуждение [36]. Соответствующие алгоритмы представляют многоимпульсное (MLPC), регулярно-импульсное (RPE-LPC) и линейное предсказание с кодовым возбуждением (code excited linear prediction - CELP). MLPC использует функцию возбуждения, состоящую из множества нерегулярных импульсов, положение и амплитуда которых выбирается так, чтобы минимизировать ошибку восстановления. Алгоритм RPE-LPC является разновидностью MLPC, когда импульсы имеют регулярную расстановку. В этом случае оптимизируется амплитуда и относительное положение всей последовательности импульсов в пределах сегмента речи. CELP представляет способ, который основывается на векторном квантовании. В соответствии с этим способом из кодовой книги возбуждающих последовательностей выбирается квазислучайный вектор, который минимизирует квадрат ошибки восстановления. Кодовая книга используется как на этапе сжатия речевого сигнала, так и на этапе его восстановления. Для восстановления сегмента речевого сигнала необходимо знать номер соответствующего вектора воз-бужденияг в кодовой книге, параметры фильтров Ai,(z) и A(z), коэффициент усиления. Восстановление речевого сигнала по указанным параметрам выполняется в декодере только с помощью элементов, входящих в верхнюю часть схемы, изображенной на рис.4.14.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
2) CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефонной связи;
3) VCELP со скоростью передачи 7,95 Кбит/с (vector sum excited linear prediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
4) LD-CELP (low-delay CELP) одобрен стандартом МККТТ G.728. В данном стандарте достигается небольшая задержка примерно 0,625 мс (обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией Ai,(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP),
Сжатие аудиосигналов
Основные свойства речевых сигналов
Голосовой аппарат человека представляет собой акустическую систему, состоящую из ротового и носового каналов, возбуждаемую квазипериодическими импульсными колебаниями голосовых связок и турбулентным шумом. Турбулентный шум образуется путем проталкивания воздуха через сужения в определенных областях голосового тракта. Голосовой аппарат, возбуждаемый указанными источниками, действует как линейный фильтр с изменяющимися во времени параметрами, на выходе которого формируется речевой сигнал. На коротких интервалах времени речевой сигнал можно аппроксимировать сверткой возбуждающего сигнала с импульсной характеристикой голосового тракта. На рис.4.1 изображена упрощенная модель формирования речевого сигнала [15;17]. В соответствии с этой моделью вокализованны е (звонкие) звуки формируются с помощью генератора импульсной последовательности, а фрикативны е (шумовые) - с помощью генератора случайных чисел.

Период следования импульсов на выходе генератора импульсной последовательности соответствует основному периоду возбуждения голосовыми связками. Генератор случайных чисел формирует шумовой сигнал с равномерной спектральной плотностью. Цифровой фильтр (ЦФ) с переменными параметрами аппроксимирует передаточные свойства голосового тракта. На временном интервале порядка 5-20 мс форма голосового тракта не меняется, поэтому характеристики ЦФ на данном g интервале остаются постоянными. Амплитуда входного сигнала u[n] | цифрового фильтра определяется коэффициентом усиления G.
Вокализованные звуки представляют собой квазипериодические сигналы (рис. 4.5,а), гармоническая структура которых хорошо видна на графике кратковременного спектра. Фрикативные звуки имеют случайный характер (рис. 4.5,6) и занимают более широкий частотный диапазон. Энергия вокализованных звуков речи намного больше, чем энергия фрикативных звуков. Структура кратковременного спектра вокализованных участков речи (рис. 4.5,а) характеризуется наличием медленно меняющейся и быстро меняющейся составляющих. Быстро меняющаяся или пульсирующая составляющая обусловлена квазипериодическими :колебаниями голосовых связок. Медленно меняющаяся составляющая ' связана с собственными (резонансными) частотами голосового тракта - формантами. В среднем насчитывается 3-5 формант. Первые три форманты оказывают существенное влияние на синтез и восприятие вокализованных участков речи. Их частоты находятся ниже 3 кГц. Форманты с более высокими частотами оказывают влияние на синтез и представление фрикативных звуков.
Рассмотренная цифровая модель формирования речевого сигнала характеризуется следующими параметрами: наличием классификатора вокализованных и невокализованных звуков (переключатель тон/шум), периодом основного тона, коэффициентом усиления G, параметрами (коэффициентами) ЦФ.
На рассмотренной модели базируются многочисленные способы представления речевых сигналов: от простейшей периодической дискретизации речевого сигнала до оценок параметров модели, представленной на рис.4.1. Выбор того или иного способа представления речевого сигнала определяется решаемой задачей, которые разделяются на три класса. К первому классу относят задачи, связанные с анализом речи. Анализ речи является неотъемлемой частью систем распознавания речевых сигналов, а также систем идентификации дикторов по голосу. Ко второму классу относят задачи, связанные с синтезом речи по тексту. Задачи такого типа возникают в многочисленных информационно-справочных системах. В задачах, относящихся к третьему классу, выполняется как анализ системы сжатия речевых сигналов с целью передачи речи по компьютерным сетям или по традиционным линиям связи. Одним из перспективных направлений применения обработки речевых сигналов являются системы распознавания речи в сети Internet. В этом случае пользователь сети, используя телефон, может соединиться с программой распознавания речи, находящейся на сервере и транслирующей диалог в команды Web-сервера. Это позволяет получить доступ к распределенным информационным ресурсам сети по телефону. Данная технология, использующая методы цифровой обработки сигналов, базируется на использовании специального языка программирования Web-серверов VoxML (Voice Markup Language).
В дальнейшем рассмотрим основные способы цифрового представления и обработки речевых сигналов, применяемые как в задачах анализа речевых сигналов, так и в задачах синтеза.






