

Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...

История развития пистолетов-пулеметов: Предпосылкой для возникновения пистолетов-пулеметов послужила давняя тенденция тяготения винтовок...
Кормораздатчик мобильный электрифицированный: схема и процесс работы устройства...
История развития пистолетов-пулеметов: Предпосылкой для возникновения пистолетов-пулеметов послужила давняя тенденция тяготения винтовок...
Топ:
Определение места расположения распределительного центра: Фирма реализует продукцию на рынках сбыта и имеет постоянных поставщиков в разных регионах. Увеличение объема продаж...
Характеристика АТП и сварочно-жестяницкого участка: Транспорт в настоящее время является одной из важнейших отраслей народного хозяйства...
Интересное:
Аура как энергетическое поле: многослойную ауру человека можно представить себе подобным...
Уполаживание и террасирование склонов: Если глубина оврага более 5 м необходимо устройство берм. Варианты использования оврагов для градостроительных целей...
Что нужно делать при лейкемии: Прежде всего, необходимо выяснить, не страдаете ли вы каким-либо душевным недугом...
Дисциплины:
|
из
5.00
|
Заказать работу |
|
|
|
|
Лабораторная работа № 3
Основные характеристики случайной выборки
(подсчет в Excel)
Если набор данных содержит информацию о каждом элементе группы или обо всех возможных измерениях, говорят, что такой набор данных представляет генеральную совокупность. Если измерения проводятся на некотором подмножестве генеральной совокупности или выполняется лишь часть всех возможных измерений, такой набор данных называется выборкой. Метод, когда для описания свойств генеральной совокупности используется выборка, называется методом выборочного обследования. При этом методе используют представительную выборку. Обычно в ее качестве применяется случайная выборка. Для характеристики выборки подсчитывают статистические характеристики
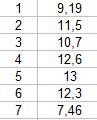
Экспериментально получены измерения некоторой величины

Задание № 1
В Excel создадим компьютерную модель решения задачи.
Компьютерная модель = ячейки данных + ячейки вычислений + ячейки результатов
Алгоритм создания компьютерной модели решения задачи
1. Выбрать на листе Excel ячейки и ввести в них данные с пояснениями
2. Последовательно решать задачу: выполнять действия, расчеты и вносить комментарии к ячейкам, в которых производились расчеты
3. Выделить ячейки с результатами (цветом, шрифтом и др.) и написать вывод


Рис. Способы размещения компьютерной модели на листе Excel
Подсчитать основные статистические характеристики данной выборки с использованием формул (программирование формул в Excel) для подсчета статистических характеристик (см. ниже).
Рассмотрим на примере подсчета средней арифметической ряда
| Действия | Пояснения и визуализация действий |
| 1. Введем исходные данные в столбец | 
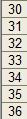 
|
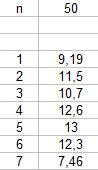
| 2. С помощью строки состояния подсчитать количество введенных значений и в две соседние ячейки ввести n и количество значений (число) |
|
3.Выделить столбец исходных данных на одну ячейку больше и нажать клавишу 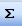 . Получим в пустой ячейке сумму выделенного ряда., т.е. . Получим в пустой ячейке сумму выделенного ряда., т.е. 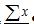
| |
| 4. Это значение надо разделить на n, т.е. на значение 50. Для этого в ячейку под ячейкой с суммой ряда ввести формулу: =ячейка с суммой/ ячейка, где находится 50 (указать адреса соответствующих ячеек) | 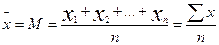 Получим значение средней арифметической
Получим значение средней арифметической
|
| 5.Для вычисления по некоторым более сложным формулам требуются построения дополнительных рядов по исходному. Поэтому исходные данные мы ввели в столбец. |
|
|
Задание № 2
В Excel создадим компьютерную модель решения задачи.
Компьютерная модель = ячейки данных + ячейки вычислений + ячейки результатов
Задание № 3
В Excel создадим компьютерную модель решения задачи.
Компьютерная модель = ячейки данных + ячейки вычислений + ячейки результатов
Задание № 4
Провести сравнение статистических характеристик, полученных тремя разными способами в Excel (по арифметическим формулам, по формулам, встроенным в Excel, с помощью пакета). Привести доказательство письменному выводу
Эксцесс

Асимметрия

13. Стандартное отклонение Öd2
14. Среднее абсолютное отклонение:
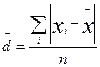 .
.
15. Коэффициент вариации – отношение среднего квадратического отклонения к средней арифметической, выраженное в процентах:
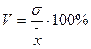 .
.
Медиана
Медиана разбивает выборку на две равные части. Пятьдесят процентов наблюдений лежит ниже медианы, пятьдесят процентов — выше медианы. Если значение медианы существенно отличается от среднего, то распределение скошено (более подробно см. главу Элементарные понятия).
Мода
Мода — это максимально часто встречающееся значение в выборке. Частота встречаемости также отображается. Если имеется несколько значений с максимальной частотой, то распределение мулътимодалъно. Если каждое значение встречается лишь одни раз, программа делает запись: моды нет (см. электронную таблицу с результатами).
|
|
Геометрическое среднее
Геометрическое среднее — это произведение всех значений переменной, возведенное в степень 1/n (единица, деленная на число наблюдений). Геометрическое среднее полезно, например, если шкала измерений нелинейная.
STATISTICA вычисляет геометрическое среднее с помощью логарифмического преобразования: log(геометрическое среднее) = {a[log(xi)]}/n, где xi— i-е значение, n — число наблюдений. Если переменная содержит отрицательные значения или нуль (0), геометрическое среднее вычислить нельзя.
Гармоническое среднее
Гармоническое среднее иногда используют для усреднения частот. Гармоническое среднее вычисляется по формуле: ГС = n/S(1/хi) где ГС — гармоническое среднее, n — число наблюдений, хi — значение наблюдения с номером i. Если переменная содержит нуль (0), гармоническое среднее вычислить нельзя.
Размах
Размах переменной является показателем изменчивости, вычисляется как максимум минус минимум.
Квартильный размах
Квартальный размах, по определению, равен: верхняя квартиль минус нижняя квартиль (75% процентиль минус 25% процентиль). Так как 75% процентиль (верхняя квартиль) — это значение, слева от которого находятся 75% наблюдений, а 25% процентиль (нижняя квартиль) — это значение, слева от которого находится 25% наблюдении, то квартильный размах представляет собой интервал вокруг медианы, который содержит 50% наблюдений (значений переменной).
Интервал значений признака, содержащий центральные 50% наблюдений выборки, т.е. интервал между 25-м и 75-м процентилями.
Квартильный размах используется вместе с медианой (вместо 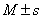 ) для описания данных, имеющих распределение, отличное от нормального.
) для описания данных, имеющих распределение, отличное от нормального.
Асимметрия
Асимметрия — это характеристика формы распределения. Распределение скошено влево, если значение асимметрии отрицательно. Распределение скошено вправо, если асимметрия положительна. Асимметрия стандартного нормального распределения равна 0. Асимметрия связана с третьим моментом и определяется как: асимметрия = n × М3/[(n-1) × (n-2) × s3], где М3 равно: 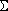 <="" img=""> (хi-xсреднееx)3, s3— стандартное отклонение, возведенное в третью степень, n — число наблюдений (СКОС).
<="" img=""> (хi-xсреднееx)3, s3— стандартное отклонение, возведенное в третью степень, n — число наблюдений (СКОС).
|
|
Эксцесс
Эксцесс — это характеристика формы распределения, а именно мера остроты его пика (относительно нормального распределения, эксцесс которого равен 0). Как правило, распределения с более острым пиком, чем у нормального, имеют положительный эксцесс; распределения, пик которых менее острый, чем пик нормального распределения, имеют отрицательный эксцесс. Эксцесс связан с четвертым моментом и определяется формулой:
эксцесс = [n × (n+1) × М4- 3 × М2× М2× (n-1)]/[(n-1) × (n-2) × (n-3) × s4], где Mj равно: <="" img=""> (х-хсреднееx, s4— стандартное отклонение в четвертой степени, n — число наблюдений (ЭКСЦЕСС).
Стандартная ошибка
Для вычисления стандартной ошибки среднего, используйте одну из следующих формул
= СТАНДАРТНОЕ ОТКЛОНЕНИЕ / КВАДРАТНЫЙ КОРЕНЬ РАЗМЕРА ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ
–ИЛИ-
= STDEV (диапазон значений) и SQRT (Номер)
где:
Статистические функции Excel
|
|
|
|
Лабораторная работа № 3
Основные характеристики случайной выборки
(подсчет в Excel)
Если набор данных содержит информацию о каждом элементе группы или обо всех возможных измерениях, говорят, что такой набор данных представляет генеральную совокупность. Если измерения проводятся на некотором подмножестве генеральной совокупности или выполняется лишь часть всех возможных измерений, такой набор данных называется выборкой. Метод, когда для описания свойств генеральной совокупности используется выборка, называется методом выборочного обследования. При этом методе используют представительную выборку. Обычно в ее качестве применяется случайная выборка. Для характеристики выборки подсчитывают статистические характеристики
Экспериментально получены измерения некоторой величины
Задание № 1
В Excel создадим компьютерную модель решения задачи.
Компьютерная модель = ячейки данных + ячейки вычислений + ячейки результатов
|
|
|

Эмиссия газов от очистных сооружений канализации: В последние годы внимание мирового сообщества сосредоточено на экологических проблемах...

Биохимия спиртового брожения: Основу технологии получения пива составляет спиртовое брожение, - при котором сахар превращается...

Особенности сооружения опор в сложных условиях: Сооружение ВЛ в районах с суровыми климатическими и тяжелыми геологическими условиями...

Адаптации растений и животных к жизни в горах: Большое значение для жизни организмов в горах имеют степень расчленения, крутизна и экспозиционные различия склонов...
© cyberpedia.su 2017-2024 - Не является автором материалов. Исключительное право сохранено за автором текста.
Если вы не хотите, чтобы данный материал был у нас на сайте, перейдите по ссылке: Нарушение авторских прав. Мы поможем в написании вашей работы!