Под глубиной диагностирования будем понимать среднее количество состояний, с точностью до которых может быть локализован дефект на основании количества информации I(S,Y), доставляемых диагностическим экспериментом.
Очевидно, что глубина диагностирования растёт с увеличением количества информации I(S,Y) или с увеличением коэффициента K.
Задача максимизации глубины диагностирования сводится к выбору из допустимого множества точек контроля такого подмножества заданного размера, при котором диагностический эксперимент доставляет максимальное количество информации о системе.
С целью получения конструктивных решений предлагается следующий эвристический алгоритм последовательного выбора точек контроля.
На первом шаге выбирается точка контроля, которая доставляет максимальное количество информации о системе.
На каждом из последующих шагов выбирается та точка контроля, которая доставляет максимальное дополнительное количество информации.
Процедура выбора точек контроля заканчивается после того, как будет выбрано заданное число точек контроля.
Аналогично решается задача выбора минимального множества точек контроля, которое обеспечивает заданную глубину диагностирования. В этом случае процедура выбора точек контроля заканчивается, когда количество снимаемой с них информации обеспечивает заданную глубину диагностирования.
Идея алгоритма очень проста, эффективность его реализации зависит от методики расчёта коэффициента K. Непосредственный (или точный) метод расчёта коэффициента K, очевидно, становится трудоёмким для систем большей размерности. Можно предложить, например, не рассматривать те состояния, которые маловероятны и вносят ²малый² вклад в соответствующую вероятность p(yi), т.е. рассматривать лишь наиболее вероятные состояния из подмножеств 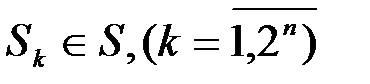 . Таким образом, на вычисление коэффициента затрачивается значительно меньше машинного времени при незначительной потере точности вычислений.
. Таким образом, на вычисление коэффициента затрачивается значительно меньше машинного времени при незначительной потере точности вычислений.
КЛАССИФИКАЦИЯ МНОГОМЕРНЫХ ДАННЫХ
Постановка задачи.
В природе практически все объекты (физические, биологические, технические, социальные) описываются множеством физических величин или параметров (переменных), которые в совокупности образуют модель объекта как структурированный состав, т.е. систему.
Анализ свойств модели на основе системного подхода и экспериментальная проверка результатов анализа являются основной целью современных научных исследований. Объект (образец) обнаруживает себя во вне как совокупность наблюдаемых переменных, значения которых интерпретируются как свойства объекта, его состояния.
Кроме непосредственно наблюдаемых переменных существуют скрытые (латентные) переменные, непосредственное наблюдение и измерение которых не представляется возможным, но которые существенно влияют на состояние системы и могут быть использованы в исследованиях как индикаторы её состояния. Например, скрытой переменной является здоровье человека, непосредственное измерение которого не представляется возможным. Тем не менее врачи выносят решение о его состоянии по совокупности результатов анализов и значений других наблюдаемых переменных на основе личного опыта.
Скрытые параметры являются интересующими нас структурными свойствами системы, которые представляют собой различного рода взаимодействия (отношения) компонентов (переменных) системы.
Скрытые переменные (параметры) системы могут иметь иерархическую организацию, в которой должна существовать количественная связь между совокупностью непосредственно измеряемых переменных и переменными более высокого уровня, т. е. такой скрытой переменной, которая нас интересует. Установление этих связей и выбор самих скрытых переменных является основной целью анализа системы, при этом анализ должен быть не формальным, а целесообразным, в контексте решаемой задачи. Наиболее интересным с практической точки зрения является обобщающий скрытый параметр (свойство), который описывает состояние системы как некоторой целостности, например, здоровье человека. В общем виде эту задачу не удается решить, но тем не менее здоровье человека можно оценить по некоторому промежуточному скрытому параметру (переменной) в соответствующей иерархии параметров. В качестве другого примера скрытого параметра можно выбрать код, который в форме определенной структуры присутствует в закодированном тексте, но непосредственное наблюдение кода в тексте не представляется возможным.
Таким образом, состояние объекта описывается значениями измеряемых переменных ξ = (ξ1, ξ2, …, ξn), последовательность которых можно рассматривать как вектор в n -мерном евклидовом пространстве, пространстве переменных. В литературе переменные называют часто компонентами, поскольку в совокупности они образуют систему – модель объекта. Обнаружить структурные закономерности (свойства) системы т.е. различного рода зависимости между компонентами, по единственному состоянию системы не представляется возможным, поскольку зависимость отражает характер совместного изменения значений переменных. Для решения поставленной задачи необходимо располагать по крайней мере, множеством состояний, каждое из которых изображается точкой в n -мерном пространстве переменных, в совокупности образуя облако. Все множество многомерных состояний называют многомерными данными. Многомерные данные могут описывать как состояния одного объекта, в котором он может находиться в разные моменты времени, так и состояния разных объектов (образцов), принадлежащих одному и тому же виду, например, множество текстов (образцов), записанных в одном и том же коде (виде). Состояния здоровья людей, образующих некоторое подмножество (репрезентативную выборку) всех людей, так же можно представить в виде многомерных данных, при этом состояние отдельного человека описывается совокупностью значений, выбранных переменных ξ = (ξ1, ξ2, …, ξn). Переменные, которые описывают состояние объекта, могут быть как детерминированными так и случайными величинами в зависимости от их физической природы и содержания решаемой задачи. В зависимости от этого методы обработки данных можно разделить на детерминированные и статистические. Случайность возникает, когда объект случайным образом выбирается из некоторого множества объектов (образцов) или один объект случайным образом может оказаться в одном из возможных состояний.
Многомерные данные являются априорными данными, на основании которых в результате их соответствующей обработки делается оценка интересующего нас свойства объекта (скрытого параметра, переменной), например, здоров человек или болен.
Может быть неограниченное количество задач, связанных с обработкой многомерных данных, тем не менее, можно выделить наиболее важные, актуальные, чаще всего встречающиеся задачи:
1. Кластеризация и классификация состояний объекта.
Кластеризация – это разбиение многомерных данных на подмножества (кластеры) состояний (образцов), обладающих некоторым общим свойством. Например, многомерные данные, описывающие состояния здоровья людей, можно разделить на подмножества здоровых и больных людей. Алгоритм кластеризации не требует какой либо информации кроме той, которая содержится в структуре многомерных данных, он работает без учителя. Кластеризация основана на сравнении состояний (образцов) между собой на основе выбранной метрики, которая в сущности есть скрытый параметр (ненаблюдаемая переменная), которая вычисляется как функция наблюдаемых переменных. В зависимости от вида выбранной метрики результаты кластеризации могут получиться разными. Метрика выбирается экспериментально.
При классификации разбиение многомерных данных на подмножества задается априорно. Задача классификации заключается в определении какому из подмножеств принадлежит наблюдаемое состояние (образец).
2. Обнаружение и исследование зависимостей (закономерностей) между переменными, в том числе, и скрытыми, которые позволяют эффективно решить поставленную задачу. В зависимости от содержания задачи модели, используемые при решении задачи и методы ее решения, могут быть как детерминированными так и статистическими..
Одним из способов выбора, наиболее информативного для решения поставленной задачи, параметра (свойства) является метод проекций или метод главных компонент. Суть его заключается в вычислении проекций векторов, изображающих соответствующие состояния объекта (образцов), на специально выбранное направление в пространстве многомерных переменных. С выбранным направлением будет связана некоторая скрытая переменная, компонента, которая используется в качестве метрики в пространстве переменных.
Рассмотрим пример скрытого параметра (свойства). Пусть некоторый объект описывается вероятностной моделью, параметрами которой являются вероятности p1,…,pn, а результатами наблюдения статистические оценки их значений p1= ξ1,…,pn= ξn (крышки или Звездочки) Априори (заранее) мы знаем, что сумма значений всех вероятностей равна единице (сумма), но непосредственные наблюдения оценок этих вероятностей не доставляют информацию об этом свойстве и поэтому оно является скрытым параметром. Если бы мы этого свойства не знали, то выявить (угадать) его можно, используя метод проекций, при соответствующем выборе направляющего вектора. Если в качестве направляющего вектора выбрать вектор с координатами, равными единице, то скалярное произведение вектора ξ= (ξ1, ξ2, …, ξn) и направляющего вектора, значение которого равно,будет оценкой значения скрытого параметра, равного единице. В общем случае выбор направляющего вектора является отдельной проблемой, если априори мы не располагаем какими либо сведениями о свойствах объекта кроме значений наблюдаемых параметров.
Рассмотрим пример классификации наблюдаемого состояния биоценоза на основе многомерных данных с вероятностным описанием его состояний.
5.2. Классификация состояний биоценоза. [3]
В настоящее время актуальным является внедрение информационных технологий в процесс научных и прикладных исследований состояний биоценоза с целью повышения их эффективности. Биоценоз - это системно-организованная совокупность растений, животных или микроорганизмов, обитающих в определённой среде, на состояние которого можно влиять через среду и тем самым управлять развитием биоценоза или его уничтожением. Частным случаем биоценоза является микробиота желудочно-кишечного тракта (ЖКТ) человека. Это чувствительная индикаторная система, которая своими количественными и качественными изменениями реагирует на любые нарушения состояния здоровья человека. Правильная трактовка результата бактериологического исследования имеет исключительное значение в решении вопроса о природе кишечного заболевания и соответствующих методах лечения.
До настоящего времени в рамках научного исследования для этой цели были разработаны методы, основанные на сравнении результатов бактериологических исследований с эталонной группой здоровых людей, выбранных с помощью экспертных оценок, а также исследованы возможности применения нейросетевых технологий.
Цель данной работы заключается в разработке алгоритма классификации состояний микрофлоры ЖКТ пациента на основе статистического анализа априорных многомерных данных [2,8,9,10], полученных в результате бактериологических исследований качественного и количественного состава микрофлоры ЖКТ больных и здоровых пациентов.
Теоретический анализ
Базовая модель, описывающая состояния ЖКТ, построена на исходных данных, которые представляют собой результаты бактериологических исследований состояния ЖКТ отдельно для больных и здоровых людей. Результат исследования состояния ЖКТ отдельного пациента представлен в виде вектора ξ= (ξ1, ξ2, …, ξn) в n-мерном евклидовом пространстве, координатами которого являются скалярные величины, каждая из которых равна количеству микроорганизмов данного вида. Таким образом, базовая модель представляет собой n-мерное пространство признаков, которые априорно разделены на два класса, соответствующие здоровым и больным пациентам. Проблема заключается в принятии оптимального решения, какому из классов принадлежат результаты анализа пациента.
В общем случае количество микроорганизмов каждого из видов является случайной величиной с произвольным неизвестным законом распределения, что делает невозможным непосредственное использование классических методов оптимального статистического синтеза правил принятия решения о состоянии микробиоты. В работе предлагается перейти от случайной векторной величины к ее проекции x на специально выбранное направление, определяемое единичным вектором α. Проекция x оказалась достаточно информативной для решения проблемы классификации микробиоценоза, если вектор α параллелен прямой, проходящей через две точки n -мерного пространства, которые изображают математические ожидания многомерных случайных величин соответственно для «здоровых» и «больных» людей. Проекция x на данное направление вычисляется как скалярное произведение векторов ξ = (ξ1, ξ2, …, ξn) и α = (α1, α2, …, αn) [3]
[]
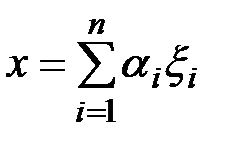 , (5.1)
, (5.1)
где α1, α2, …, αn – косинусы углов, которые единичный вектор α образует с осями координат. Поскольку проекция x является весовой суммой случайных величин, то на основании центральной предельной теоремы теории вероятностей можно предположить, что ее закон распределения будет близок к гауссову. В этом случае законы распределения для здоровых и больных людей будут практически гауссовыми, и различаться будут только математическим ожиданием и дисперсией. В работе установлено, что гипотеза о гауссовом законе распределения по критерию согласия χ2 не противоречит опытным данным с уровнем значимости 0,05 и поэтому ее можно считать правдоподобной.
Гистограммы соответственно для здоровых и больных пациентов представлены на рис.5.1.
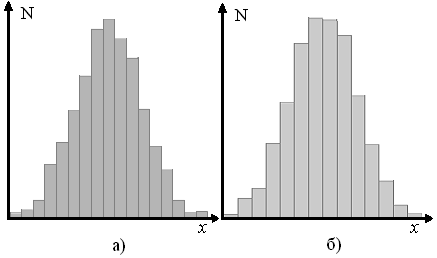
Рис. 5.1. Гистограмма для здоровых (а) и больных (б) пациентов. x – значение проекции, N – относительная частота значения проекции x
Методика
Построение правила принятия решения о состоянии здоровья пациента начинается с формирования двух классов в пространстве признаков для здоровых и больных пациентов на основании анализа количественного и качественного состава микрофлоры ЖКТ и экспертных оценок. В каждом из классов по экспериментальным данным вычисляются оценки математического ожидания и дисперсии проекции случайного вектора ξ. Для решения поставленной задачи диагностирования используется критерий отношения правдоподобия L, который обеспечивает минимум средней вероятности ошибки. Пороговое значение x0, которое делит пространство на критическую и допустимую области (рис.5.2) при равенстве априорных вероятностей того здоров пациент или болен вычисляется при L =1 и σ1 ≠ σ2 по формуле [2]
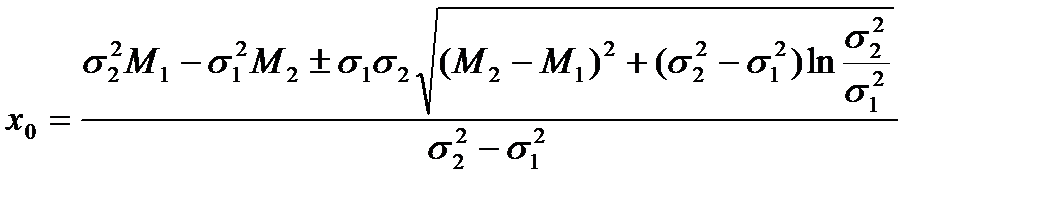 . (5.2)
. (5.2)
где M1 и M2 – математические ожидания проекций соответственно для групп здоровых и больных пациентов, σ1 и σ2 – среднеквадратические отклонения.
При σ1 = σ2 пороговое значение вычисляется по формуле х0 =(M1 + M2)/2.
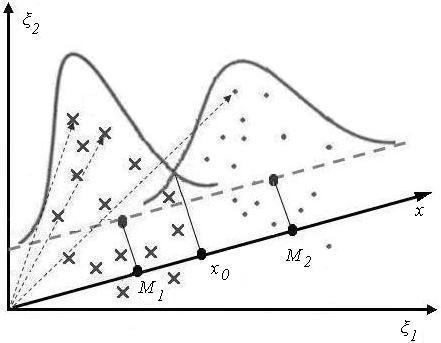
Рис. 5.2. Визуализация метода проекций
Получив результаты бактериологического анализа для диагностируемого пациента в виде многомерного вектора, вычисляется проекция x этого вектора и, в зависимости от взаимного расположения получившейся проекции и заранее вычисленного значения величины х0, принимается решение о том, болен пациент с данным результатом анализа или нет. Если значение проекции окажется очень близким к значению порога, то целесообразнее отказаться от указанных решений и отнести диагностируемого пациента к группе риска. С этой целью вводится некоторая окрестность (w1, w2) точки х0. Пациент относится к группе риска, если значение проекции попало в этот интервал (рис. 5.3).
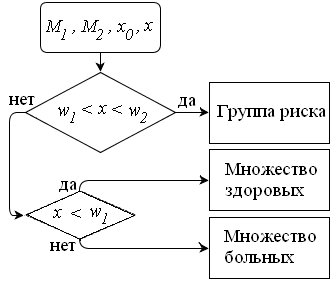
Рис. 5.3. Блок-схема алгоритма классификации
Результаты эксперимента
В качестве экспериментальных данных были отобраны и систематизированы результаты бактериологических исследований микрофлоры ЖКТ 2576 человек с n =29. Выполнен сравнительный анализ предложенного метода с методом, использующим нейросетевые технологии. Используя нейросетевые технологии, не удалось провести классификацию состояний биоценозов для всех возрастных групп, используя одну конкретную нейронную сеть. Поскольку состав микрофлоры у людей различных возрастов имеет существенные качественные и количественные различия, было принято решение производить обучение нейронных сетей для некоторых возрастных групп отдельно (таблица 5.1).
Таблица 5.1 – Результаты сравнительных экспериментов
| возраст
метод
| 0-23ч
| 1-6сут
| 7-29сут
| 1-11мес
| 1-6л
| 7-17л
| 18-59л
| 60л и >
|
| Сеть Кохонена
| -
| -
| +
| +
| +
| +
| +
| +
|
| Сеть Ворда
| +
| +
| +
| -
| +
| +
| +
| +
|
| Метод проекций
| +
| +
| +
| +
| +
| +
| +
| +
|
Плюс в таблице обозначает работоспособность выбранного метода, а минус – невозможность отличить «норму» от «патологии». Лучшие результаты показал предлагаемый в работе метод проекций. Классификация с использованием сети Ворда, которая показала лучшие результаты среди нейронных сетей, обеспечило в среднем 85% правильных решений, а предлагаемый метод проекций - 96%.
Условные вероятности ошибок, правильного принятия решения и отнесение пациента к группе риска представлены в виде вероятностной диаграммы (рис. 5.4).
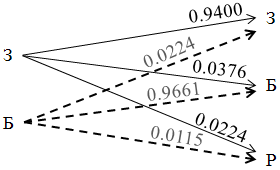
Рис. 5.4. Вероятностная диаграмма, З-здоровые, Б-больные, Р-риск
Таким образом, практические результаты подтвердили эффективность разработанного метода и достоверность теоретических выводов.
ЗАКЛЮЧЕНИЕ
В учебном пособии рассмотрены современные методы обработки многомерных данных с целью выявления скрытых параметров, которые характеризуют совокупность многомерных данных как некоторую целостность. Приведен обзор задач и методов их решения, которые сформировались к настоящему времени. Подробно рассмотрен метод проекций на примере классификации состояний биоценоза.
В качестве инструментария используются классические методы теории вероятностей, теории информации и математической статистики, которые подробно изложены в соответствующих разделах.
Список литературы
1. Боровков А.А. Математическая статистика: оценка параметров, проверка гипотез;, 2007. - 472 c.
2. Горелик А.А. Методы распознавания/ А.А. Горелик, В.А. Скрипкин — М.: Высшая школа, 2010. - 220с.
3. Федоткин М.А. Основы прикладной теории вероятностей и статистики; М.: Высшая школа, 2008. – 368с.
4. Вентцель Е.С.Теория вероятностей: учебник/Е. С. Вентцель. - 10-е изд.,стер. М.: Высш.шк., 2006.
5. Гмурман В.Е.Руководство к решению задач по теории вероятностей и математической статистике: учеб.пособие/В.Е. Гмурман /-9-е изд., стер М.: Высш.шк., 2004.
6. Кудряшов Б.Д. Теория информации/Б.Д. Кудряшов. – СПб.: Питер, 2009. – 320с.
7. Гмурман В.Е. Теория вероятностей и математическая статистика. Базовый курс/ В.Е. Гмурман. – М.: Юрайт, 2013. – 480с.
8. Kim H.Esbensen. Multivariate Date Analysis In Practice. 5 th Edition.1994-2002 CAMO Process AS, Oslo, Norway.
9. Эсбенсен К. Анализ многомерных данных. Избранные главы/ Пер. с англ. С.В. Кучерявского. Под ред. О.Е. Родионовой.- Черноголовка: Изд-во ИПХФ РАН, 2005. – 160 с.
10. Большаков А.А. Методы обработки многомерных данных и временных рядов/А.А. Большаков, Р.Н. Каримов. – М.: Горячая Линия – Телеком, 2007. – 520с.
11. Барсегян А.А. Методы и модели анализа данных: OLAP и DATA Mining/А.А. Барсегян, М.С. Куприянов, В.В. Степаненко, И.И. Холод. – СПб.: БХВ-Петербург, 2004. – 336с.
[1] Функция распределения вероятностей связывает между собой два понятия теории вероятностей: случайное событие и случайная величина – численное значение результатов опыта (эксперимента).
[2] Если плотность распределения вероятностей всюду на интервале [a,b] равна нулю, то и вероятность попадания реализации случайной величины на этот интервал тоже будет равна нулю.
[3] Данный раздел подготовлен совместно с С.А. Зеленцовым






